 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Understanding of Context Utilization in Code Intelligence
Apr 11, 2025Code intelligence is an emerging domain in software engineering, aiming to improve the effectiveness and efficiency of various code-related tasks. Recent research suggests that incorporating contextual information beyond the basic original task inputs (i.e., source code) can substantially enhance model performance. Such contextual signals may be obtained directly or indirectly from sources such as API documentation or intermediate representations like abstract syntax trees can significantly improve the effectiveness of code intelligence. Despite growing academic interest, there is a lack of systematic analysis of context in code intelligence. To address this gap, we conduct an extensive literature review of 146 relevant studies published between September 2007 and August 2024. Our investigation yields four main contributions. (1) A quantitative analysis of the research landscape, including publication trends, venues, and the explored domains; (2) A novel taxonomy of context types used in code intelligence; (3) A task-oriented analysis investigating context integration strategies across diverse code intelligence tasks; (4) A critical evaluation of evaluation methodologies for context-aware methods. Based on these findings, we identify fundamental challenges in context utilization in current code intelligence systems and propose a research roadmap that outlines key opportunities for future research.
CodeV: Issue Resolving with Visual Data
Dec 23, 2024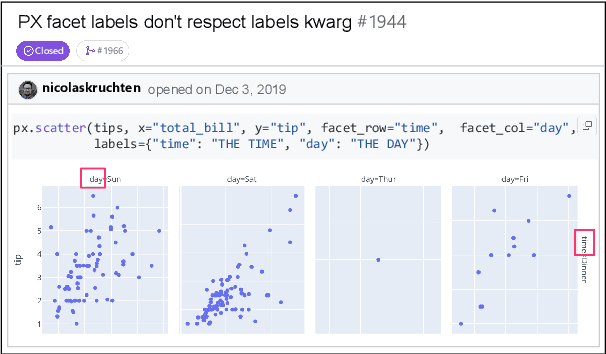
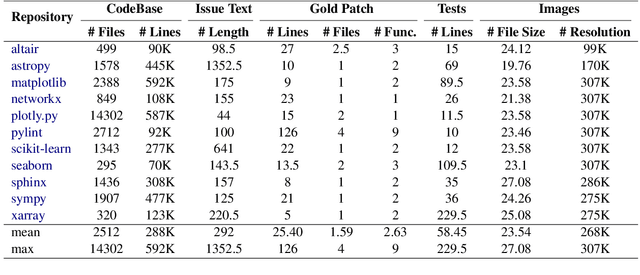


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
Agents in Software Engineering: Survey, Landscape, and Vision
Sep 13, 2024



In recent years, Large Language Models (LLMs) have achieved remarkable success and have been widely used in various downstream tasks, especially in the tasks of the software engineering (SE) field. We find that many studies combining LLMs with SE have employed the concept of agents either explicitly or implicitly. However, there is a lack of an in-depth survey to sort out the development context of existing works, analyze how existing works combine the LLM-based agent technologies to optimize various tasks, and clarify the framework of LLM-based agents in SE. In this paper, we conduct the first survey of the studies on combining LLM-based agents with SE and present a framework of LLM-based agents in SE which includes three key modules: perception, memory, and action. We also summarize the current challenges in combining the two fields and propose future opportunities in response to existing challenges. We maintain a GitHub repository of the related papers at: https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024



GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Can Programming Languages Boost Each Other via Instruction Tuning?
Sep 03, 2023



When human programmers have mastered a programming language, it would be easier when they learn a new programming language. In this report, we focus on exploring whether programming languages can boost each other during the instruction fine-tuning phase of code large language models. We conduct extensive experiments of 8 popular programming languages (Python, JavaScript, TypeScript, C, C++, Java, Go, HTML) on StarCoder. Results demonstrate that programming languages can significantly improve each other. For example, CodeM-Python 15B trained on Python is able to increase Java by an absolute 17.95% pass@1 on HumanEval-X. More surprisingly, we found that CodeM-HTML 7B trained on the HTML corpus can improve Java by an absolute 15.24% pass@1. Our training data is released at https://github.com/NL2Code/CodeM.
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
Jul 27, 2023


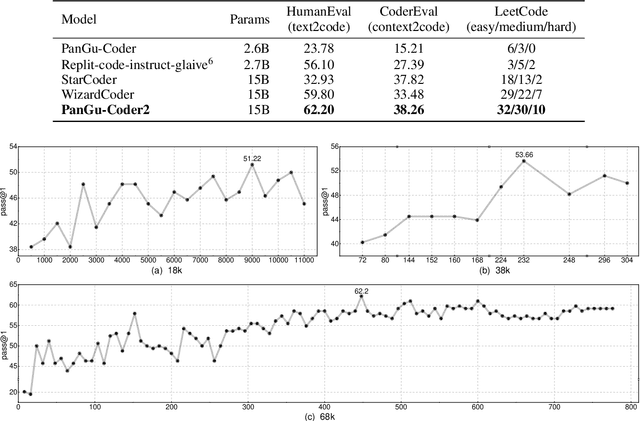
Large Language Models for Code (Code LLM) are flourishing. New and powerful models are released on a weekly basis, demonstrating remarkable performance on the code generation task. Various approaches have been proposed to boost the code generation performance of pre-trained Code LLMs, such as supervised fine-tuning, instruction tuning, reinforcement learning, etc. In this paper, we propose a novel RRTF (Rank Responses to align Test&Teacher Feedback) framework, which can effectively and efficiently boost pre-trained large language models for code generation. Under this framework, we present PanGu-Coder2, which achieves 62.20% pass@1 on the OpenAI HumanEval benchmark. Furthermore, through an extensive evaluation on CoderEval and LeetCode benchmarks, we show that PanGu-Coder2 consistently outperforms all previous Code LLMs.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
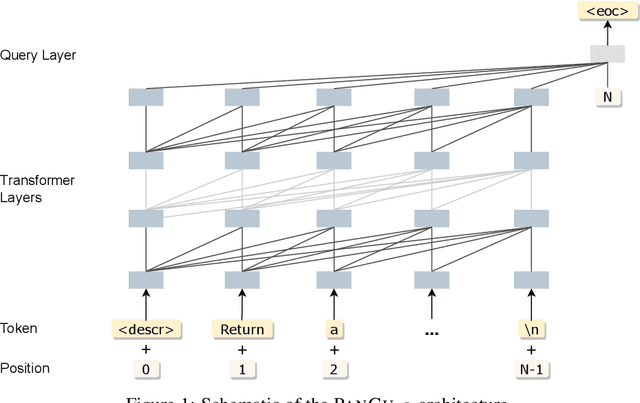
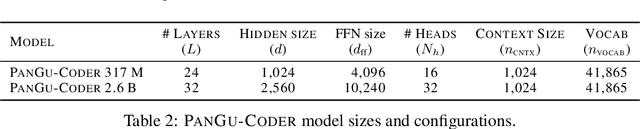
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.