 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneRec Technical Report
Jun 16, 2025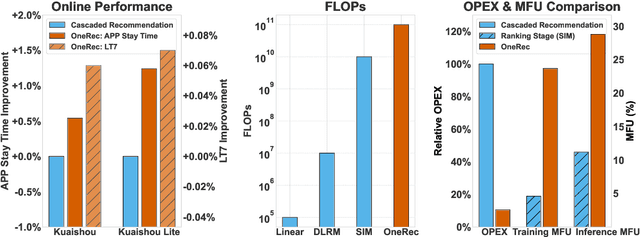

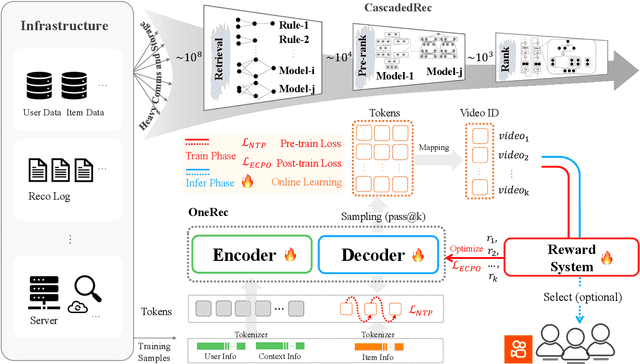
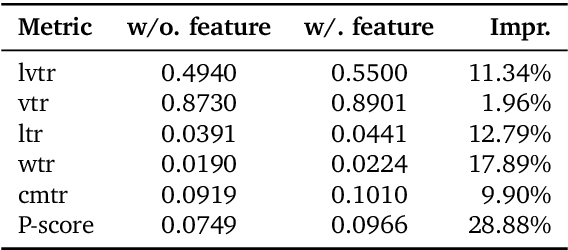
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025



Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.
Segment Any Motion in Videos
Mar 28, 2025Moving object segmentation is a crucial task for achieving a high-level understanding of visual scenes and has numerous downstream applications. Humans can effortlessly segment moving objects in videos. Previous work has largely relied on optical flow to provide motion cues; however, this approach often results in imperfect predictions due to challenges such as partial motion, complex deformations, motion blur and background distractions. We propose a novel approach for moving object segmentation that combines long-range trajectory motion cues with DINO-based semantic features and leverages SAM2 for pixel-level mask densification through an iterative prompting strategy. Our model employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support. Extensive testing on diverse datasets demonstrates state-of-the-art performance, excelling in challenging scenarios and fine-grained segmentation of multiple objects. Our code is available at https://motion-seg.github.io/.
Continuous 3D Perception Model with Persistent State
Jan 21, 2025We present a unified framework capable of solving a broad range of 3D tasks. Our approach features a stateful recurrent model that continuously updates its state representation with each new observation. Given a stream of images, this evolving state can be used to generate metric-scale pointmaps (per-pixel 3D points) for each new input in an online fashion. These pointmaps reside within a common coordinate system, and can be accumulated into a coherent, dense scene reconstruction that updates as new images arrive. Our model, called CUT3R (Continuous Updating Transformer for 3D Reconstruction), captures rich priors of real-world scenes: not only can it predict accurate pointmaps from image observations, but it can also infer unseen regions of the scene by probing at virtual, unobserved views. Our method is simple yet highly flexible, naturally accepting varying lengths of images that may be either video streams or unordered photo collections, containing both static and dynamic content. We evaluate our method on various 3D/4D tasks and demonstrate competitive or state-of-the-art performance in each. Project Page: https://cut3r.github.io/
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/
Reverse Attitude Statistics Based Star Map Identification Method
Oct 31, 2024



The star tracker is generally affected by the atmospheric background light and the aerodynamic environment when working in near space, which results in missing stars or false stars. Moreover, high-speed maneuvering may cause star trailing, which reduces the accuracy of the star position. To address the challenges for starmap identification, a reverse attitude statistics based method is proposed to handle position noise, false stars, and missing stars. Conversely to existing methods which match before solving for attitude, this method introduces attitude solving into the matching process, and obtains the final match and the correct attitude simultaneously by frequency statistics. Firstly, based on stable angular distance features, the initial matching is obtained by utilizing spatial hash indexing. Then, the dual-vector attitude determination is introduced to calculate potential attitude. Finally, the star pairs are accurately matched by applying a frequency statistics filtering method. In addition, Bayesian optimization is employed to find optimal parameters under the impact of noises, which is able to enhance the algorithm performance further. In this work, the proposed method is validated in simulation, field test and on-orbit experiment. Compared with the state-of-the-art, the identification rate is improved by more than 14.3%, and the solving time is reduced by over 28.5%.
Topology-Aware Graph Augmentation for Predicting Clinical Trajectories in Neurocognitive Disorders
Oct 31, 2024



Brain networks/graphs derived from resting-state functional MRI (fMRI) help study underlying pathophysiology of neurocognitive disorders by measuring neuronal activities in the brain. Some studies utilize learning-based methods for brain network analysis, but typically suffer from low model generalizability caused by scarce labeled fMRI data. As a notable self-supervised strategy, graph contrastive learning helps leverage auxiliary unlabeled data. But existing methods generally arbitrarily perturb graph nodes/edges to generate augmented graphs, without considering essential topology information of brain networks. To this end, we propose a topology-aware graph augmentation (TGA) framework, comprising a pretext model to train a generalizable encoder on large-scale unlabeled fMRI cohorts and a task-specific model to perform downstream tasks on a small target dataset. In the pretext model, we design two novel topology-aware graph augmentation strategies: (1) hub-preserving node dropping that prioritizes preserving brain hub regions according to node importance, and (2) weight-dependent edge removing that focuses on keeping important functional connectivities based on edge weights. Experiments on 1, 688 fMRI scans suggest that TGA outperforms several state-of-the-art methods.
Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction
Sep 26, 2024



Humans can learn to manipulate new objects by simply watching others; providing robots with the ability to learn from such demonstrations would enable a natural interface specifying new behaviors. This work develops Robot See Robot Do (RSRD), a method for imitating articulated object manipulation from a single monocular RGB human demonstration given a single static multi-view object scan. We first propose 4D Differentiable Part Models (4D-DPM), a method for recovering 3D part motion from a monocular video with differentiable rendering. This analysis-by-synthesis approach uses part-centric feature fields in an iterative optimization which enables the use of geometric regularizers to recover 3D motions from only a single video. Given this 4D reconstruction, the robot replicates object trajectories by planning bimanual arm motions that induce the demonstrated object part motion. By representing demonstrations as part-centric trajectories, RSRD focuses on replicating the demonstration's intended behavior while considering the robot's own morphological limits, rather than attempting to reproduce the hand's motion. We evaluate 4D-DPM's 3D tracking accuracy on ground truth annotated 3D part trajectories and RSRD's physical execution performance on 9 objects across 10 trials each on a bimanual YuMi robot. Each phase of RSRD achieves an average of 87% success rate, for a total end-to-end success rate of 60% across 90 trials. Notably, this is accomplished using only feature fields distilled from large pretrained vision models -- without any task-specific training, fine-tuning, dataset collection, or annotation. Project page: https://robot-see-robot-do.github.io
Shape of Motion: 4D Reconstruction from a Single Video
Jul 18, 2024



Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/
Augmentation-based Unsupervised Cross-Domain Functional MRI Adaptation for Major Depressive Disorder Identification
May 31, 2024



Major depressive disorder (MDD) is a common mental disorder that typically affects a person's mood, cognition, behavior, and physical health. Resting-state functional magnetic resonance imaging (rs-fMRI) data are widely used for computer-aided diagnosis of MDD. While multi-site fMRI data can provide more data for training reliable diagnostic models, significant cross-site data heterogeneity would result in poor model generalizability. Many domain adaptation methods are designed to reduce the distributional differences between sites to some extent, but usually ignore overfitting problem of the model on the source domain. Intuitively, target data augmentation can alleviate the overfitting problem by forcing the model to learn more generalized features and reduce the dependence on source domain data. In this work, we propose a new augmentation-based unsupervised cross-domain fMRI adaptation (AUFA) framework for automatic diagnosis of MDD. The AUFA consists of 1) a graph representation learning module for extracting rs-fMRI features with spatial attention, 2) a domain adaptation module for feature alignment between source and target data, 3) an augmentation-based self-optimization module for alleviating model overfitting on the source domain, and 4) a classification module. Experimental results on 1,089 subjects suggest that AUFA outperforms several state-of-the-art methods in MDD identification. Our approach not only reduces data heterogeneity between different sites, but also localizes disease-related functional connectivity abnormalities and provides interpretability for the model.