 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeLens: An Interactive Tool for Visualizing Code Representations
Jul 27, 2023Representing source code in a generic input format is crucial to automate software engineering tasks, e.g., applying machine learning algorithms to extract information. Visualizing code representations can further enable human experts to gain an intuitive insight into the code. Unfortunately, as of today, there is no universal tool that can simultaneously visualise different types of code representations. In this paper, we introduce a tool, CodeLens, which provides a visual interaction environment that supports various representation methods and helps developers understand and explore them. CodeLens is designed to support multiple programming languages, such as Java, Python, and JavaScript, and four types of code representations, including sequence of tokens, abstract syntax tree (AST), data flow graph (DFG), and control flow graph (CFG). By using CodeLens, developers can quickly visualize the specific code representation and also obtain the represented inputs for models of code. The Web-based interface of CodeLens is available at http://www.codelens.org. The demonstration video can be found at http://www.codelens.org/demo.
The Scope of ChatGPT in Software Engineering: A Thorough Investigation
May 20, 2023ChatGPT demonstrates immense potential to transform software engineering (SE) by exhibiting outstanding performance in tasks such as code and document generation. However, the high reliability and risk control requirements of SE make the lack of interpretability for ChatGPT a concern. To address this issue, we carried out a study evaluating ChatGPT's capabilities and limitations in SE. We broke down the abilities needed for AI models to tackle SE tasks into three categories: 1) syntax understanding, 2) static behavior understanding, and 3) dynamic behavior understanding. Our investigation focused on ChatGPT's ability to comprehend code syntax and semantic structures, including abstract syntax trees (AST), control flow graphs (CFG), and call graphs (CG). We assessed ChatGPT's performance on cross-language tasks involving C, Java, Python, and Solidity. Our findings revealed that while ChatGPT excels at understanding code syntax (AST), it struggles with comprehending code semantics, particularly dynamic semantics. We conclude that ChatGPT possesses capabilities akin to an Abstract Syntax Tree (AST) parser, demonstrating initial competencies in static code analysis. Additionally, our study highlights that ChatGPT is susceptible to hallucination when interpreting code semantic structures and fabricating non-existent facts. These results underscore the need to explore methods for verifying the correctness of ChatGPT's outputs to ensure its dependability in SE. More importantly, our study provide an iniital answer why the generated codes from LLMs are usually synatx correct but vulnerabale.
RNNS: Representation Nearest Neighbor Search Black-Box Attack on Code Models
May 20, 2023Pre-trained code models are mainly evaluated using the in-distribution test data. The robustness of models, i.e., the ability to handle hard unseen data, still lacks evaluation. In this paper, we propose a novel search-based black-box adversarial attack guided by model behaviours for pre-trained programming language models, named Representation Nearest Neighbor Search(RNNS), to evaluate the robustness of Pre-trained PL models. Unlike other black-box adversarial attacks, RNNS uses the model-change signal to guide the search in the space of the variable names collected from real-world projects. Specifically, RNNS contains two main steps, 1) indicate which variable (attack position location) we should attack based on model uncertainty, and 2) search which adversarial tokens we should use for variable renaming according to the model behaviour observations. We evaluate RNNS on 6 code tasks (e.g., clone detection), 3 programming languages (Java, Python, and C), and 3 pre-trained code models: CodeBERT, GraphCodeBERT, and CodeT5. The results demonstrate that RNNS outperforms the state-of-the-art black-box attacking methods (MHM and ALERT) in terms of attack success rate (ASR) and query times (QT). The perturbation of generated adversarial examples from RNNS is smaller than the baselines with respect to the number of replaced variables and the variable length change. Our experiments also show that RNNS is efficient in attacking the defended models and is useful for adversarial training.
Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Apr 10, 2023The success of the Neural Radiance Fields (NeRFs) for modeling and free-view rendering static objects has inspired numerous attempts on dynamic scenes. Current techniques that utilize neural rendering for facilitating free-view videos (FVVs) are restricted to either offline rendering or are capable of processing only brief sequences with minimal motion. In this paper, we present a novel technique, Residual Radiance Field or ReRF, as a highly compact neural representation to achieve real-time FVV rendering on long-duration dynamic scenes. ReRF explicitly models the residual information between adjacent timestamps in the spatial-temporal feature space, with a global coordinate-based tiny MLP as the feature decoder. Specifically, ReRF employs a compact motion grid along with a residual feature grid to exploit inter-frame feature similarities. We show such a strategy can handle large motions without sacrificing quality. We further present a sequential training scheme to maintain the smoothness and the sparsity of the motion/residual grids. Based on ReRF, we design a special FVV codec that achieves three orders of magnitudes compression rate and provides a companion ReRF player to support online streaming of long-duration FVVs of dynamic scenes. Extensive experiments demonstrate the effectiveness of ReRF for compactly representing dynamic radiance fields, enabling an unprecedented free-viewpoint viewing experience in speed and quality.
Boosting Source Code Learning with Data Augmentation: An Empirical Study
Mar 13, 2023The next era of program understanding is being propelled by the use of machine learning to solve software problems. Recent studies have shown surprising results of source code learning, which applies deep neural networks (DNNs) to various critical software tasks, e.g., bug detection and clone detection. This success can be greatly attributed to the utilization of massive high-quality training data, and in practice, data augmentation, which is a technique used to produce additional training data, has been widely adopted in various domains, such as computer vision. However, in source code learning, data augmentation has not been extensively studied, and existing practice is limited to simple syntax-preserved methods, such as code refactoring. Essentially, source code is often represented in two ways, namely, sequentially as text data and structurally as graph data, when it is used as training data in source code learning. Inspired by these analogy relations, we take an early step to investigate whether data augmentation methods that are originally used for text and graphs are effective in improving the training quality of source code learning. To that end, we first collect and categorize data augmentation methods in the literature. Second, we conduct a comprehensive empirical study on four critical tasks and 11 DNN architectures to explore the effectiveness of 12 data augmentation methods (including code refactoring and 11 other methods for text and graph data). Our results identify the data augmentation methods that can produce more accurate and robust models for source code learning, including those based on mixup (e.g., SenMixup for texts and Manifold-Mixup for graphs), and those that slightly break the syntax of source code (e.g., random swap and random deletion for texts).
NEPHELE: A Neural Platform for Highly Realistic Cloud Radiance Rendering
Mar 07, 2023We have recently seen tremendous progress in neural rendering (NR) advances, i.e., NeRF, for photo-real free-view synthesis. Yet, as a local technique based on a single computer/GPU, even the best-engineered Instant-NGP or i-NGP cannot reach real-time performance when rendering at a high resolution, and often requires huge local computing resources. In this paper, we resort to cloud rendering and present NEPHELE, a neural platform for highly realistic cloud radiance rendering. In stark contrast with existing NR approaches, our NEPHELE allows for more powerful rendering capabilities by combining multiple remote GPUs and facilitates collaboration by allowing multiple people to view the same NeRF scene simultaneously. We introduce i-NOLF to employ opacity light fields for ultra-fast neural radiance rendering in a one-query-per-ray manner. We further resemble the Lumigraph with geometry proxies for fast ray querying and subsequently employ a small MLP to model the local opacity lumishperes for high-quality rendering. We also adopt Perfect Spatial Hashing in i-NOLF to enhance cache coherence. As a result, our i-NOLF achieves an order of magnitude performance gain in terms of efficiency than i-NGP, especially for the multi-user multi-viewpoint setting under cloud rendering scenarios. We further tailor a task scheduler accompanied by our i-NOLF representation and demonstrate the advance of our methodological design through a comprehensive cloud platform, consisting of a series of cooperated modules, i.e., render farms, task assigner, frame composer, and detailed streaming strategies. Using such a cloud platform compatible with neural rendering, we further showcase the capabilities of our cloud radiance rendering through a series of applications, ranging from cloud VR/AR rendering.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
Dynamic Feature Pruning and Consolidation for Occluded Person Re-Identification
Nov 27, 2022Occluded person re-identification (ReID) is a challenging problem due to contamination from occluders, and existing approaches address the issue with prior knowledge cues, eg human body key points, semantic segmentations and etc, which easily fails in the presents of heavy occlusion and other humans as occluders. In this paper, we propose a feature pruning and consolidation (FPC) framework to circumvent explicit human structure parse, which mainly consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder. Specifically, the sparse encoder drops less important image tokens (mostly related to background noise and occluders) solely according to correlation within the class token attention instead of relying on prior human shape information. Subsequently, the ranking stage relies on the preserved tokens produced by the sparse encoder to identify k-nearest neighbors from a pre-trained gallery memory by measuring the image and patch-level combined similarity. Finally, we use the feature consolidation module to compensate pruned features using identified neighbors for recovering essential information while disregarding disturbance from noise and occlusion. Experimental results demonstrate the effectiveness of our proposed framework on occluded, partial and holistic Re-ID datasets. In particular, our method outperforms state-of-the-art results by at least 8.6% mAP and 6.0% Rank-1 accuracy on the challenging Occluded-Duke dataset.
Enhancing Code Classification by Mixup-Based Data Augmentation
Oct 06, 2022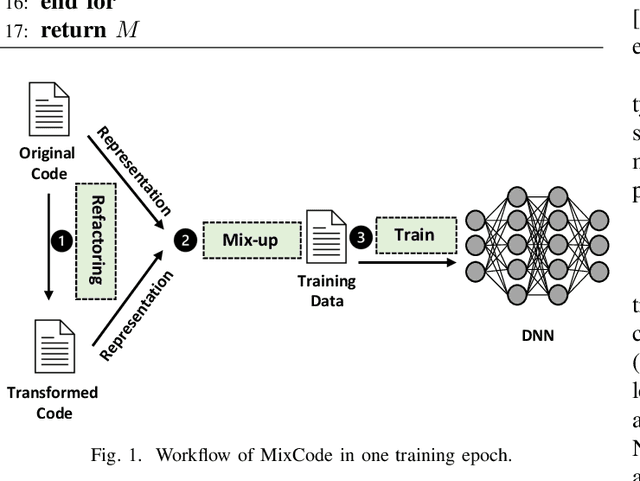
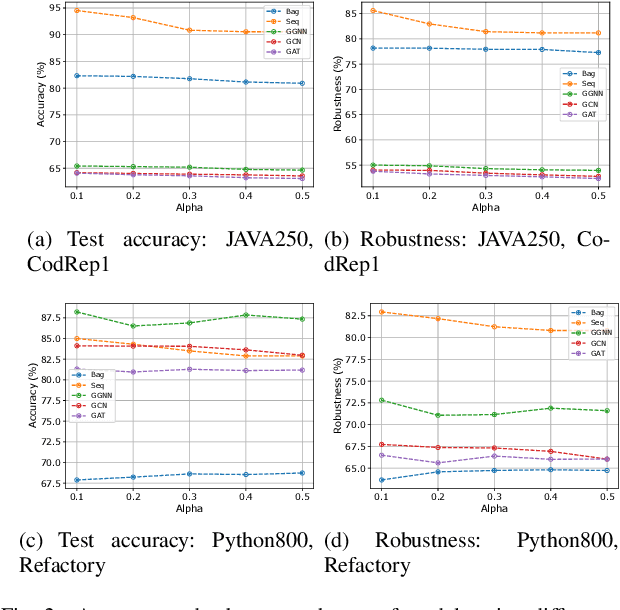
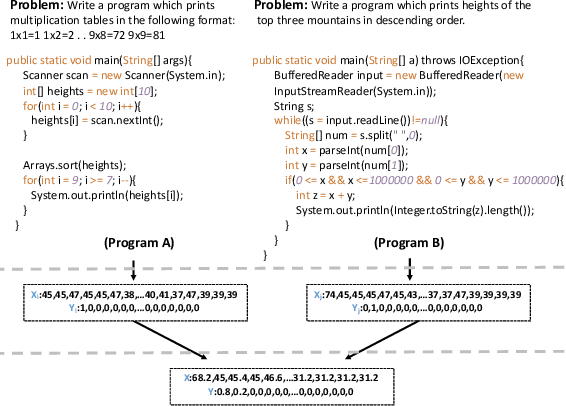
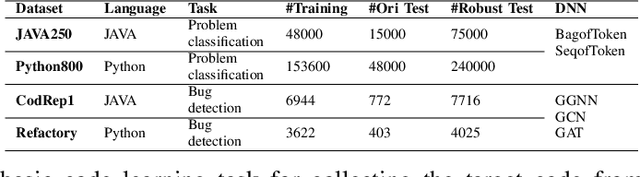
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.
Enhancing Mixup-Based Graph Learning for Language Processing via Hybrid Pooling
Oct 06, 2022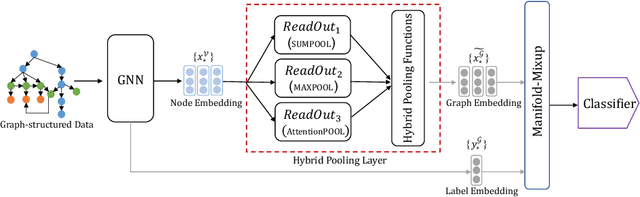
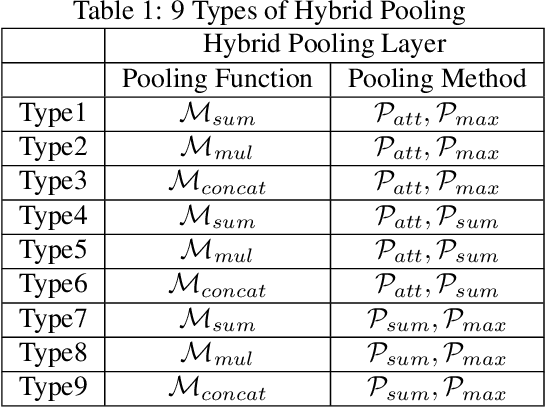

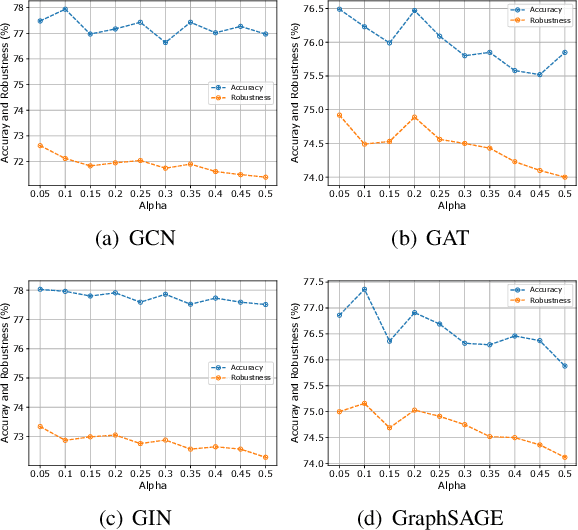
Graph neural networks (GNNs) have recently been popular in natural language and programming language processing, particularly in text and source code classification. Graph pooling which processes node representation into the entire graph representation, which can be used for multiple downstream tasks, e.g., graph classification, is a crucial component of GNNs. Recently, to enhance graph learning, Manifold Mixup, a data augmentation strategy that mixes the graph data vector after the pooling layer, has been introduced. However, since there are a series of graph pooling methods, how they affect the effectiveness of such a Mixup approach is unclear. In this paper, we take the first step to explore the influence of graph pooling methods on the effectiveness of the Mixup-based data augmentation approach. Specifically, 9 types of hybrid pooling methods are considered in the study, e.g., $\mathcal{M}_{sum}(\mathcal{P}_{att},\mathcal{P}_{max})$. The experimental results on both natural language datasets (Gossipcop, Politifact) and programming language datasets (Java250, Python800) demonstrate that hybrid pooling methods are more suitable for Mixup than the standard max pooling and the state-of-the-art graph multiset transformer (GMT) pooling, in terms of metric accuracy and robustness.