 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSkip: Combatting Statistical Heterogeneity with Federated Skip Aggregation
Dec 14, 2022



The statistical heterogeneity of the non-independent and identically distributed (non-IID) data in local clients significantly limits the performance of federated learning. Previous attempts like FedProx, SCAFFOLD, MOON, FedNova and FedDyn resort to an optimization perspective, which requires an auxiliary term or re-weights local updates to calibrate the learning bias or the objective inconsistency. However, in addition to previous explorations for improvement in federated averaging, our analysis shows that another critical bottleneck is the poorer optima of client models in more heterogeneous conditions. We thus introduce a data-driven approach called FedSkip to improve the client optima by periodically skipping federated averaging and scattering local models to the cross devices. We provide theoretical analysis of the possible benefit from FedSkip and conduct extensive experiments on a range of datasets to demonstrate that FedSkip achieves much higher accuracy, better aggregation efficiency and competing communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedSkip.
Feature Calibration Network for Occluded Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially for scenes containing serious occlusion. In this paper, we propose a novel feature learning method in the deep learning framework, referred to as Feature Calibration Network (FC-Net), to adaptively detect pedestrians under various occlusions. FC-Net is based on the observation that the visible parts of pedestrians are selective and decisive for detection, and is implemented as a self-paced feature learning framework with a self-activation (SA) module and a feature calibration (FC) module. In a new self-activated manner, FC-Net learns features which highlight the visible parts and suppress the occluded parts of pedestrians. The SA module estimates pedestrian activation maps by reusing classifier weights, without any additional parameter involved, therefore resulting in an extremely parsimony model to reinforce the semantics of features, while the FC module calibrates the convolutional features for adaptive pedestrian representation in both pixel-wise and region-based ways. Experiments on CityPersons and Caltech datasets demonstrate that FC-Net improves detection performance on occluded pedestrians up to 10% while maintaining excellent performance on non-occluded instances.
ConfounderGAN: Protecting Image Data Privacy with Causal Confounder
Dec 04, 2022The success of deep learning is partly attributed to the availability of massive data downloaded freely from the Internet. However, it also means that users' private data may be collected by commercial organizations without consent and used to train their models. Therefore, it's important and necessary to develop a method or tool to prevent unauthorized data exploitation. In this paper, we propose ConfounderGAN, a generative adversarial network (GAN) that can make personal image data unlearnable to protect the data privacy of its owners. Specifically, the noise produced by the generator for each image has the confounder property. It can build spurious correlations between images and labels, so that the model cannot learn the correct mapping from images to labels in this noise-added dataset. Meanwhile, the discriminator is used to ensure that the generated noise is small and imperceptible, thereby remaining the normal utility of the encrypted image for humans. The experiments are conducted in six image classification datasets, consisting of three natural object datasets and three medical datasets. The results demonstrate that our method not only outperforms state-of-the-art methods in standard settings, but can also be applied to fast encryption scenarios. Moreover, we show a series of transferability and stability experiments to further illustrate the effectiveness and superiority of our method.
Learning From Good Trajectories in Offline Multi-Agent Reinforcement Learning
Nov 28, 2022Offline multi-agent reinforcement learning (MARL) aims to learn effective multi-agent policies from pre-collected datasets, which is an important step toward the deployment of multi-agent systems in real-world applications. However, in practice, each individual behavior policy that generates multi-agent joint trajectories usually has a different level of how well it performs. e.g., an agent is a random policy while other agents are medium policies. In the cooperative game with global reward, one agent learned by existing offline MARL often inherits this random policy, jeopardizing the performance of the entire team. In this paper, we investigate offline MARL with explicit consideration on the diversity of agent-wise trajectories and propose a novel framework called Shared Individual Trajectories (SIT) to address this problem. Specifically, an attention-based reward decomposition network assigns the credit to each agent through a differentiable key-value memory mechanism in an offline manner. These decomposed credits are then used to reconstruct the joint offline datasets into prioritized experience replay with individual trajectories, thereafter agents can share their good trajectories and conservatively train their policies with a graph attention network (GAT) based critic. We evaluate our method in both discrete control (i.e., StarCraft II and multi-agent particle environment) and continuous control (i.e, multi-agent mujoco). The results indicate that our method achieves significantly better results in complex and mixed offline multi-agent datasets, especially when the difference of data quality between individual trajectories is large.
Integrally Pre-Trained Transformer Pyramid Networks
Nov 23, 2022



In this paper, we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pre-training stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular, the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1x training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead -- all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022



In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022



Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
See Blue Sky: Deep Image Dehaze Using Paired and Unpaired Training Images
Oct 14, 2022
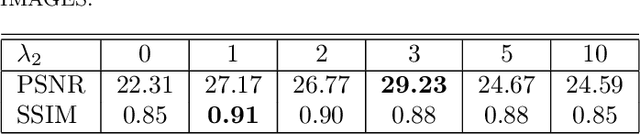
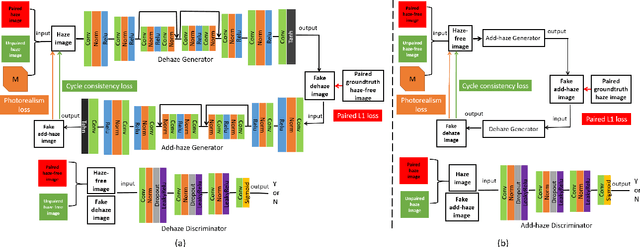
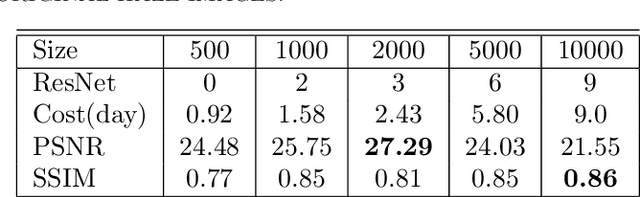
The issue of image haze removal has attracted wide attention in recent years. However, most existing haze removal methods cannot restore the scene with clear blue sky, since the color and texture information of the object in the original haze image is insufficient. To remedy this, we propose a cycle generative adversarial network to construct a novel end-to-end image dehaze model. We adopt outdoor image datasets to train our model, which includes a set of real-world unpaired image dataset and a set of paired image dataset to ensure that the generated images are close to the real scene. Based on the cycle structure, our model adds four different kinds of loss function to constrain the effect including adversarial loss, cycle consistency loss, photorealism loss and paired L1 loss. These four constraints can improve the overall quality of such degraded images for better visual appeal and ensure reconstruction of images to keep from distortion. The proposed model could remove the haze of images and also restore the sky of images to be clean and blue (like captured in a sunny weather).
Towards a Unified View on Visual Parameter-Efficient Transfer Learning
Oct 03, 2022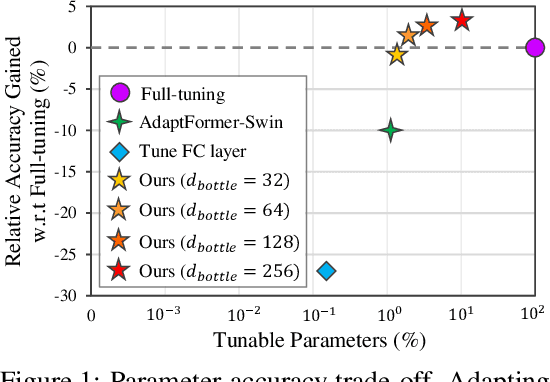
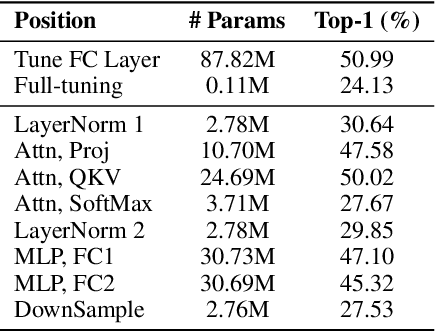
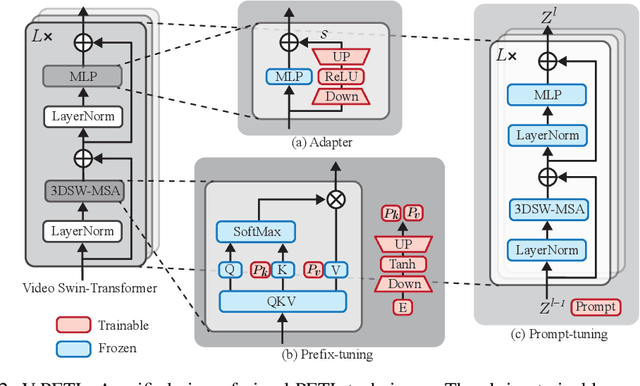
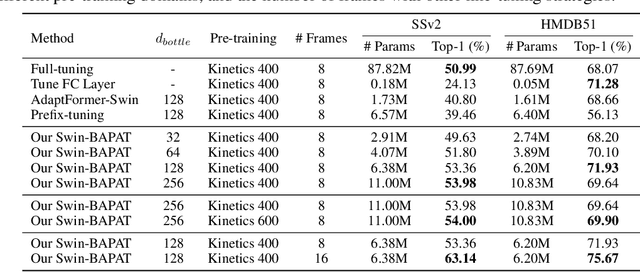
Since the release of various large-scale natural language processing (NLP) pre-trained models, parameter efficient transfer learning (PETL) has become a popular paradigm capable of achieving impressive performance on various downstream tasks. PETL aims at making good use of the representation knowledge in the pre-trained large models by fine-tuning a small number of parameters. Recently, it has also attracted increasing attention to developing various PETL techniques for vision tasks. Popular PETL techniques such as Prompt-tuning and Adapter have been proposed for high-level visual downstream tasks such as image classification and video recognition. However, Prefix-tuning remains under-explored for vision tasks. In this work, we intend to adapt large video-based models to downstream tasks with a good parameter-accuracy trade-off. Towards this goal, we propose a framework with a unified view called visual-PETL (V-PETL) to investigate the different aspects affecting the trade-off. Specifically, we analyze the positional importance of trainable parameters and differences between NLP and vision tasks in terms of data structures and pre-training mechanisms while implementing various PETL techniques, especially for the under-explored prefix-tuning technique. Based on a comprehensive understanding of differences between NLP and video data, we propose a new variation of prefix-tuning module called parallel attention (PATT) for video-based downstream tasks. An extensive empirical analysis on two video datasets via different frozen backbones has been carried and the findings show that the proposed PATT can effectively contribute to other PETL techniques. An effective scheme Swin-BAPAT derived from the proposed V-PETL framework achieves significantly better performance than the state-of-the-art AdaptFormer-Swin with slightly more parameters and outperforms full-tuning with far less parameters.
Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Oct 01, 2022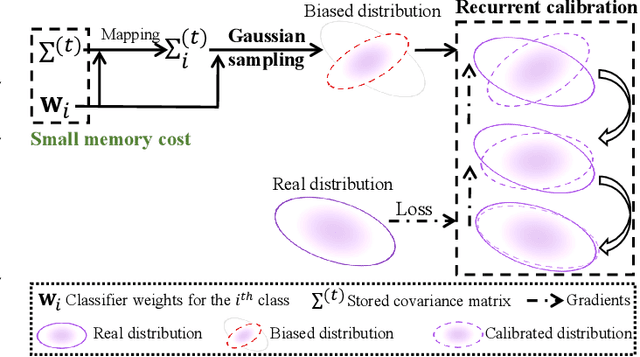



Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid `forgetting', as well as estimating distributions and augmenting samples for new classes to alleviate `over-fitting' caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL's flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC's effectiveness is also validated on few-shot learning scenarios.