 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectivity Estimation with Deep Likelihood Models
May 10, 2019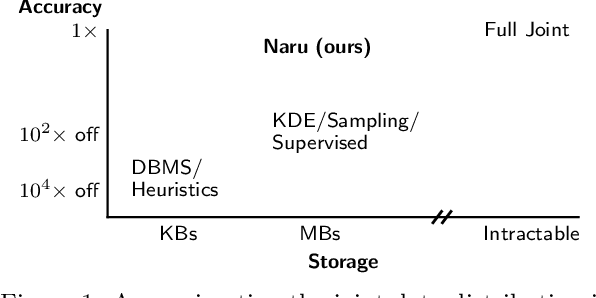
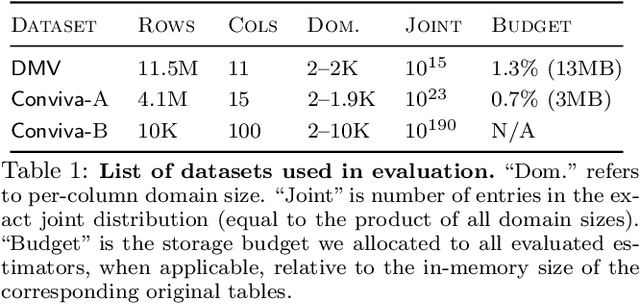
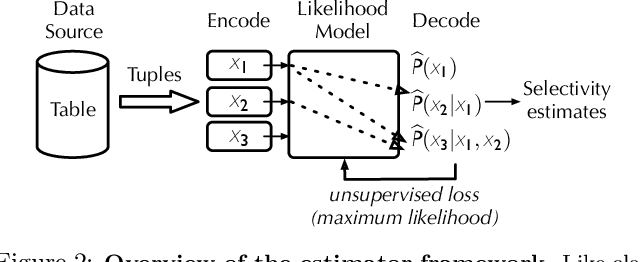
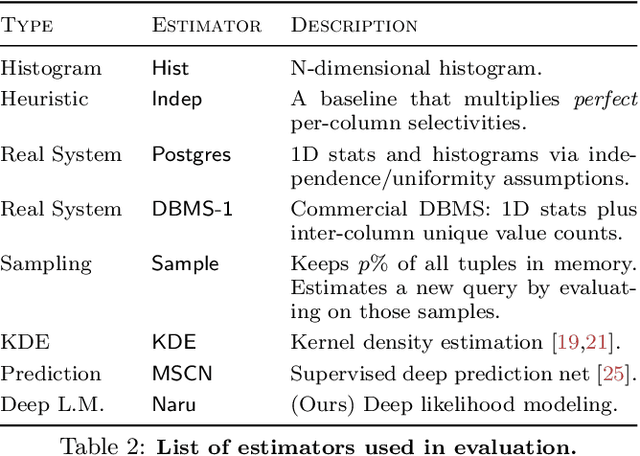
Selectivity estimation has long been grounded in statistical tools for density estimation. To capture the rich multivariate distributions of relational tables, we propose the use of a new type of high-capacity statistical model: deep likelihood models. However, direct application of these models leads to a limited estimator that is prohibitively expensive to evaluate for range and wildcard predicates. To make a truly usable estimator, we develop a Monte Carlo integration scheme on top of likelihood models that can efficiently handle range queries with dozens of filters or more. Like classical synopses, our estimator summarizes the data without supervision. Unlike previous solutions, our estimator approximates the joint data distribution without any independence assumptions. When evaluated on real-world datasets and compared against real systems and dominant families of techniques, our likelihood model based estimator achieves single-digit multiplicative error at tail, a 40-200$\times$ accuracy improvement over the second best method, and is space- and runtime-efficient.
Quasi-Direct Drive for Low-Cost Compliant Robotic Manipulation
Apr 11, 2019
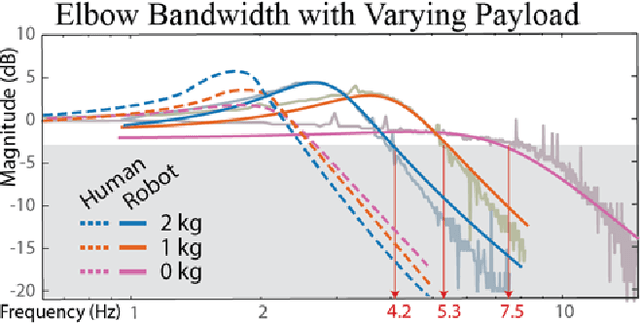


Robots must cost less and be force-controlled to enable widespread, safe deployment in unconstrained human environments. We propose Quasi-Direct Drive actuation as a capable paradigm for robotic force-controlled manipulation in human environments at low-cost. Our prototype - Blue - is a human scale 7 Degree of Freedom arm with 2kg payload. Blue can cost less than $5000. We show that Blue has dynamic properties that meet or exceed the needs of human operators: the robot has a nominal position-control bandwidth of 7.5Hz and repeatability within 4mm. We demonstrate a Virtual Reality based interface that can be used as a method for telepresence and collecting robot training demonstrations. Manufacturability, scaling, and potential use-cases for the Blue system are also addressed. Videos and additional information can be found online at berkeleyopenarms.github.io
Guided Meta-Policy Search
Apr 01, 2019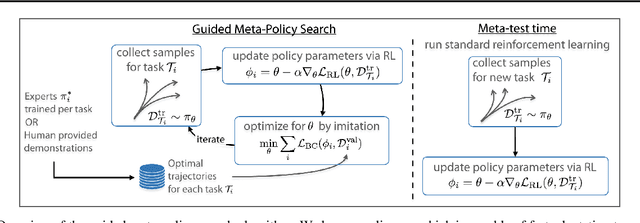
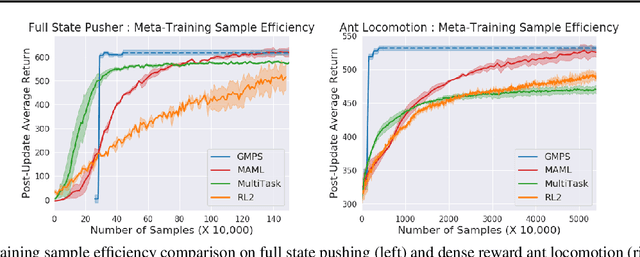
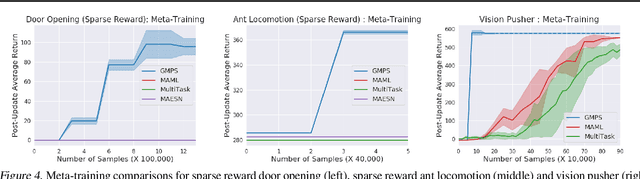
Reinforcement learning (RL) algorithms have demonstrated promising results on complex tasks, yet often require impractical numbers of samples because they learn from scratch. Meta-RL aims to address this challenge by leveraging experience from previous tasks in order to more quickly solve new tasks. However, in practice, these algorithms generally also require large amounts of on-policy experience during the meta-training process, making them impractical for use in many problems. To this end, we propose to learn a reinforcement learning procedure through imitation of expert policies that solve previously-seen tasks. This involves a nested optimization, with RL in the inner loop and supervised imitation learning in the outer loop. Because the outer loop imitation learning can be done with off-policy data, we can achieve significant gains in meta-learning sample efficiency. In this paper, we show how this general idea can be used both for meta-reinforcement learning and for learning fast RL procedures from multi-task demonstration data. The former results in an approach that can leverage policies learned for previous tasks without significant amounts of on-policy data during meta-training, whereas the latter is particularly useful in cases where demonstrations are easy for a person to provide. Across a number of continuous control meta-RL problems, we demonstrate significant improvements in meta-RL sample efficiency in comparison to prior work as well as the ability to scale to domains with visual observations.
Towards Characterizing Divergence in Deep Q-Learning
Mar 21, 2019
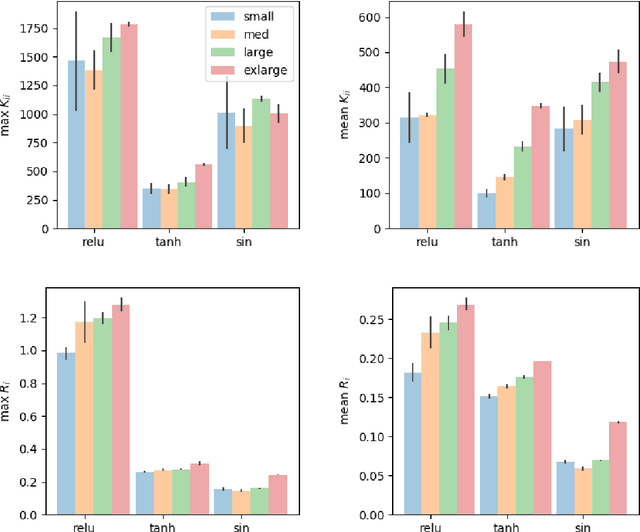
Deep Q-Learning (DQL), a family of temporal difference algorithms for control, employs three techniques collectively known as the `deadly triad' in reinforcement learning: bootstrapping, off-policy learning, and function approximation. Prior work has demonstrated that together these can lead to divergence in Q-learning algorithms, but the conditions under which divergence occurs are not well-understood. In this note, we give a simple analysis based on a linear approximation to the Q-value updates, which we believe provides insight into divergence under the deadly triad. The central point in our analysis is to consider when the leading order approximation to the deep-Q update is or is not a contraction in the sup norm. Based on this analysis, we develop an algorithm which permits stable deep Q-learning for continuous control without any of the tricks conventionally used (such as target networks, adaptive gradient optimizers, or using multiple Q functions). We demonstrate that our algorithm performs above or near state-of-the-art on standard MuJoCo benchmarks from the OpenAI Gym.
Reinforcement Learning on Variable Impedance Controller for High-Precision Robotic Assembly
Mar 20, 2019

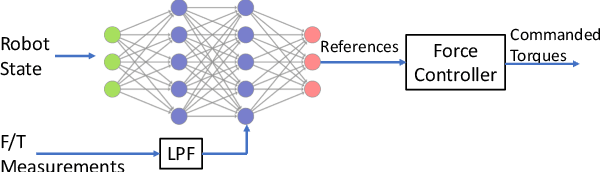

Precise robotic manipulation skills are desirable in many industrial settings, reinforcement learning (RL) methods hold the promise of acquiring these skills autonomously. In this paper, we explicitly consider incorporating operational space force/torque information into reinforcement learning; this is motivated by humans heuristically mapping perceived forces to control actions, which results in completing high-precision tasks in a fairly easy manner. Our approach combines RL with force/torque information by incorporating a proper operational space force controller; where we also exploit different ablations on processing this information. Moreover, we propose a neural network architecture that generalizes to reasonable variations of the environment. We evaluate our method on the open-source Siemens Robot Learning Challenge, which requires precise and delicate force-controlled behavior to assemble a tight-fit gear wheel set.
Domain Randomization for Active Pose Estimation
Mar 10, 2019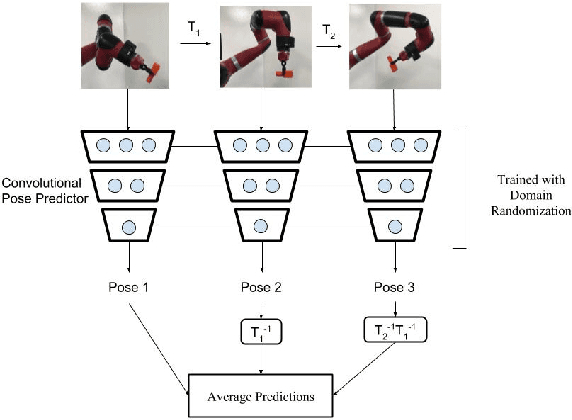



Accurate state estimation is a fundamental component of robotic control. In robotic manipulation tasks, as is our focus in this work, state estimation is essential for identifying the positions of objects in the scene, forming the basis of the manipulation plan. However, pose estimation typically requires expensive 3D cameras or additional instrumentation such as fiducial markers to perform accurately. Recently, Tobin et al.~introduced an approach to pose estimation based on domain randomization, where a neural network is trained to predict pose directly from a 2D image of the scene. The network is trained on computer-generated images with a high variation in textures and lighting, thereby generalizing to real-world images. In this work, we investigate how to improve the accuracy of domain randomization based pose estimation. Our main idea is that active perception -- moving the robot to get a better estimate of pose -- can be trained in simulation and transferred to real using domain randomization. In our approach, the robot trains in a domain-randomized simulation how to estimate pose from a \emph{sequence} of images. We show that our approach can significantly improve the accuracy of standard pose estimation in several scenarios: when the robot holding an object moves, when reference objects are moved in the scene, or when the camera is moved around the object.
Learning to Adapt in Dynamic, Real-World Environments Through Meta-Reinforcement Learning
Feb 27, 2019
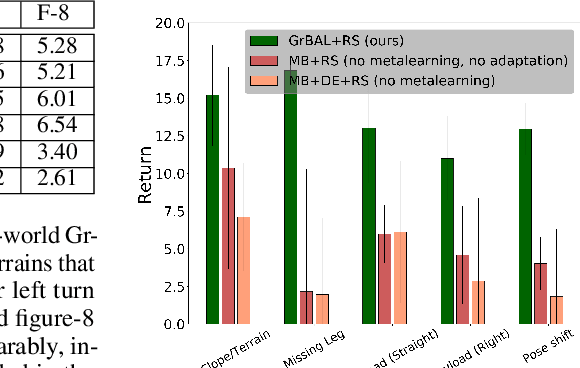


Although reinforcement learning methods can achieve impressive results in simulation, the real world presents two major challenges: generating samples is exceedingly expensive, and unexpected perturbations or unseen situations cause proficient but specialized policies to fail at test time. Given that it is impractical to train separate policies to accommodate all situations the agent may see in the real world, this work proposes to learn how to quickly and effectively adapt online to new tasks. To enable sample-efficient learning, we consider learning online adaptation in the context of model-based reinforcement learning. Our approach uses meta-learning to train a dynamics model prior such that, when combined with recent data, this prior can be rapidly adapted to the local context. Our experiments demonstrate online adaptation for continuous control tasks on both simulated and real-world agents. We first show simulated agents adapting their behavior online to novel terrains, crippled body parts, and highly-dynamic environments. We also illustrate the importance of incorporating online adaptation into autonomous agents that operate in the real world by applying our method to a real dynamic legged millirobot. We demonstrate the agent's learned ability to quickly adapt online to a missing leg, adjust to novel terrains and slopes, account for miscalibration or errors in pose estimation, and compensate for pulling payloads.
SOLAR: Deep Structured Representations for Model-Based Reinforcement Learning
Feb 20, 2019
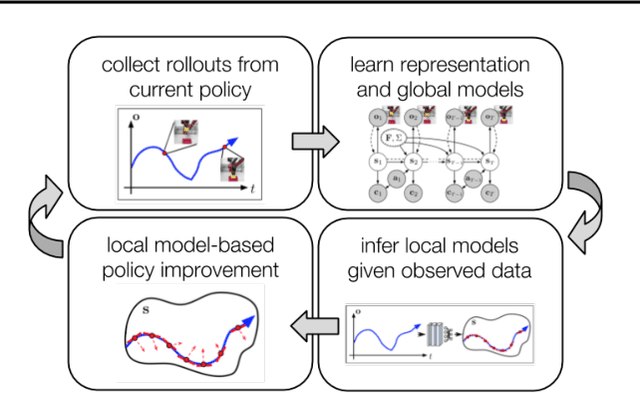
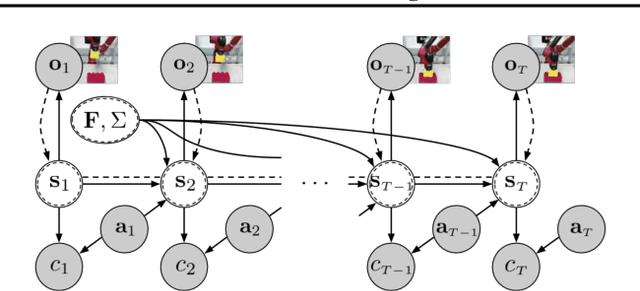

Model-based reinforcement learning (RL) has proven to be a data efficient approach for learning control tasks but is difficult to utilize in domains with complex observations such as images. In this paper, we present a method for learning representations that are suitable for iterative model-based policy improvement, in that these representations are optimized for inferring simple dynamics and cost models given data from the current policy. This enables a model-based RL method based on the linear-quadratic regulator (LQR) to be used for systems with image observations. We evaluate our approach on a suite of robotics tasks, including manipulation tasks on a real Sawyer robot arm directly from images, and we find that our method results in better final performance than other model-based RL methods while being significantly more efficient than model-free RL. Videos of our results are available at https://sites.google.com/view/icml19solar
Preferences Implicit in the State of the World
Feb 12, 2019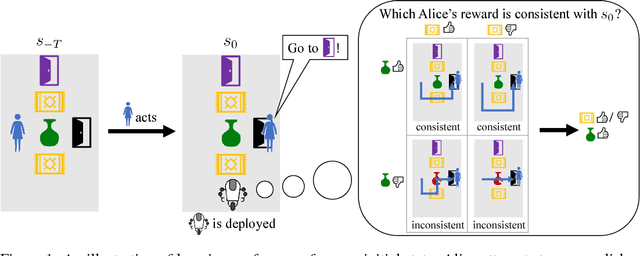
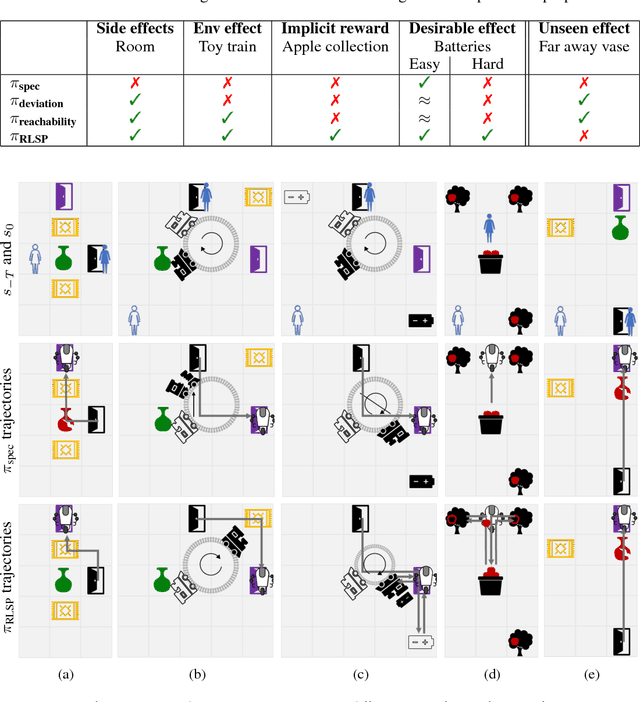
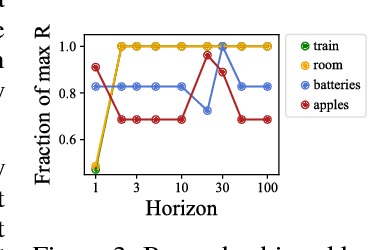
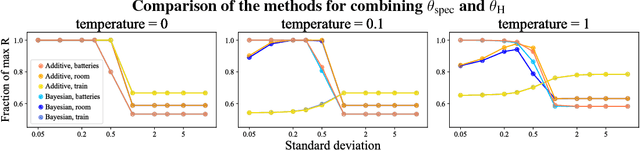
Reinforcement learning (RL) agents optimize only the features specified in a reward function and are indifferent to anything left out inadvertently. This means that we must not only specify what to do, but also the much larger space of what not to do. It is easy to forget these preferences, since these preferences are already satisfied in our environment. This motivates our key insight: when a robot is deployed in an environment that humans act in, the state of the environment is already optimized for what humans want. We can therefore use this implicit preference information from the state to fill in the blanks. We develop an algorithm based on Maximum Causal Entropy IRL and use it to evaluate the idea in a suite of proof-of-concept environments designed to show its properties. We find that information from the initial state can be used to infer both side effects that should be avoided as well as preferences for how the environment should be organized. Our code can be found at https://github.com/HumanCompatibleAI/rlsp.
Generalization through Simulation: Integrating Simulated and Real Data into Deep Reinforcement Learning for Vision-Based Autonomous Flight
Feb 11, 2019
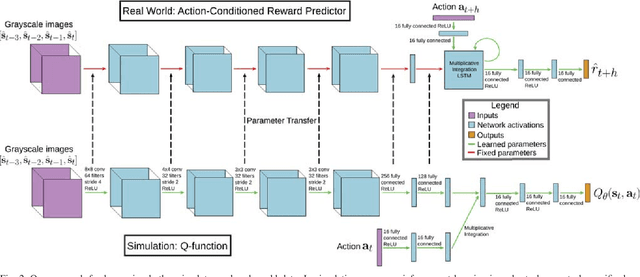

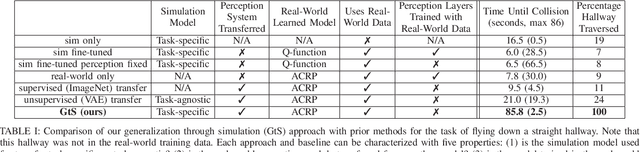
Deep reinforcement learning provides a promising approach for vision-based control of real-world robots. However, the generalization of such models depends critically on the quantity and variety of data available for training. This data can be difficult to obtain for some types of robotic systems, such as fragile, small-scale quadrotors. Simulated rendering and physics can provide for much larger datasets, but such data is inherently of lower quality: many of the phenomena that make the real-world autonomous flight problem challenging, such as complex physics and air currents, are modeled poorly or not at all, and the systematic differences between simulation and the real world are typically impossible to eliminate. In this work, we investigate how data from both simulation and the real world can be combined in a hybrid deep reinforcement learning algorithm. Our method uses real-world data to learn about the dynamics of the system, and simulated data to learn a generalizable perception system that can enable the robot to avoid collisions using only a monocular camera. We demonstrate our approach on a real-world nano aerial vehicle collision avoidance task, showing that with only an hour of real-world data, the quadrotor can avoid collisions in new environments with various lighting conditions and geometry. Code, instructions for building the aerial vehicles, and videos of the experiments can be found at github.com/gkahn13/GtS