 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022
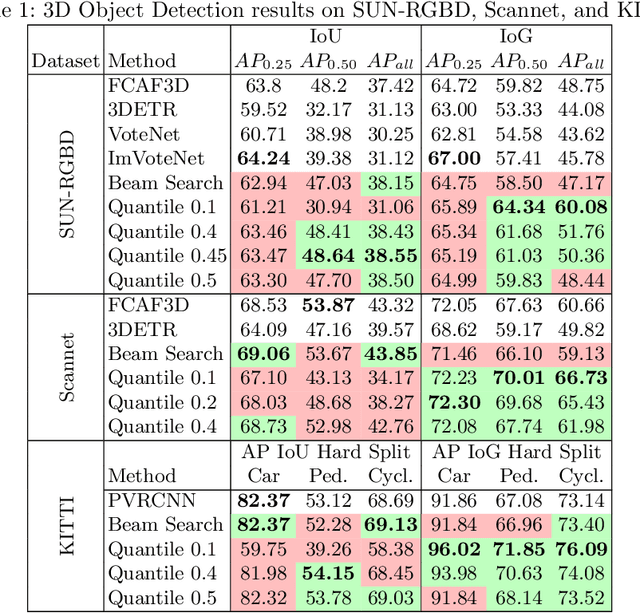
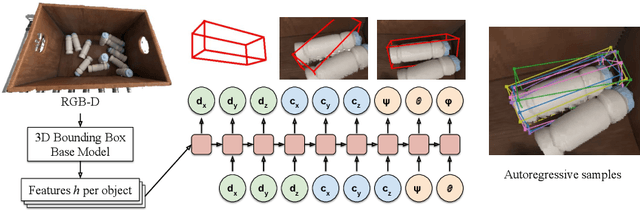
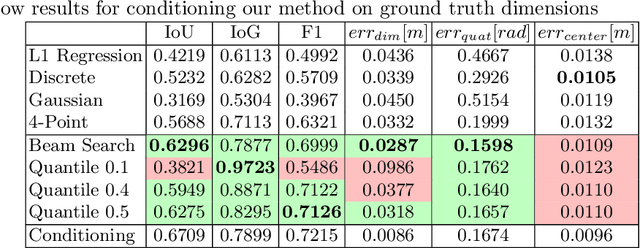
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

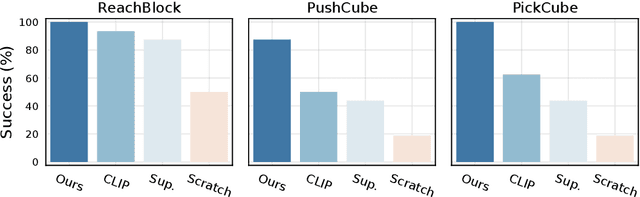
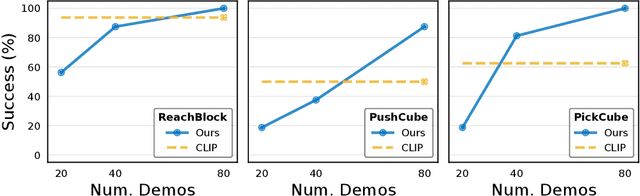
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.
Temporally Consistent Video Transformer for Long-Term Video Prediction
Oct 05, 2022
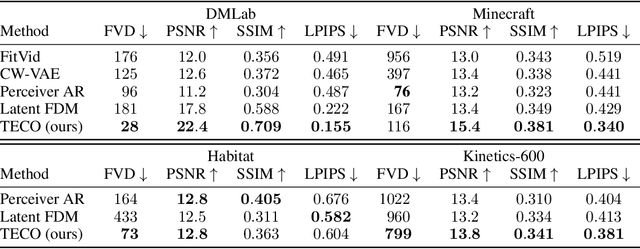
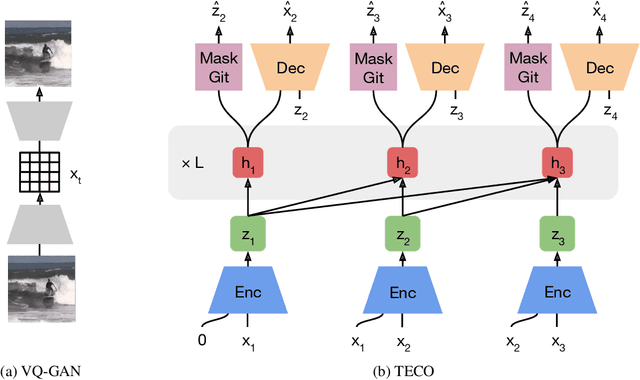
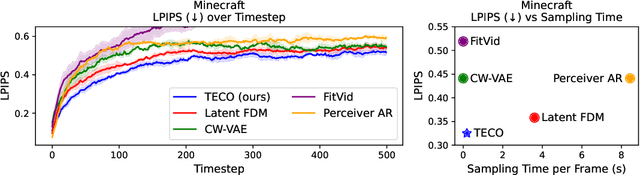
Generating long, temporally consistent video remains an open challenge in video generation. Primarily due to computational limitations, most prior methods limit themselves to training on a small subset of frames that are then extended to generate longer videos through a sliding window fashion. Although these techniques may produce sharp videos, they have difficulty retaining long-term temporal consistency due to their limited context length. In this work, we present Temporally Consistent Video Transformer (TECO), a vector-quantized latent dynamics video prediction model that learns compressed representations to efficiently condition on long videos of hundreds of frames during both training and generation. We use a MaskGit prior for dynamics prediction which enables both sharper and faster generations compared to prior work. Our experiments show that TECO outperforms SOTA baselines in a variety of video prediction benchmarks ranging from simple mazes in DMLab, large 3D worlds in Minecraft, and complex real-world videos from Kinetics-600. In addition, to better understand the capabilities of video prediction models in modeling temporal consistency, we introduce several challenging video prediction tasks consisting of agents randomly traversing 3D scenes of varying difficulty. This presents a challenging benchmark for video prediction in partially observable environments where a model must understand what parts of the scenes to re-create versus invent depending on its past observations or generations. Generated videos are available at https://wilson1yan.github.io/teco
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Sep 16, 2022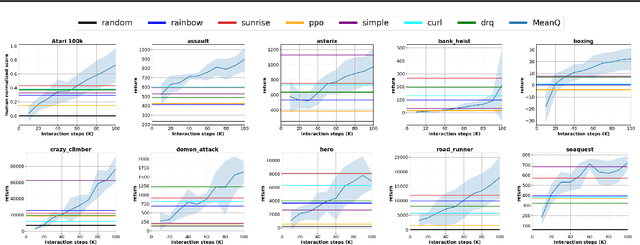

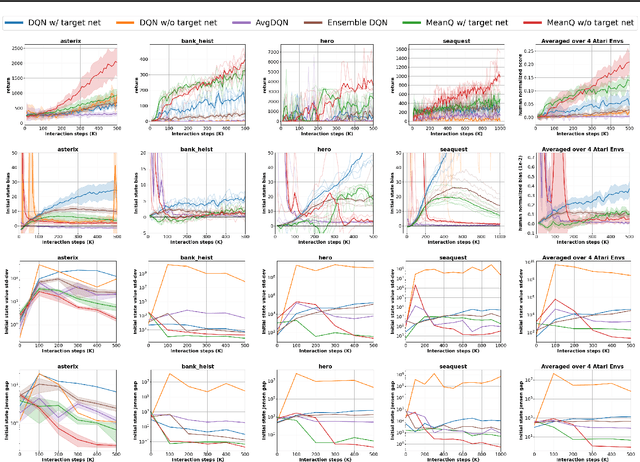
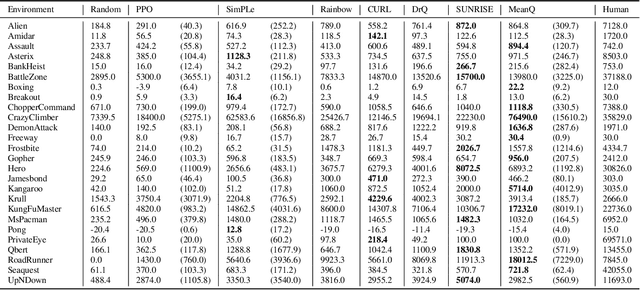
In temporal-difference reinforcement learning algorithms, variance in value estimation can cause instability and overestimation of the maximal target value. Many algorithms have been proposed to reduce overestimation, including several recent ensemble methods, however none have shown success in sample-efficient learning through addressing estimation variance as the root cause of overestimation. In this paper, we propose MeanQ, a simple ensemble method that estimates target values as ensemble means. Despite its simplicity, MeanQ shows remarkable sample efficiency in experiments on the Atari Learning Environment benchmark. Importantly, we find that an ensemble of size 5 sufficiently reduces estimation variance to obviate the lagging target network, eliminating it as a source of bias and further gaining sample efficiency. We justify intuitively and empirically the design choices in MeanQ, including the necessity of independent experience sampling. On a set of 26 benchmark Atari environments, MeanQ outperforms all tested baselines, including the best available baseline, SUNRISE, at 100K interaction steps in 16/26 environments, and by 68% on average. MeanQ also outperforms Rainbow DQN at 500K steps in 21/26 environments, and by 49% on average, and achieves average human-level performance using 200K ($\pm$100K) interaction steps. Our implementation is available at https://github.com/indylab/MeanQ.
HARP: Autoregressive Latent Video Prediction with High-Fidelity Image Generator
Sep 15, 2022
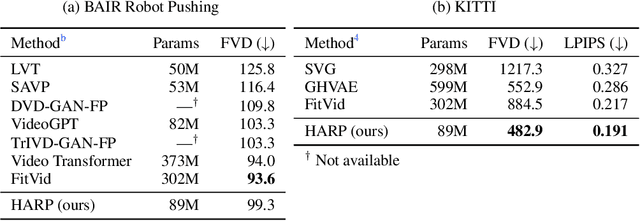
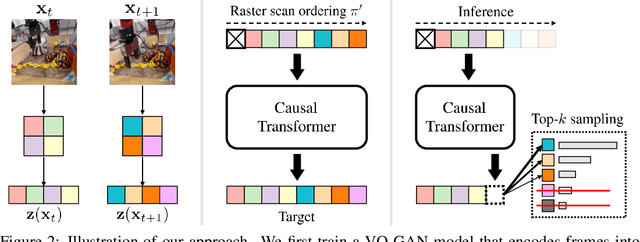
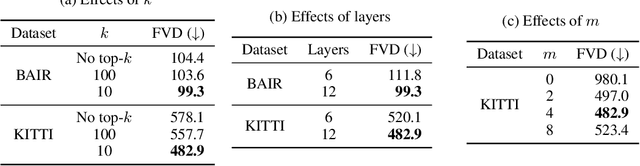
Video prediction is an important yet challenging problem; burdened with the tasks of generating future frames and learning environment dynamics. Recently, autoregressive latent video models have proved to be a powerful video prediction tool, by separating the video prediction into two sub-problems: pre-training an image generator model, followed by learning an autoregressive prediction model in the latent space of the image generator. However, successfully generating high-fidelity and high-resolution videos has yet to be seen. In this work, we investigate how to train an autoregressive latent video prediction model capable of predicting high-fidelity future frames with minimal modification to existing models, and produce high-resolution (256x256) videos. Specifically, we scale up prior models by employing a high-fidelity image generator (VQ-GAN) with a causal transformer model, and introduce additional techniques of top-k sampling and data augmentation to further improve video prediction quality. Despite the simplicity, the proposed method achieves competitive performance to state-of-the-art approaches on standard video prediction benchmarks with fewer parameters, and enables high-resolution video prediction on complex and large-scale datasets. Videos are available at https://sites.google.com/view/harp-videos/home.
Multi-Objective Policy Gradients with Topological Constraints
Sep 15, 2022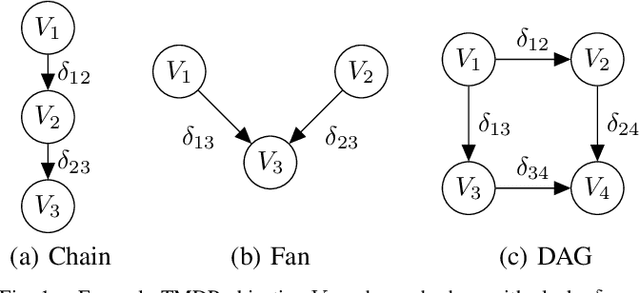
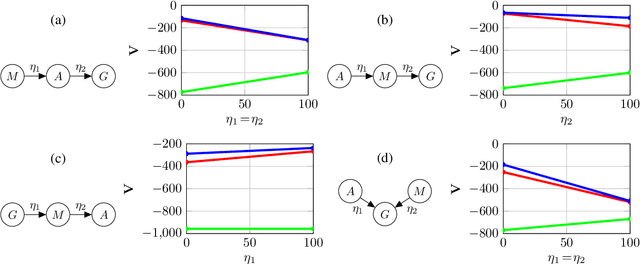

Multi-objective optimization models that encode ordered sequential constraints provide a solution to model various challenging problems including encoding preferences, modeling a curriculum, and enforcing measures of safety. A recently developed theory of topological Markov decision processes (TMDPs) captures this range of problems for the case of discrete states and actions. In this work, we extend TMDPs towards continuous spaces and unknown transition dynamics by formulating, proving, and implementing the policy gradient theorem for TMDPs. This theoretical result enables the creation of TMDP learning algorithms that use function approximators, and can generalize existing deep reinforcement learning (DRL) approaches. Specifically, we present a new algorithm for a policy gradient in TMDPs by a simple extension of the proximal policy optimization (PPO) algorithm. We demonstrate this on a real-world multiple-objective navigation problem with an arbitrary ordering of objectives both in simulation and on a real robot.
AdaCat: Adaptive Categorical Discretization for Autoregressive Models
Aug 03, 2022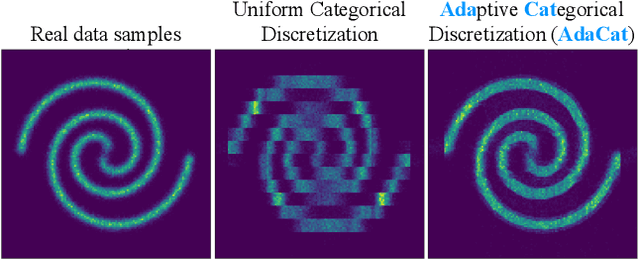
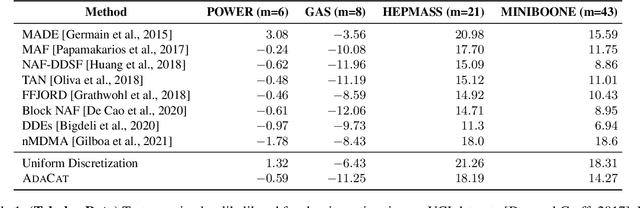
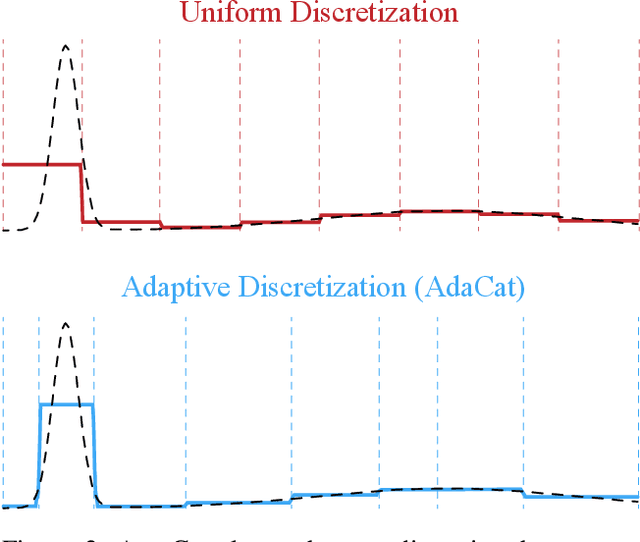
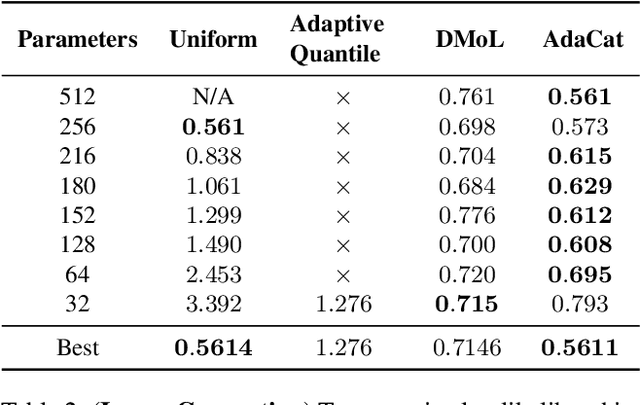
Autoregressive generative models can estimate complex continuous data distributions, like trajectory rollouts in an RL environment, image intensities, and audio. Most state-of-the-art models discretize continuous data into several bins and use categorical distributions over the bins to approximate the continuous data distribution. The advantage is that the categorical distribution can easily express multiple modes and are straightforward to optimize. However, such approximation cannot express sharp changes in density without using significantly more bins, making it parameter inefficient. We propose an efficient, expressive, multimodal parameterization called Adaptive Categorical Discretization (AdaCat). AdaCat discretizes each dimension of an autoregressive model adaptively, which allows the model to allocate density to fine intervals of interest, improving parameter efficiency. AdaCat generalizes both categoricals and quantile-based regression. AdaCat is a simple add-on to any discretization-based distribution estimator. In experiments, AdaCat improves density estimation for real-world tabular data, images, audio, and trajectories, and improves planning in model-based offline RL.
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
Jun 29, 2022
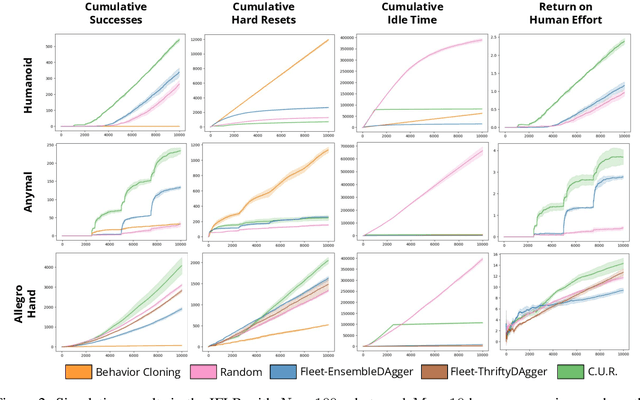
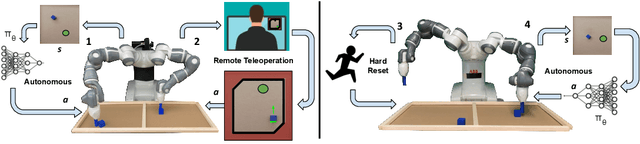
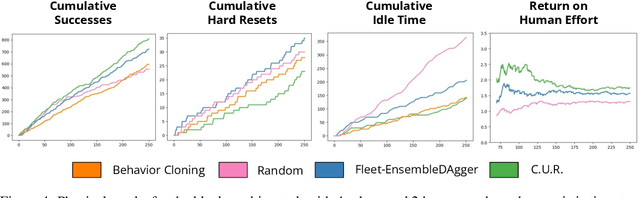
Commercial and industrial deployments of robot fleets often fall back on remote human teleoperators during execution when robots are at risk or unable to make task progress. With continual learning, interventions from the remote pool of humans can also be used to improve the robot fleet control policy over time. A central question is how to effectively allocate limited human attention to individual robots. Prior work addresses this in the single-robot, single-human setting. We formalize the Interactive Fleet Learning (IFL) setting, in which multiple robots interactively query and learn from multiple human supervisors. We present a fully implemented open-source IFL benchmark suite of GPU-accelerated Isaac Gym environments for the evaluation of IFL algorithms. We propose Fleet-DAgger, a family of IFL algorithms, and compare a novel Fleet-DAgger algorithm to 4 baselines in simulation. We also perform 1000 trials of a physical block-pushing experiment with 4 ABB YuMi robot arms. Experiments suggest that the allocation of humans to robots significantly affects robot fleet performance, and that our algorithm achieves up to 8.8x higher return on human effort than baselines. See https://tinyurl.com/fleet-dagger for code, videos, and supplemental material.
Masked World Models for Visual Control
Jun 28, 2022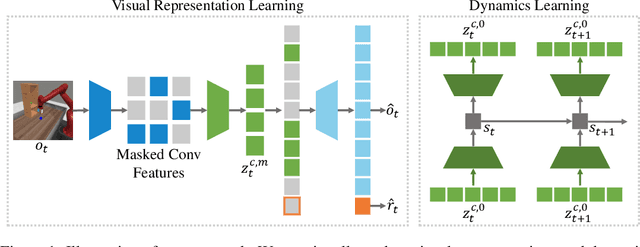
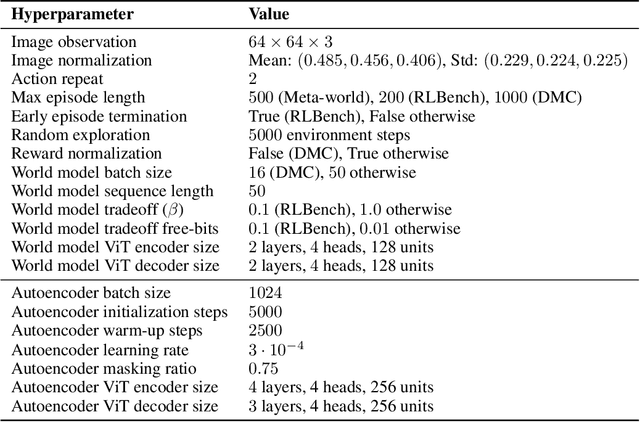

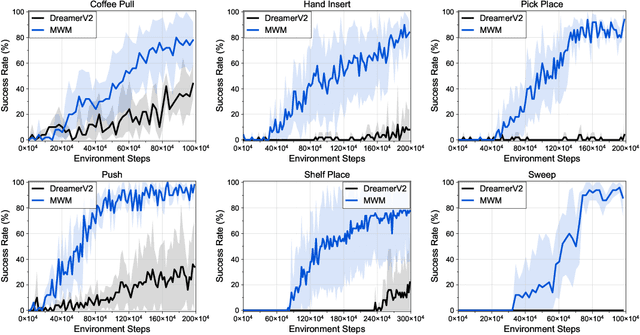
Visual model-based reinforcement learning (RL) has the potential to enable sample-efficient robot learning from visual observations. Yet the current approaches typically train a single model end-to-end for learning both visual representations and dynamics, making it difficult to accurately model the interaction between robots and small objects. In this work, we introduce a visual model-based RL framework that decouples visual representation learning and dynamics learning. Specifically, we train an autoencoder with convolutional layers and vision transformers (ViT) to reconstruct pixels given masked convolutional features, and learn a latent dynamics model that operates on the representations from the autoencoder. Moreover, to encode task-relevant information, we introduce an auxiliary reward prediction objective for the autoencoder. We continually update both autoencoder and dynamics model using online samples collected from environment interaction. We demonstrate that our decoupling approach achieves state-of-the-art performance on a variety of visual robotic tasks from Meta-world and RLBench, e.g., we achieve 81.7% success rate on 50 visual robotic manipulation tasks from Meta-world, while the baseline achieves 67.9%. Code is available on the project website: https://sites.google.com/view/mwm-rl.
DayDreamer: World Models for Physical Robot Learning
Jun 28, 2022
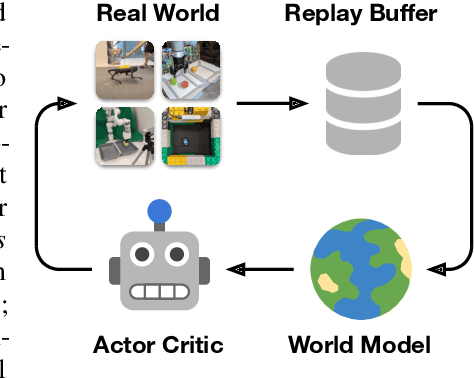
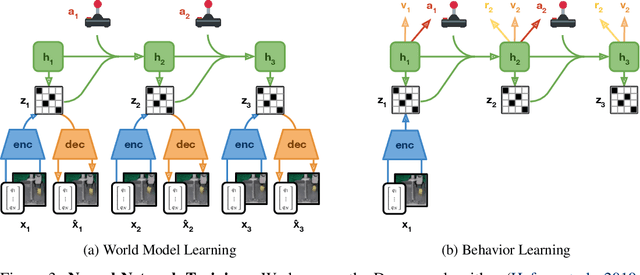

To solve tasks in complex environments, robots need to learn from experience. Deep reinforcement learning is a common approach to robot learning but requires a large amount of trial and error to learn, limiting its deployment in the physical world. As a consequence, many advances in robot learning rely on simulators. On the other hand, learning inside of simulators fails to capture the complexity of the real world, is prone to simulator inaccuracies, and the resulting behaviors do not adapt to changes in the world. The Dreamer algorithm has recently shown great promise for learning from small amounts of interaction by planning within a learned world model, outperforming pure reinforcement learning in video games. Learning a world model to predict the outcomes of potential actions enables planning in imagination, reducing the amount of trial and error needed in the real environment. However, it is unknown whether Dreamer can facilitate faster learning on physical robots. In this paper, we apply Dreamer to 4 robots to learn online and directly in the real world, without simulators. Dreamer trains a quadruped robot to roll off its back, stand up, and walk from scratch and without resets in only 1 hour. We then push the robot and find that Dreamer adapts within 10 minutes to withstand perturbations or quickly roll over and stand back up. On two different robotic arms, Dreamer learns to pick and place multiple objects directly from camera images and sparse rewards, approaching human performance. On a wheeled robot, Dreamer learns to navigate to a goal position purely from camera images, automatically resolving ambiguity about the robot orientation. Using the same hyperparameters across all experiments, we find that Dreamer is capable of online learning in the real world, establishing a strong baseline. We release our infrastructure for future applications of world models to robot learning.