 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Aware Dynamic Localization and Refinement for Referring Image Segmentation
Mar 11, 2023Referring image segmentation segments an image from a language expression. With the aim of producing high-quality masks, existing methods often adopt iterative learning approaches that rely on RNNs or stacked attention layers to refine vision-language features. Despite their complexity, RNN-based methods are subject to specific encoder choices, while attention-based methods offer limited gains. In this work, we introduce a simple yet effective alternative for progressively learning discriminative multi-modal features. The core idea of our approach is to leverage a continuously updated query as the representation of the target object and at each iteration, strengthen multi-modal features strongly correlated to the query while weakening less related ones. As the query is initialized by language features and successively updated by object features, our algorithm gradually shifts from being localization-centric to segmentation-centric. This strategy enables the incremental recovery of missing object parts and/or removal of extraneous parts through iteration. Compared to its counterparts, our method is more versatile$\unicode{x2014}$it can be plugged into prior arts straightforwardly and consistently bring improvements. Experimental results on the challenging datasets of RefCOCO, RefCOCO+, and G-Ref demonstrate its advantage with respect to the state-of-the-art methods.
MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices
Mar 09, 2023High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation. However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models featuring a diverse set of 3D structures. We obtain precise 3D ground-truth shape without relying on high-end 3D scanners by utilising LEGO models with known geometry as the 3D structures for image capture. The distinct data modality offered by high-resolution RGB images and low-resolution depth maps captured on a mobile device, when combined with precise 3D geometry annotations, presents a unique opportunity for future research on high-fidelity 3D reconstruction. Furthermore, we evaluate a range of 3D reconstruction algorithms on the proposed dataset. Project page: http://code.active.vision/MobileBrick/
MOSE: A New Dataset for Video Object Segmentation in Complex Scenes
Feb 03, 2023Video object segmentation (VOS) aims at segmenting a particular object throughout the entire video clip sequence. The state-of-the-art VOS methods have achieved excellent performance (e.g., 90+% J&F) on existing datasets. However, since the target objects in these existing datasets are usually relatively salient, dominant, and isolated, VOS under complex scenes has rarely been studied. To revisit VOS and make it more applicable in the real world, we collect a new VOS dataset called coMplex video Object SEgmentation (MOSE) to study the tracking and segmenting objects in complex environments. MOSE contains 2,149 video clips and 5,200 objects from 36 categories, with 431,725 high-quality object segmentation masks. The most notable feature of MOSE dataset is complex scenes with crowded and occluded objects. The target objects in the videos are commonly occluded by others and disappear in some frames. To analyze the proposed MOSE dataset, we benchmark 18 existing VOS methods under 4 different settings on the proposed MOSE dataset and conduct comprehensive comparisons. The experiments show that current VOS algorithms cannot well perceive objects in complex scenes. For example, under the semi-supervised VOS setting, the highest J&F by existing state-of-the-art VOS methods is only 59.4% on MOSE, much lower than their ~90% J&F performance on DAVIS. The results reveal that although excellent performance has been achieved on existing benchmarks, there are unresolved challenges under complex scenes and more efforts are desired to explore these challenges in the future. The proposed MOSE dataset has been released at https://henghuiding.github.io/MOSE.
Real-Time Evaluation in Online Continual Learning: A New Paradigm
Feb 02, 2023



Current evaluations of Continual Learning (CL) methods typically assume that there is no constraint on training time and computation. This is an unrealistic assumption for any real-world setting, which motivates us to propose: a practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions. To do this, we evaluate current CL methods with respect to their computational costs. We hypothesize that under this new evaluation paradigm, computationally demanding CL approaches may perform poorly on streams with a varying distribution. We conduct extensive experiments on CLOC, a large-scale dataset containing 39 million time-stamped images with geolocation labels. We show that a simple baseline outperforms state-of-the-art CL methods under this evaluation, questioning the applicability of existing methods in realistic settings. In addition, we explore various CL components commonly used in the literature, including memory sampling strategies and regularization approaches. We find that all considered methods fail to be competitive against our simple baseline. This surprisingly suggests that the majority of existing CL literature is tailored to a specific class of streams that is not practical. We hope that the evaluation we provide will be the first step towards a paradigm shift to consider the computational cost in the development of online continual learning methods.
Open Vocabulary Semantic Segmentation with Patch Aligned Contrastive Learning
Dec 09, 2022We introduce Patch Aligned Contrastive Learning (PACL), a modified compatibility function for CLIP's contrastive loss, intending to train an alignment between the patch tokens of the vision encoder and the CLS token of the text encoder. With such an alignment, a model can identify regions of an image corresponding to a given text input, and therefore transfer seamlessly to the task of open vocabulary semantic segmentation without requiring any segmentation annotations during training. Using pre-trained CLIP encoders with PACL, we are able to set the state-of-the-art on the task of open vocabulary zero-shot segmentation on 4 different segmentation benchmarks: Pascal VOC, Pascal Context, COCO Stuff and ADE20K. Furthermore, we show that PACL is also applicable to image-level predictions and when used with a CLIP backbone, provides a general improvement in zero-shot classification accuracy compared to CLIP, across a suite of 12 image classification datasets.
Traditional Classification Neural Networks are Good Generators: They are Competitive with DDPMs and GANs
Dec 08, 2022Classifiers and generators have long been separated. We break down this separation and showcase that conventional neural network classifiers can generate high-quality images of a large number of categories, being comparable to the state-of-the-art generative models (e.g., DDPMs and GANs). We achieve this by computing the partial derivative of the classification loss function with respect to the input to optimize the input to produce an image. Since it is widely known that directly optimizing the inputs is similar to targeted adversarial attacks incapable of generating human-meaningful images, we propose a mask-based stochastic reconstruction module to make the gradients semantic-aware to synthesize plausible images. We further propose a progressive-resolution technique to guarantee fidelity, which produces photorealistic images. Furthermore, we introduce a distance metric loss and a non-trivial distribution loss to ensure classification neural networks can synthesize diverse and high-fidelity images. Using traditional neural network classifiers, we can generate good-quality images of 256$\times$256 resolution on ImageNet. Intriguingly, our method is also applicable to text-to-image generation by regarding image-text foundation models as generalized classifiers. Proving that classifiers have learned the data distribution and are ready for image generation has far-reaching implications, for classifiers are much easier to train than generative models like DDPMs and GANs. We don't even need to train classification models because tons of public ones are available for download. Also, this holds great potential for the interpretability and robustness of classifiers. Project page is at \url{https://classifier-as-generator.github.io/}.
Structure-Preserving 3D Garment Modeling with Neural Sewing Machines
Nov 12, 2022



3D Garment modeling is a critical and challenging topic in the area of computer vision and graphics, with increasing attention focused on garment representation learning, garment reconstruction, and controllable garment manipulation, whereas existing methods were constrained to model garments under specific categories or with relatively simple topologies. In this paper, we propose a novel Neural Sewing Machine (NSM), a learning-based framework for structure-preserving 3D garment modeling, which is capable of learning representations for garments with diverse shapes and topologies and is successfully applied to 3D garment reconstruction and controllable manipulation. To model generic garments, we first obtain sewing pattern embedding via a unified sewing pattern encoding module, as the sewing pattern can accurately describe the intrinsic structure and the topology of the 3D garment. Then we use a 3D garment decoder to decode the sewing pattern embedding into a 3D garment using the UV-position maps with masks. To preserve the intrinsic structure of the predicted 3D garment, we introduce an inner-panel structure-preserving loss, an inter-panel structure-preserving loss, and a surface-normal loss in the learning process of our framework. We evaluate NSM on the public 3D garment dataset with sewing patterns with diverse garment shapes and categories. Extensive experiments demonstrate that the proposed NSM is capable of representing 3D garments under diverse garment shapes and topologies, realistically reconstructing 3D garments from 2D images with the preserved structure, and accurately manipulating the 3D garment categories, shapes, and topologies, outperforming the state-of-the-art methods by a clear margin.
Bipartite Graph Reasoning GANs for Person Pose and Facial Image Synthesis
Nov 12, 2022We present a novel bipartite graph reasoning Generative Adversarial Network (BiGraphGAN) for two challenging tasks: person pose and facial image synthesis. The proposed graph generator consists of two novel blocks that aim to model the pose-to-pose and pose-to-image relations, respectively. Specifically, the proposed bipartite graph reasoning (BGR) block aims to reason the long-range cross relations between the source and target pose in a bipartite graph, which mitigates some of the challenges caused by pose deformation. Moreover, we propose a new interaction-and-aggregation (IA) block to effectively update and enhance the feature representation capability of both a person's shape and appearance in an interactive way. To further capture the change in pose of each part more precisely, we propose a novel part-aware bipartite graph reasoning (PBGR) block to decompose the task of reasoning the global structure transformation with a bipartite graph into learning different local transformations for different semantic body/face parts. Experiments on two challenging generation tasks with three public datasets demonstrate the effectiveness of the proposed methods in terms of objective quantitative scores and subjective visual realness. The source code and trained models are available at https://github.com/Ha0Tang/BiGraphGAN.
Holistically-Attracted Wireframe Parsing: From Supervised to Self-Supervised Learning
Oct 24, 2022This paper presents Holistically-Attracted Wireframe Parsing (HAWP) for 2D images using both fully supervised and self-supervised learning paradigms. At the core is a parsimonious representation that encodes a line segment using a closed-form 4D geometric vector, which enables lifting line segments in wireframe to an end-to-end trainable holistic attraction field that has built-in geometry-awareness, context-awareness and robustness. The proposed HAWP consists of three components: generating line segment and end-point proposal, binding line segment and end-point, and end-point-decoupled lines-of-interest verification. For self-supervised learning, a simulation-to-reality pipeline is exploited in which a HAWP is first trained using synthetic data and then used to ``annotate" wireframes in real images with Homographic Adaptation. With the self-supervised annotations, a HAWP model for real images is trained from scratch. In experiments, the proposed HAWP achieves state-of-the-art performance in both the Wireframe dataset and the YorkUrban dataset in fully-supervised learning. It also demonstrates a significantly better repeatability score than prior arts with much more efficient training in self-supervised learning. Furthermore, the self-supervised HAWP shows great potential for general wireframe parsing without onerous wireframe labels.
Learn what matters: cross-domain imitation learning with task-relevant embeddings
Sep 24, 2022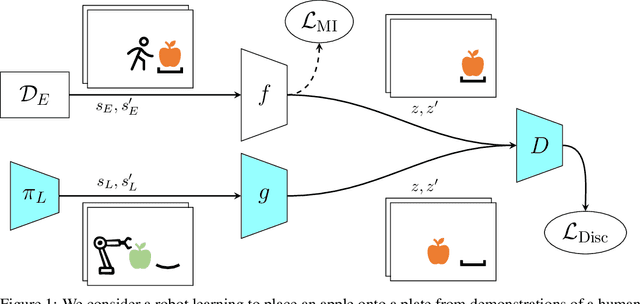

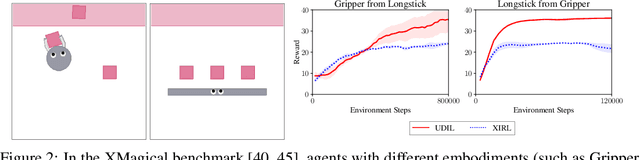
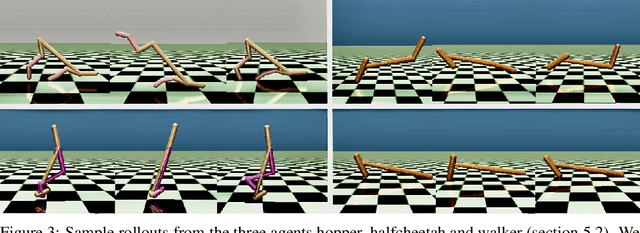
We study how an autonomous agent learns to perform a task from demonstrations in a different domain, such as a different environment or different agent. Such cross-domain imitation learning is required to, for example, train an artificial agent from demonstrations of a human expert. We propose a scalable framework that enables cross-domain imitation learning without access to additional demonstrations or further domain knowledge. We jointly train the learner agent's policy and learn a mapping between the learner and expert domains with adversarial training. We effect this by using a mutual information criterion to find an embedding of the expert's state space that contains task-relevant information and is invariant to domain specifics. This step significantly simplifies estimating the mapping between the learner and expert domains and hence facilitates end-to-end learning. We demonstrate successful transfer of policies between considerably different domains, without extra supervision such as additional demonstrations, and in situations where other methods fail.