 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Discrete Speech Representation Tokens for Accent Generation
Jan 27, 2026Discrete Speech Representation Tokens (DSRTs) have become a foundational component in speech generation. While prior work has extensively studied phonetic and speaker information in DSRTs, how accent information is encoded in DSRTs remains largely unexplored. In this paper, we present the first systematic investigation of accent information in DSRTs. We propose a unified evaluation framework that measures both accessibility of accent information via a novel Accent ABX task and recoverability via cross-accent Voice Conversion (VC) resynthesis. Using this framework, we analyse DSRTs derived from a variety of speech encoders. Our results reveal that accent information is substantially reduced when ASR supervision is used to fine-tune the encoder, but cannot be effectively disentangled from phonetic and speaker information through naive codebook size reduction. Based on these findings, we propose new content-only and content-accent DSRTs that significantly outperform existing designs in controllable accent generation. Our work highlights the importance of accent-aware evaluation and provides practical guidance for designing DSRTs for accent-controlled speech generation.
Segmentation-Variant Codebooks for Preservation of Paralinguistic and Prosodic Information
May 21, 2025Quantization in SSL speech models (e.g., HuBERT) improves compression and performance in tasks like language modeling, resynthesis, and text-to-speech but often discards prosodic and paralinguistic information (e.g., emotion, prominence). While increasing codebook size mitigates some loss, it inefficiently raises bitrates. We propose Segmentation-Variant Codebooks (SVCs), which quantize speech at distinct linguistic units (frame, phone, word, utterance), factorizing it into multiple streams of segment-specific discrete features. Our results show that SVCs are significantly more effective at preserving prosodic and paralinguistic information across probing tasks. Additionally, we find that pooling before rather than after discretization better retains segment-level information. Resynthesis experiments further confirm improved style realization and slightly improved quality while preserving intelligibility.
Pairwise Evaluation of Accent Similarity in Speech Synthesis
May 20, 2025



Despite growing interest in generating high-fidelity accents, evaluating accent similarity in speech synthesis has been underexplored. We aim to enhance both subjective and objective evaluation methods for accent similarity. Subjectively, we refine the XAB listening test by adding components that achieve higher statistical significance with fewer listeners and lower costs. Our method involves providing listeners with transcriptions, having them highlight perceived accent differences, and implementing meticulous screening for reliability. Objectively, we utilise pronunciation-related metrics, based on distances between vowel formants and phonetic posteriorgrams, to evaluate accent generation. Comparative experiments reveal that these metrics, alongside accent similarity, speaker similarity, and Mel Cepstral Distortion, can be used. Moreover, our findings underscore significant limitations of common metrics like Word Error Rate in assessing underrepresented accents.
Revisiting Acoustic Similarity in Emotional Speech and Music via Self-Supervised Representations
Sep 26, 2024



Emotion recognition from speech and music shares similarities due to their acoustic overlap, which has led to interest in transferring knowledge between these domains. However, the shared acoustic cues between speech and music, particularly those encoded by Self-Supervised Learning (SSL) models, remain largely unexplored, given the fact that SSL models for speech and music have rarely been applied in cross-domain research. In this work, we revisit the acoustic similarity between emotion speech and music, starting with an analysis of the layerwise behavior of SSL models for Speech Emotion Recognition (SER) and Music Emotion Recognition (MER). Furthermore, we perform cross-domain adaptation by comparing several approaches in a two-stage fine-tuning process, examining effective ways to utilize music for SER and speech for MER. Lastly, we explore the acoustic similarities between emotional speech and music using Frechet audio distance for individual emotions, uncovering the issue of emotion bias in both speech and music SSL models. Our findings reveal that while speech and music SSL models do capture shared acoustic features, their behaviors can vary depending on different emotions due to their training strategies and domain-specificities. Additionally, parameter-efficient fine-tuning can enhance SER and MER performance by leveraging knowledge from each other. This study provides new insights into the acoustic similarity between emotional speech and music, and highlights the potential for cross-domain generalization to improve SER and MER systems.
Cross-lingual Speech Emotion Recognition: Humans vs. Self-Supervised Models
Sep 25, 2024



Utilizing Self-Supervised Learning (SSL) models for Speech Emotion Recognition (SER) has proven effective, yet limited research has explored cross-lingual scenarios. This study presents a comparative analysis between human performance and SSL models, beginning with a layer-wise analysis and an exploration of parameter-efficient fine-tuning strategies in monolingual, cross-lingual, and transfer learning contexts. We further compare the SER ability of models and humans at both utterance- and segment-levels. Additionally, we investigate the impact of dialect on cross-lingual SER through human evaluation. Our findings reveal that models, with appropriate knowledge transfer, can adapt to the target language and achieve performance comparable to native speakers. We also demonstrate the significant effect of dialect on SER for individuals without prior linguistic and paralinguistic background. Moreover, both humans and models exhibit distinct behaviors across different emotions. These results offer new insights into the cross-lingual SER capabilities of SSL models, underscoring both their similarities to and differences from human emotion perception.
Acquiring Pronunciation Knowledge from Transcribed Speech Audio via Multi-task Learning
Sep 15, 2024



Recent work has shown the feasibility and benefit of bootstrapping an integrated sequence-to-sequence (Seq2Seq) linguistic frontend from a traditional pipeline-based frontend for text-to-speech (TTS). To overcome the fixed lexical coverage of bootstrapping training data, previous work has proposed to leverage easily accessible transcribed speech audio as an additional training source for acquiring novel pronunciation knowledge for uncovered words, which relies on an auxiliary ASR model as part of a cumbersome implementation flow. In this work, we propose an alternative method to leverage transcribed speech audio as an additional training source, based on multi-task learning (MTL). Experiments show that, compared to a baseline Seq2Seq frontend, the proposed MTL-based method reduces PER from 2.5% to 1.6% for those word types covered exclusively in transcribed speech audio, achieving a similar performance to the previous method but with a much simpler implementation flow.
AccentBox: Towards High-Fidelity Zero-Shot Accent Generation
Sep 13, 2024



While recent Zero-Shot Text-to-Speech (ZS-TTS) models have achieved high naturalness and speaker similarity, they fall short in accent fidelity and control. To address this issue, we propose zero-shot accent generation that unifies Foreign Accent Conversion (FAC), accented TTS, and ZS-TTS, with a novel two-stage pipeline. In the first stage, we achieve state-of-the-art (SOTA) on Accent Identification (AID) with 0.56 f1 score on unseen speakers. In the second stage, we condition ZS-TTS system on the pretrained speaker-agnostic accent embeddings extracted by the AID model. The proposed system achieves higher accent fidelity on inherent/cross accent generation, and enables unseen accent generation.
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Jun 13, 2024Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Dec 22, 2023



Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. In most cases, TTS systems are built using a single speaker's voice. However, there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper is the first to incorporate the representations from text-based and speech-based self-supervised learning models into multilingual speech synthesis tasks. We conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has been proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetical low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022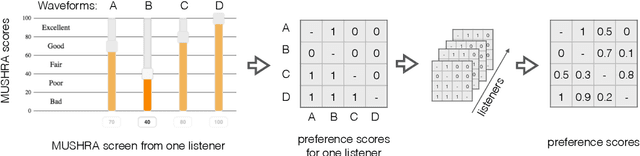
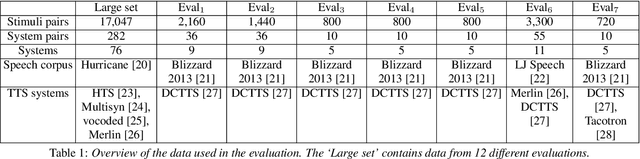
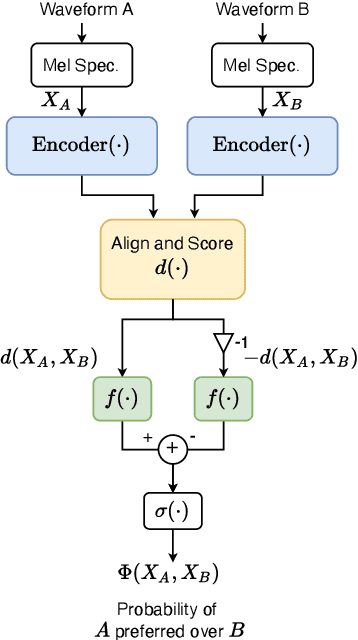
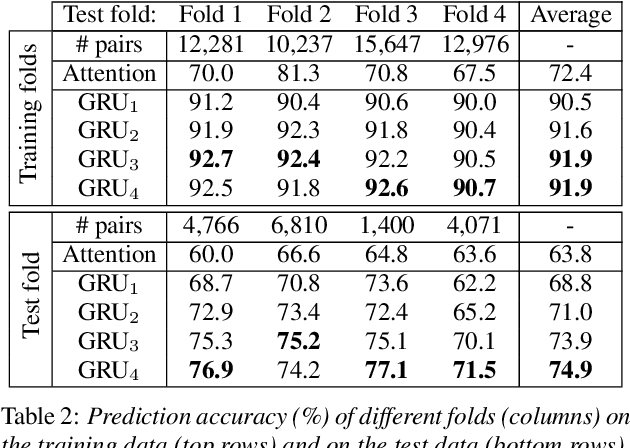
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.