 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning How to Remember: A Meta-Cognitive Management Method for Structured and Transferable Agent Memory
Jan 12, 2026Large language model (LLM) agents increasingly rely on accumulated memory to solve long-horizon decision-making tasks. However, most existing approaches store memory in fixed representations and reuse it at a single or implicit level of abstraction, which limits generalization and often leads to negative transfer when distribution shift. This paper proposes the Meta-Cognitive Memory Abstraction method (MCMA), which treats memory abstraction as a learnable cognitive skill rather than a fixed design choice. MCMA decouples task execution from memory management by combining a frozen task model with a learned memory copilot. The memory copilot is trained using direct preference optimization, it determines how memories should be structured, abstracted, and reused. Memories are further organized into a hierarchy of abstraction levels, enabling selective reuse based on task similarity. When no memory is transferable, MCMA transfers the ability to abstract and manage memory by transferring the memory copilot. Experiments on ALFWorld, ScienceWorld, and BabyAI demonstrate substantial improvements in performance, out-of-distribution generalization, and cross-task transfer over several baselines.
Bias-Restrained Prefix Representation Finetuning for Mathematical Reasoning
Nov 13, 2025



Parameter-Efficient finetuning (PEFT) enhances model performance on downstream tasks by updating a minimal subset of parameters. Representation finetuning (ReFT) methods further improve efficiency by freezing model weights and optimizing internal representations with fewer parameters than PEFT, outperforming PEFT on several tasks. However, ReFT exhibits a significant performance decline on mathematical reasoning tasks. To address this problem, the paper demonstrates that ReFT's poor performance on mathematical tasks primarily stems from its struggle to generate effective reasoning prefixes during the early inference phase. Moreover, ReFT disturbs the numerical encoding and the error accumulats during the CoT stage. Based on these observations, this paper proposes Bias-REstrained Prefix Representation FineTuning (BREP ReFT), which enhances ReFT's mathematical reasoning capability by truncating training data to optimize the generation of initial reasoning prefixes, intervening on the early inference stage to prevent error accumulation, and constraining the intervention vectors' magnitude to avoid disturbing numerical encoding. Extensive experiments across diverse model architectures demonstrate BREP's superior effectiveness, efficiency, and robust generalization capability, outperforming both standard ReFT and weight-based PEFT methods on the task of mathematical reasoning. The source code is available at https://github.com/LiangThree/BREP.
Know-MRI: A Knowledge Mechanisms Revealer&Interpreter for Large Language Models
Jun 10, 2025As large language models (LLMs) continue to advance, there is a growing urgency to enhance the interpretability of their internal knowledge mechanisms. Consequently, many interpretation methods have emerged, aiming to unravel the knowledge mechanisms of LLMs from various perspectives. However, current interpretation methods differ in input data formats and interpreting outputs. The tools integrating these methods are only capable of supporting tasks with specific inputs, significantly constraining their practical applications. To address these challenges, we present an open-source Knowledge Mechanisms Revealer&Interpreter (Know-MRI) designed to analyze the knowledge mechanisms within LLMs systematically. Specifically, we have developed an extensible core module that can automatically match different input data with interpretation methods and consolidate the interpreting outputs. It enables users to freely choose appropriate interpretation methods based on the inputs, making it easier to comprehensively diagnose the model's internal knowledge mechanisms from multiple perspectives. Our code is available at https://github.com/nlpkeg/Know-MRI. We also provide a demonstration video on https://youtu.be/NVWZABJ43Bs.
MMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
Large Language Models for Planning: A Comprehensive and Systematic Survey
May 26, 2025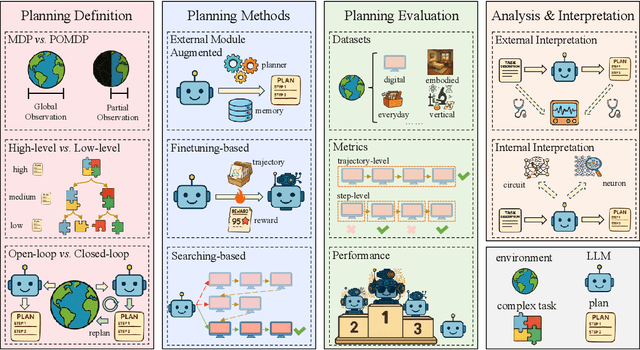
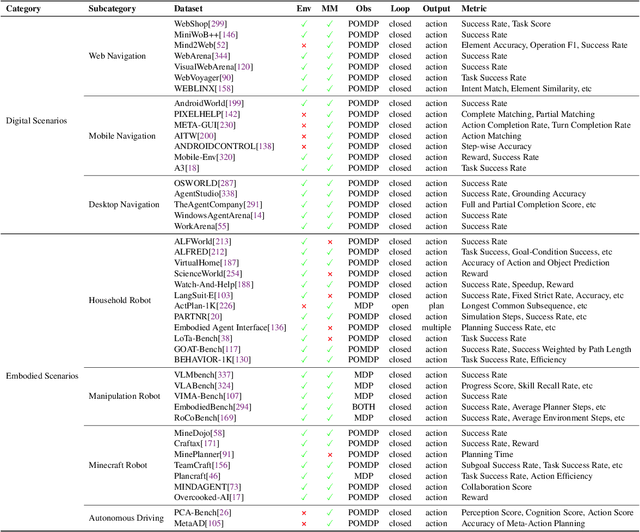
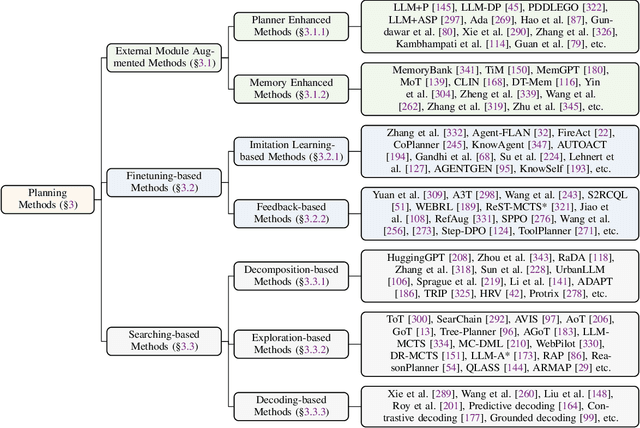
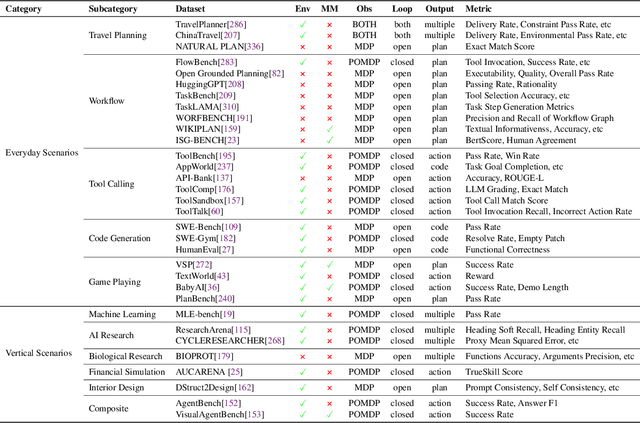
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
Revealing the Deceptiveness of Knowledge Editing: A Mechanistic Analysis of Superficial Editing
May 19, 2025Knowledge editing, which aims to update the knowledge encoded in language models, can be deceptive. Despite the fact that many existing knowledge editing algorithms achieve near-perfect performance on conventional metrics, the models edited by them are still prone to generating original knowledge. This paper introduces the concept of "superficial editing" to describe this phenomenon. Our comprehensive evaluation reveals that this issue presents a significant challenge to existing algorithms. Through systematic investigation, we identify and validate two key factors contributing to this issue: (1) the residual stream at the last subject position in earlier layers and (2) specific attention modules in later layers. Notably, certain attention heads in later layers, along with specific left singular vectors in their output matrices, encapsulate the original knowledge and exhibit a causal relationship with superficial editing. Furthermore, we extend our analysis to the task of superficial unlearning, where we observe consistent patterns in the behavior of specific attention heads and their corresponding left singular vectors, thereby demonstrating the robustness and broader applicability of our methodology and conclusions. Our code is available here.
Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
Mar 07, 2025Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.
The Knowledge Microscope: Features as Better Analytical Lenses than Neurons
Feb 18, 2025Previous studies primarily utilize MLP neurons as units of analysis for understanding the mechanisms of factual knowledge in Language Models (LMs); however, neurons suffer from polysemanticity, leading to limited knowledge expression and poor interpretability. In this paper, we first conduct preliminary experiments to validate that Sparse Autoencoders (SAE) can effectively decompose neurons into features, which serve as alternative analytical units. With this established, our core findings reveal three key advantages of features over neurons: (1) Features exhibit stronger influence on knowledge expression and superior interpretability. (2) Features demonstrate enhanced monosemanticity, showing distinct activation patterns between related and unrelated facts. (3) Features achieve better privacy protection than neurons, demonstrated through our proposed FeatureEdit method, which significantly outperforms existing neuron-based approaches in erasing privacy-sensitive information from LMs.Code and dataset will be available.
RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
Dec 18, 2024



Despite the significant progress made by existing retrieval augmented language models (RALMs) in providing trustworthy responses and grounding in reliable sources, they often overlook effective alignment with human preferences. In the alignment process, reward models (RMs) act as a crucial proxy for human values to guide optimization. However, it remains unclear how to evaluate and select a reliable RM for preference alignment in RALMs. To this end, we propose RAG-RewardBench, the first benchmark for evaluating RMs in RAG settings. First, we design four crucial and challenging RAG-specific scenarios to assess RMs, including multi-hop reasoning, fine-grained citation, appropriate abstain, and conflict robustness. Then, we incorporate 18 RAG subsets, six retrievers, and 24 RALMs to increase the diversity of data sources. Finally, we adopt an LLM-as-a-judge approach to improve preference annotation efficiency and effectiveness, exhibiting a strong correlation with human annotations. Based on the RAG-RewardBench, we conduct a comprehensive evaluation of 45 RMs and uncover their limitations in RAG scenarios. Additionally, we also reveal that existing trained RALMs show almost no improvement in preference alignment, highlighting the need for a shift towards preference-aligned training.We release our benchmark and code publicly at https://huggingface.co/datasets/jinzhuoran/RAG-RewardBench/ for future work.
One Mind, Many Tongues: A Deep Dive into Language-Agnostic Knowledge Neurons in Large Language Models
Nov 26, 2024



Large language models (LLMs) have learned vast amounts of factual knowledge through self-supervised pre-training on large-scale corpora. Meanwhile, LLMs have also demonstrated excellent multilingual capabilities, which can express the learned knowledge in multiple languages. However, the knowledge storage mechanism in LLMs still remains mysterious. Some researchers attempt to demystify the factual knowledge in LLMs from the perspective of knowledge neurons, and subsequently discover language-agnostic knowledge neurons that store factual knowledge in a form that transcends language barriers. However, the preliminary finding suffers from two limitations: 1) High Uncertainty in Localization Results. Existing study only uses a prompt-based probe to localize knowledge neurons for each fact, while LLMs cannot provide consistent answers for semantically equivalent queries. Thus, it leads to inaccurate localization results with high uncertainty. 2) Lack of Analysis in More Languages. The study only analyzes language-agnostic knowledge neurons on English and Chinese data, without exploring more language families and languages. Naturally, it limits the generalizability of the findings. To address aforementioned problems, we first construct a new benchmark called Rephrased Multilingual LAMA (RML-LAMA), which contains high-quality cloze-style multilingual parallel queries for each fact. Then, we propose a novel method named Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE), which quantifies the uncertainty across queries and languages during knowledge localization. Extensive experiments show that our method can accurately localize language-agnostic knowledge neurons. We also further investigate the role of language-agnostic knowledge neurons in cross-lingual knowledge editing, knowledge enhancement and new knowledge injection.