 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunque DeepResearch Technical Report
Jan 27, 2026Deep research has emerged as a transformative capability for autonomous agents, empowering Large Language Models to navigate complex, open-ended tasks. However, realizing its full potential is hindered by critical limitations, including escalating contextual noise in long-horizon tasks, fragility leading to cascading errors, and a lack of modular extensibility. To address these challenges, we introduce Yunque DeepResearch, a hierarchical, modular, and robust framework. The architecture is characterized by three key components: (1) a centralized Multi-Agent Orchestration System that routes subtasks to an Atomic Capability Pool of tools and specialized sub-agents; (2) a Dynamic Context Management mechanism that structures completed sub-goals into semantic summaries to mitigate information overload; and (3) a proactive Supervisor Module that ensures resilience through active anomaly detection and context pruning. Yunque DeepResearch achieves state-of-the-art performance across a range of agentic deep research benchmarks, including GAIA, BrowseComp, BrowseComp-ZH, and Humanity's Last Exam. We open-source the framework, reproducible implementations, and application cases to empower the community.
An Integrated Sensing and Communications System Based on Affine Frequency Division Multiplexing
Jan 31, 2025



This paper proposes an integrated sensing and communications (ISAC) system based on affine frequency division multiplexing (AFDM) waveform. To this end, a metric set is designed according to not only the maximum tolerable delay/Doppler, but also the weighted spectral efficiency as well as the outage/error probability of sensing and communications. This enables the analytical investigation of the performance trade-offs of AFDM-ISAC system using the derived analytical relation among metrics and AFDM waveform parameters. Moreover, by revealing that delay and the integral/fractional parts of normalized Doppler can be decoupled in the affine Fourier transform-Doppler domain, an efficient estimation method is proposed for our AFDM-ISAC system, whose unambiguous Doppler can break through the limitation of subcarrier spacing. Theoretical analyses and numerical results verify that our proposed AFDM-ISAC system may significantly enlarge unambiguous delay/Doppler while possessing good spectral efficiency and peak-to-sidelobe level ratio in high-mobility scenarios.
MDS-GNN: A Mutual Dual-Stream Graph Neural Network on Graphs with Incomplete Features and Structure
Aug 09, 2024Graph Neural Networks (GNNs) have emerged as powerful tools for analyzing and learning representations from graph-structured data. A crucial prerequisite for the outstanding performance of GNNs is the availability of complete graph information, i.e., node features and graph structure, which is frequently unmet in real-world scenarios since graphs are often incomplete due to various uncontrollable factors. Existing approaches only focus on dealing with either incomplete features or incomplete structure, which leads to performance loss inevitably. To address this issue, this study proposes a mutual dual-stream graph neural network (MDS-GNN), which implements a mutual benefit learning between features and structure. Its main ideas are as follows: a) reconstructing the missing node features based on the initial incomplete graph structure; b) generating an augmented global graph based on the reconstructed node features, and propagating the incomplete node features on this global graph; and c) utilizing contrastive learning to make the dual-stream process mutually benefit from each other. Extensive experiments on six real-world datasets demonstrate the effectiveness of our proposed MDS-GNN on incomplete graphs.
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024



Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
Amplify Graph Learning for Recommendation via Sparsity Completion
Jun 27, 2024



Graph learning models have been widely deployed in collaborative filtering (CF) based recommendation systems. Due to the issue of data sparsity, the graph structure of the original input lacks potential positive preference edges, which significantly reduces the performance of recommendations. In this paper, we study how to enhance the graph structure for CF more effectively, thereby optimizing the representation of graph nodes. Previous works introduced matrix completion techniques into CF, proposing the use of either stochastic completion methods or superficial structure completion to address this issue. However, most of these approaches employ random numerical filling that lack control over noise perturbations and limit the in-depth exploration of higher-order interaction features of nodes, resulting in biased graph representations. In this paper, we propose an Amplify Graph Learning framework based on Sparsity Completion (called AGL-SC). First, we utilize graph neural network to mine direct interaction features between user and item nodes, which are used as the inputs of the encoder. Second, we design a factorization-based method to mine higher-order interaction features. These features serve as perturbation factors in the latent space of the hidden layer to facilitate generative enhancement. Finally, by employing the variational inference, the above multi-order features are integrated to implement the completion and enhancement of missing graph structures. We conducted benchmark and strategy experiments on four real-world datasets related to recommendation tasks. The experimental results demonstrate that AGL-SC significantly outperforms the state-of-the-art methods.
An AFDM-Based Integrated Sensing and Communications
Aug 29, 2022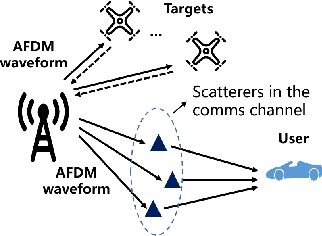
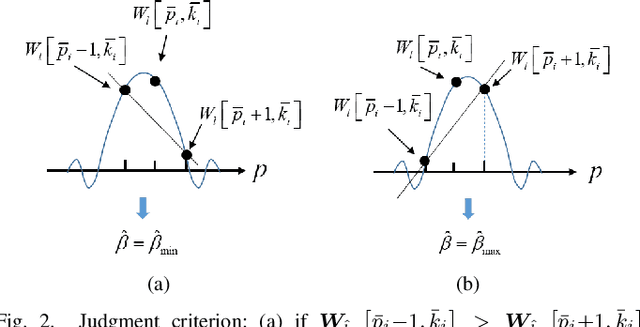
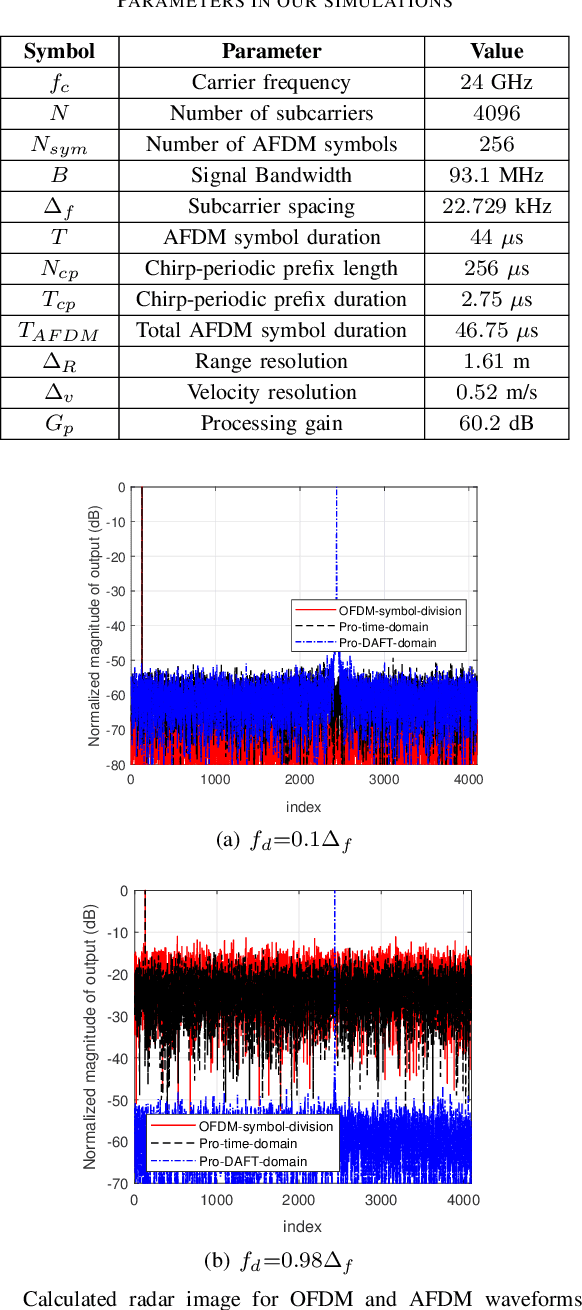
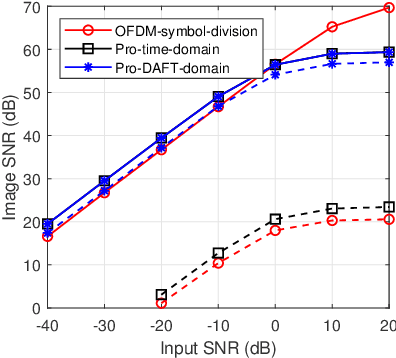
This paper considers an affine frequency division multiplexing (AFDM)-based integrated sensing and communications (ISAC) system, where the AFDM waveform is used to simultaneously carry communications information and sense targets. To realize AFDM-based sensing functionality, two parameter estimation methods are designed to process echoes in the time domain and the discrete affine Fourier transform (DAFT) domain, respectively. It allows us to decouple delay and Doppler shift in the fast time axis and can maintain good sensing performance even in large Doppler shift scenarios. Numerical results verify the effectiveness of our proposed AFDM-based system in high mobility scenarios.
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce
Apr 14, 2021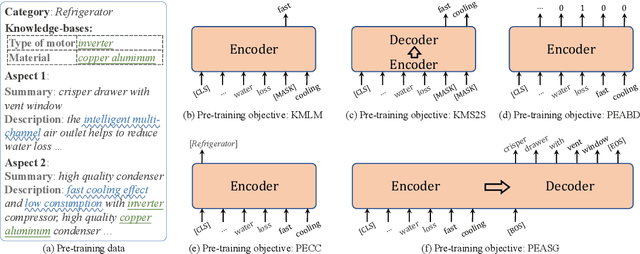
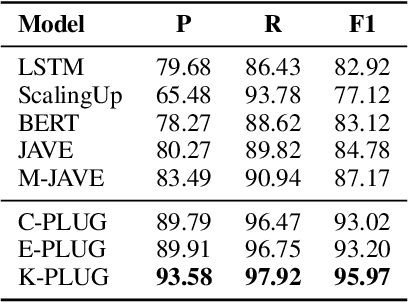
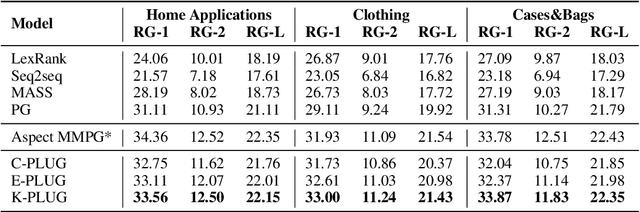
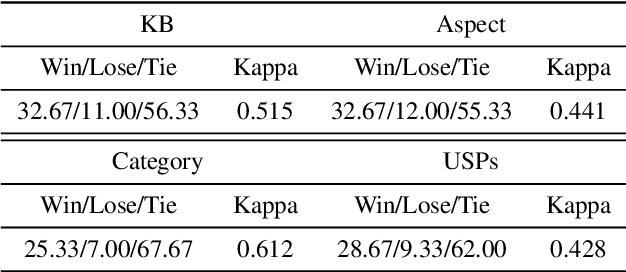
Existing pre-trained language models (PLMs) have demonstrated the effectiveness of self-supervised learning for a broad range of natural language processing (NLP) tasks. However, most of them are not explicitly aware of domain-specific knowledge, which is essential for downstream tasks in many domains, such as tasks in e-commerce scenarios. In this paper, we propose K-PLUG, a knowledge-injected pre-trained language model based on the encoder-decoder transformer that can be transferred to both natural language understanding and generation tasks. We verify our method in a diverse range of e-commerce scenarios that require domain-specific knowledge. Specifically, we propose five knowledge-aware self-supervised pre-training objectives to formulate the learning of domain-specific knowledge, including e-commerce domain-specific knowledge-bases, aspects of product entities, categories of product entities, and unique selling propositions of product entities. K-PLUG achieves new state-of-the-art results on a suite of domain-specific NLP tasks, including product knowledge base completion, abstractive product summarization, and multi-turn dialogue, significantly outperforms baselines across the board, which demonstrates that the proposed method effectively learns a diverse set of domain-specific knowledge for both language understanding and generation tasks.
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
Dec 10, 2020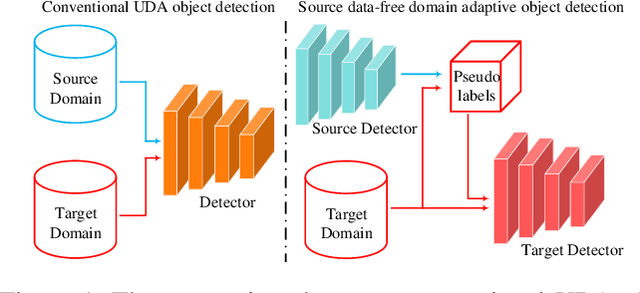
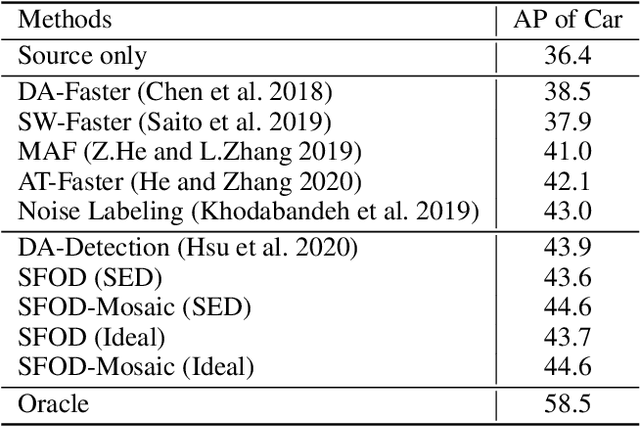
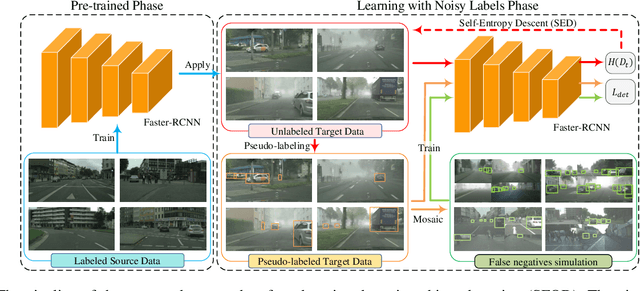
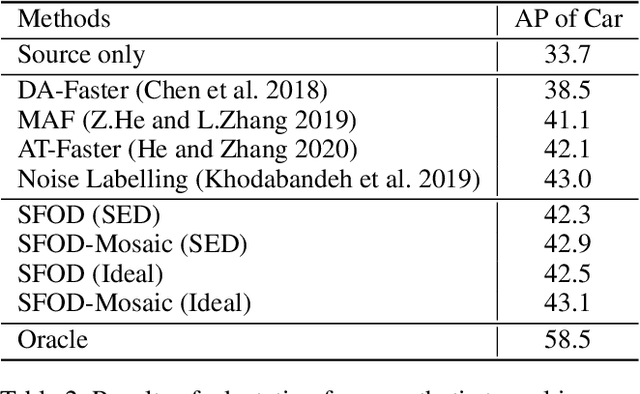
Unsupervised domain adaptation (UDA) assumes that source and target domain data are freely available and usually trained together to reduce the domain gap. However, considering the data privacy and the inefficiency of data transmission, it is impractical in real scenarios. Hence, it draws our eyes to optimize the network in the target domain without accessing labeled source data. To explore this direction in object detection, for the first time, we propose a source data-free domain adaptive object detection (SFOD) framework via modeling it into a problem of learning with noisy labels. Generally, a straightforward method is to leverage the pre-trained network from the source domain to generate the pseudo labels for target domain optimization. However, it is difficult to evaluate the quality of pseudo labels since no labels are available in target domain. In this paper, self-entropy descent (SED) is a metric proposed to search an appropriate confidence threshold for reliable pseudo label generation without using any handcrafted labels. Nonetheless, completely clean labels are still unattainable. After a thorough experimental analysis, false negatives are found to dominate in the generated noisy labels. Undoubtedly, false negatives mining is helpful for performance improvement, and we ease it to false negatives simulation through data augmentation like Mosaic. Extensive experiments conducted in four representative adaptation tasks have demonstrated that the proposed framework can easily achieve state-of-the-art performance. From another view, it also reminds the UDA community that the labeled source data are not fully exploited in the existing methods.
Efficient Privacy Preserving Viola-Jones Type Object Detection via Random Base Image Representation
Mar 30, 2017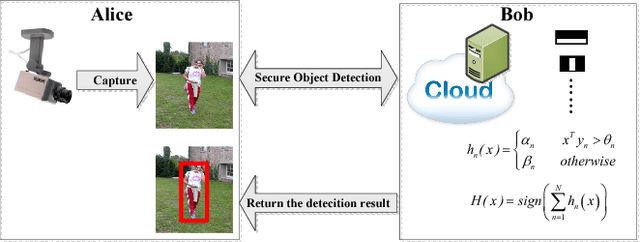
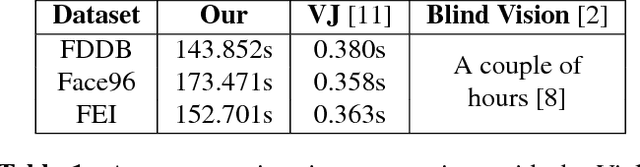
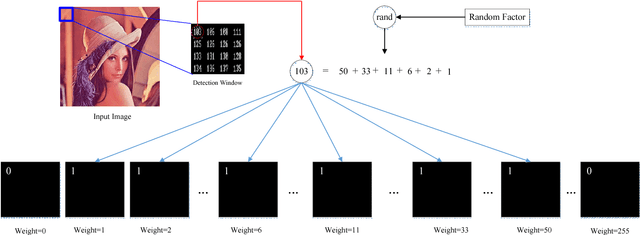
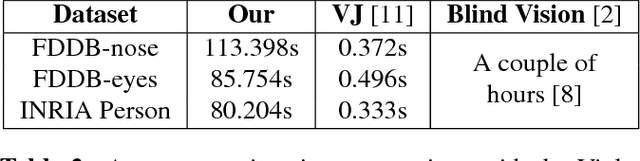
A cloud server spent a lot of time, energy and money to train a Viola-Jones type object detector with high accuracy. Clients can upload their photos to the cloud server to find objects. However, the client does not want the leakage of the content of his/her photos. In the meanwhile, the cloud server is also reluctant to leak any parameters of the trained object detectors. 10 years ago, Avidan & Butman introduced Blind Vision, which is a method for securely evaluating a Viola-Jones type object detector. Blind Vision uses standard cryptographic tools and is painfully slow to compute, taking a couple of hours to scan a single image. The purpose of this work is to explore an efficient method that can speed up the process. We propose the Random Base Image (RBI) Representation. The original image is divided into random base images. Only the base images are submitted randomly to the cloud server. Thus, the content of the image can not be leaked. In the meanwhile, a random vector and the secure Millionaire protocol are leveraged to protect the parameters of the trained object detector. The RBI makes the integral-image enable again for the great acceleration. The experimental results reveal that our method can retain the detection accuracy of that of the plain vision algorithm and is significantly faster than the traditional blind vision, with only a very low probability of the information leakage theoretically.
Discriminating between Nasal and Mouth Breathing
Aug 25, 2010


The recommendation to change breathing patterns from the mouth to the nose can have a significantly positive impact upon the general well being of the individual. We classify nasal and mouth breathing by using an acoustic sensor and intelligent signal processing techniques. The overall purpose is to investigate the possibility of identifying the differences in patterns between nasal and mouth breathing in order to integrate this information into a decision support system which will form the basis of a patient monitoring and motivational feedback system to recommend the change from mouth to nasal breathing. Our findings show that the breath pattern can be discriminated in certain places of the body both by visual spectrum analysis and with a Back Propagation neural network classifier. The sound file recoded from the sensor placed on the hollow in the neck shows the most promising accuracy which is as high as 90%.