 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce
Apr 14, 2021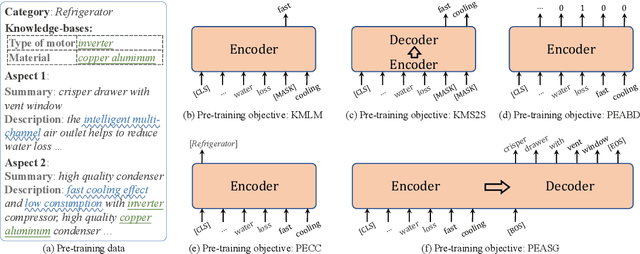
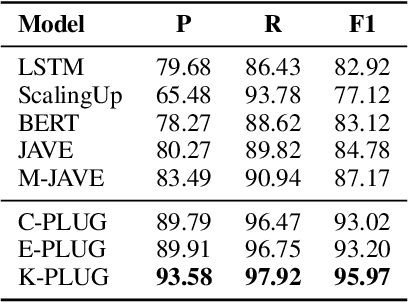
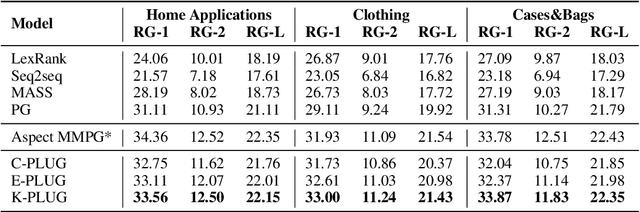
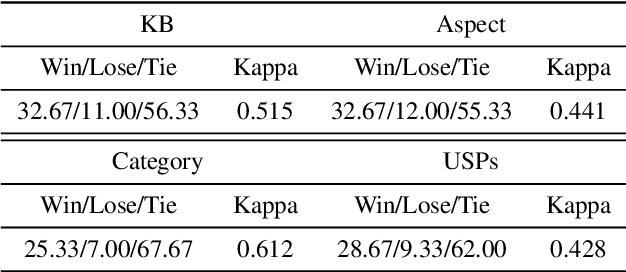
Existing pre-trained language models (PLMs) have demonstrated the effectiveness of self-supervised learning for a broad range of natural language processing (NLP) tasks. However, most of them are not explicitly aware of domain-specific knowledge, which is essential for downstream tasks in many domains, such as tasks in e-commerce scenarios. In this paper, we propose K-PLUG, a knowledge-injected pre-trained language model based on the encoder-decoder transformer that can be transferred to both natural language understanding and generation tasks. We verify our method in a diverse range of e-commerce scenarios that require domain-specific knowledge. Specifically, we propose five knowledge-aware self-supervised pre-training objectives to formulate the learning of domain-specific knowledge, including e-commerce domain-specific knowledge-bases, aspects of product entities, categories of product entities, and unique selling propositions of product entities. K-PLUG achieves new state-of-the-art results on a suite of domain-specific NLP tasks, including product knowledge base completion, abstractive product summarization, and multi-turn dialogue, significantly outperforms baselines across the board, which demonstrates that the proposed method effectively learns a diverse set of domain-specific knowledge for both language understanding and generation tasks.