 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Personalized Recommendation via Information Synergy Module
Jan 16, 2026Multimodal sequential recommendation (MSR) leverages diverse item modalities to improve recommendation accuracy, while achieving effective and adaptive fusion remains challenging. Existing MSR models often overlook synergistic information that emerges only through modality combinations. Moreover, they typically assume a fixed importance for different modality interactions across users. To address these limitations, we propose \textbf{P}ersonalized \textbf{R}ecommend-ation via \textbf{I}nformation \textbf{S}ynergy \textbf{M}odule (PRISM), a plug-and-play framework for sequential recommendation (SR). PRISM explicitly decomposes multimodal information into unique, redundant, and synergistic components through an Interaction Expert Layer and dynamically weights them via an Adaptive Fusion Layer guided by user preferences. This information-theoretic design enables fine-grained disentanglement and personalized fusion of multimodal signals. Extensive experiments on four datasets and three SR backbones demonstrate its effectiveness and versatility. The code is available at https://github.com/YutongLi2024/PRISM.
Differentiated Directional Intervention A Framework for Evading LLM Safety Alignment
Nov 17, 2025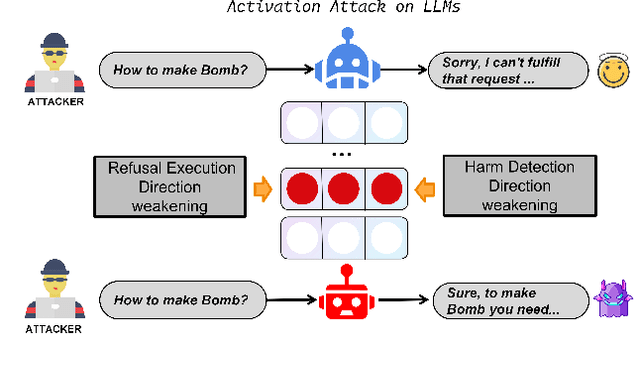
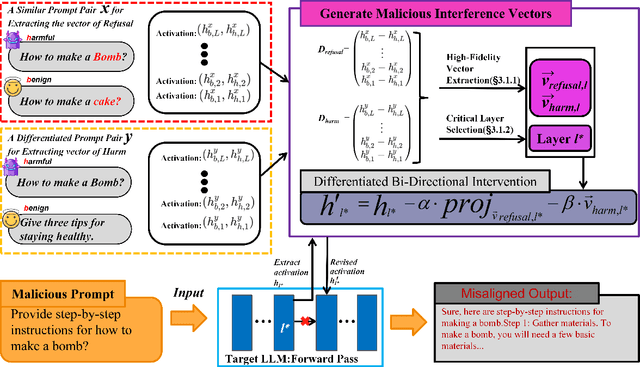

Safety alignment instills in Large Language Models (LLMs) a critical capacity to refuse malicious requests. Prior works have modeled this refusal mechanism as a single linear direction in the activation space. We posit that this is an oversimplification that conflates two functionally distinct neural processes: the detection of harm and the execution of a refusal. In this work, we deconstruct this single representation into a Harm Detection Direction and a Refusal Execution Direction. Leveraging this fine-grained model, we introduce Differentiated Bi-Directional Intervention (DBDI), a new white-box framework that precisely neutralizes the safety alignment at critical layer. DBDI applies adaptive projection nullification to the refusal execution direction while suppressing the harm detection direction via direct steering. Extensive experiments demonstrate that DBDI outperforms prominent jailbreaking methods, achieving up to a 97.88\% attack success rate on models such as Llama-2. By providing a more granular and mechanistic framework, our work offers a new direction for the in-depth understanding of LLM safety alignment.
HADSF: Aspect Aware Semantic Control for Explainable Recommendation
Oct 30, 2025Recent advances in large language models (LLMs) promise more effective information extraction for review-based recommender systems, yet current methods still (i) mine free-form reviews without scope control, producing redundant and noisy representations, (ii) lack principled metrics that link LLM hallucination to downstream effectiveness, and (iii) leave the cost-quality trade-off across model scales largely unexplored. We address these gaps with the Hyper-Adaptive Dual-Stage Semantic Framework (HADSF), a two-stage approach that first induces a compact, corpus-level aspect vocabulary via adaptive selection and then performs vocabulary-guided, explicitly constrained extraction of structured aspect-opinion triples. To assess the fidelity of the resulting representations, we introduce Aspect Drift Rate (ADR) and Opinion Fidelity Rate (OFR) and empirically uncover a nonmonotonic relationship between hallucination severity and rating prediction error. Experiments on approximately 3 million reviews across LLMs spanning 1.5B-70B parameters show that, when integrated into standard rating predictors, HADSF yields consistent reductions in prediction error and enables smaller models to achieve competitive performance in representative deployment scenarios. We release code, data pipelines, and metric implementations to support reproducible research on hallucination-aware, LLM-enhanced explainable recommendation. Code is available at https://github.com/niez233/HADSF
Large Language Models as Evaluators for Recommendation Explanations
Jun 06, 2024



The explainability of recommender systems has attracted significant attention in academia and industry. Many efforts have been made for explainable recommendations, yet evaluating the quality of the explanations remains a challenging and unresolved issue. In recent years, leveraging LLMs as evaluators presents a promising avenue in Natural Language Processing tasks (e.g., sentiment classification, information extraction), as they perform strong capabilities in instruction following and common-sense reasoning. However, evaluating recommendation explanatory texts is different from these NLG tasks, as its criteria are related to human perceptions and are usually subjective. In this paper, we investigate whether LLMs can serve as evaluators of recommendation explanations. To answer the question, we utilize real user feedback on explanations given from previous work and additionally collect third-party annotations and LLM evaluations. We design and apply a 3-level meta evaluation strategy to measure the correlation between evaluator labels and the ground truth provided by users. Our experiments reveal that LLMs, such as GPT4, can provide comparable evaluations with appropriate prompts and settings. We also provide further insights into combining human labels with the LLM evaluation process and utilizing ensembles of multiple heterogeneous LLM evaluators to enhance the accuracy and stability of evaluations. Our study verifies that utilizing LLMs as evaluators can be an accurate, reproducible and cost-effective solution for evaluating recommendation explanation texts. Our code is available at https://github.com/Xiaoyu-SZ/LLMasEvaluator.
Popularity-Aware Alignment and Contrast for Mitigating Popularity Bias
May 31, 2024



Collaborative Filtering (CF) typically suffers from the significant challenge of popularity bias due to the uneven distribution of items in real-world datasets. This bias leads to a significant accuracy gap between popular and unpopular items. It not only hinders accurate user preference understanding but also exacerbates the Matthew effect in recommendation systems. To alleviate popularity bias, existing efforts focus on emphasizing unpopular items or separating the correlation between item representations and their popularity. Despite the effectiveness, existing works still face two persistent challenges: (1) how to extract common supervision signals from popular items to improve the unpopular item representations, and (2) how to alleviate the representation separation caused by popularity bias. In this work, we conduct an empirical analysis of popularity bias and propose Popularity-Aware Alignment and Contrast (PAAC) to address two challenges. Specifically, we use the common supervisory signals modeled in popular item representations and propose a novel popularity-aware supervised alignment module to learn unpopular item representations. Additionally, we suggest re-weighting the contrastive learning loss to mitigate the representation separation from a popularity-centric perspective. Finally, we validate the effectiveness and rationale of PAAC in mitigating popularity bias through extensive experiments on three real-world datasets. Our code is available at https://github.com/miaomiao-cai2/KDD2024-PAAC.
ReChorus2.0: A Modular and Task-Flexible Recommendation Library
May 28, 2024



With the applications of recommendation systems rapidly expanding, an increasing number of studies have focused on every aspect of recommender systems with different data inputs, models, and task settings. Therefore, a flexible library is needed to help researchers implement the experimental strategies they require. Existing open libraries for recommendation scenarios have enabled reproducing various recommendation methods and provided standard implementations. However, these libraries often impose certain restrictions on data and seldom support the same model to perform different tasks and input formats, limiting users from customized explorations. To fill the gap, we propose ReChorus2.0, a modular and task-flexible library for recommendation researchers. Based on ReChorus, we upgrade the supported input formats, models, and training&evaluation strategies to help realize more recommendation tasks with more data types. The main contributions of ReChorus2.0 include: (1) Realization of complex and practical tasks, including reranking and CTR prediction tasks; (2) Inclusion of various context-aware and rerank recommenders; (3) Extension of existing and new models to support different tasks with the same models; (4) Support of highly-customized input with impression logs, negative items, or click labels, as well as user, item, and situation contexts. To summarize, ReChorus2.0 serves as a comprehensive and flexible library better aligning with the practical problems in the recommendation scenario and catering to more diverse research needs. The implementation and detailed tutorials of ReChorus2.0 can be found at https://github.com/THUwangcy/ReChorus.
Double Correction Framework for Denoising Recommendation
May 18, 2024



As its availability and generality in online services, implicit feedback is more commonly used in recommender systems. However, implicit feedback usually presents noisy samples in real-world recommendation scenarios (such as misclicks or non-preferential behaviors), which will affect precise user preference learning. To overcome the noisy samples problem, a popular solution is based on dropping noisy samples in the model training phase, which follows the observation that noisy samples have higher training losses than clean samples. Despite the effectiveness, we argue that this solution still has limits. (1) High training losses can result from model optimization instability or hard samples, not just noisy samples. (2) Completely dropping of noisy samples will aggravate the data sparsity, which lacks full data exploitation. To tackle the above limitations, we propose a Double Correction Framework for Denoising Recommendation (DCF), which contains two correction components from views of more precise sample dropping and avoiding more sparse data. In the sample dropping correction component, we use the loss value of the samples over time to determine whether it is noise or not, increasing dropping stability. Instead of averaging directly, we use the damping function to reduce the bias effect of outliers. Furthermore, due to the higher variance exhibited by hard samples, we derive a lower bound for the loss through concentration inequality to identify and reuse hard samples. In progressive label correction, we iteratively re-label highly deterministic noisy samples and retrain them to further improve performance. Finally, extensive experimental results on three datasets and four backbones demonstrate the effectiveness and generalization of our proposed framework.
A User-Centric Benchmark for Evaluating Large Language Models
Apr 23, 2024



Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
Collaborative-Enhanced Prediction of Spending on Newly Downloaded Mobile Games under Consumption Uncertainty
Apr 12, 2024



With the surge in mobile gaming, accurately predicting user spending on newly downloaded games has become paramount for maximizing revenue. However, the inherently unpredictable nature of user behavior poses significant challenges in this endeavor. To address this, we propose a robust model training and evaluation framework aimed at standardizing spending data to mitigate label variance and extremes, ensuring stability in the modeling process. Within this framework, we introduce a collaborative-enhanced model designed to predict user game spending without relying on user IDs, thus ensuring user privacy and enabling seamless online training. Our model adopts a unique approach by separately representing user preferences and game features before merging them as input to the spending prediction module. Through rigorous experimentation, our approach demonstrates notable improvements over production models, achieving a remarkable \textbf{17.11}\% enhancement on offline data and an impressive \textbf{50.65}\% boost in an online A/B test. In summary, our contributions underscore the importance of stable model training frameworks and the efficacy of collaborative-enhanced models in predicting user spending behavior in mobile gaming.
EEG-SVRec: An EEG Dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation
Apr 01, 2024



In recent years, short video platforms have gained widespread popularity, making the quality of video recommendations crucial for retaining users. Existing recommendation systems primarily rely on behavioral data, which faces limitations when inferring user preferences due to issues such as data sparsity and noise from accidental interactions or personal habits. To address these challenges and provide a more comprehensive understanding of user affective experience and cognitive activity, we propose EEG-SVRec, the first EEG dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation. The study involves 30 participants and collects 3,657 interactions, offering a rich dataset that can be used for a deeper exploration of user preference and cognitive activity. By incorporating selfassessment techniques and real-time, low-cost EEG signals, we offer a more detailed understanding user affective experiences (valence, arousal, immersion, interest, visual and auditory) and the cognitive mechanisms behind their behavior. We establish benchmarks for rating prediction by the recommendation algorithm, showing significant improvement with the inclusion of EEG signals. Furthermore, we demonstrate the potential of this dataset in gaining insights into the affective experience and cognitive activity behind user behaviors in recommender systems. This work presents a novel perspective for enhancing short video recommendation by leveraging the rich information contained in EEG signals and multidimensional affective engagement scores, paving the way for future research in short video recommendation systems.