 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Robust Imperceptible Perturbation against Unauthorized Text-to-image Diffusion-based Synthesis
Nov 22, 2023



Text-to-image diffusion models allow seamless generation of personalized images from scant reference photos. Yet, these tools, in the wrong hands, can fabricate misleading or harmful content, endangering individuals. To address this problem, existing poisoning-based approaches perturb user images in an imperceptible way to render them "unlearnable" from malicious uses. We identify two limitations of these defending approaches: i) sub-optimal due to the hand-crafted heuristics for solving the intractable bilevel optimization and ii) lack of robustness against simple data transformations like Gaussian filtering. To solve these challenges, we propose MetaCloak, which solves the bi-level poisoning problem with a meta-learning framework with an additional transformation sampling process to craft transferable and robust perturbation. Specifically, we employ a pool of surrogate diffusion models to craft transferable and model-agnostic perturbation. Furthermore, by incorporating an additional transformation process, we design a simple denoising-error maximization loss that is sufficient for causing transformation-robust semantic distortion and degradation in a personalized generation. Extensive experiments on the VGGFace2 and CelebA-HQ datasets show that MetaCloak outperforms existing approaches. Notably, MetaCloak can successfully fool online training services like Replicate, in a black-box manner, demonstrating the effectiveness of MetaCloak in real-world scenarios. Our code is available at https://github.com/liuyixin-louis/MetaCloak.
Jailbreaking GPT-4V via Self-Adversarial Attacks with System Prompts
Nov 15, 2023Existing work on jailbreak Multimodal Large Language Models (MLLMs) has focused primarily on adversarial examples in model inputs, with less attention to vulnerabilities in model APIs. To fill the research gap, we carry out the following work: 1) We discover a system prompt leakage vulnerability in GPT-4V. Through carefully designed dialogue, we successfully steal the internal system prompts of GPT-4V. This finding indicates potential exploitable security risks in MLLMs; 2)Based on the acquired system prompts, we propose a novel MLLM jailbreaking attack method termed SASP (Self-Adversarial Attack via System Prompt). By employing GPT-4 as a red teaming tool against itself, we aim to search for potential jailbreak prompts leveraging stolen system prompts. Furthermore, in pursuit of better performance, we also add human modification based on GPT-4's analysis, which further improves the attack success rate to 98.7\%; 3) We evaluated the effect of modifying system prompts to defend against jailbreaking attacks. Results show that appropriately designed system prompts can significantly reduce jailbreak success rates. Overall, our work provides new insights into enhancing MLLM security, demonstrating the important role of system prompts in jailbreaking, which could be leveraged to greatly facilitate jailbreak success rates while also holding the potential for defending against jailbreaks.
Instant3D: Instant Text-to-3D Generation
Nov 14, 2023



Text-to-3D generation, which aims to synthesize vivid 3D objects from text prompts, has attracted much attention from the computer vision community. While several existing works have achieved impressive results for this task, they mainly rely on a time-consuming optimization paradigm. Specifically, these methods optimize a neural field from scratch for each text prompt, taking approximately one hour or more to generate one object. This heavy and repetitive training cost impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The project page is at https://ming1993li.github.io/Instant3DProj.
F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Oct 23, 2023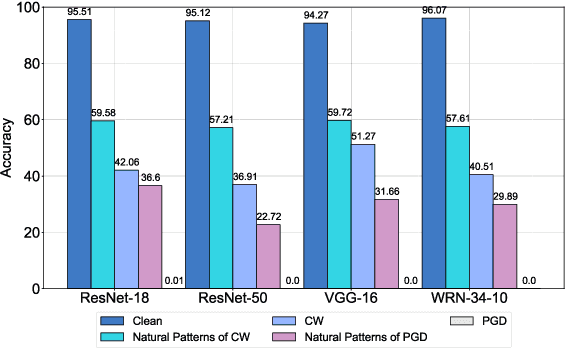

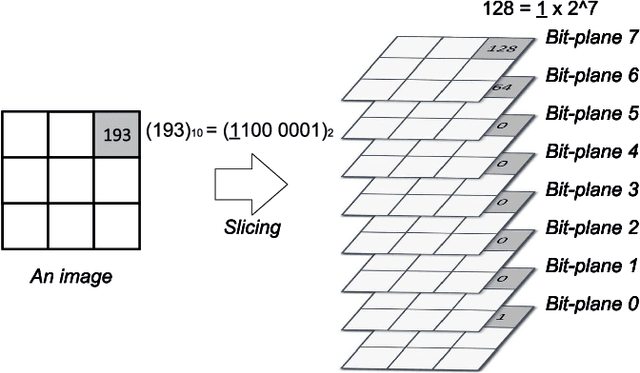
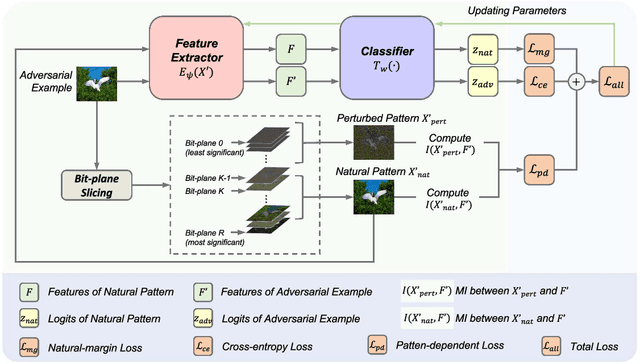
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.
ScaleLong: Towards More Stable Training of Diffusion Model via Scaling Network Long Skip Connection
Oct 20, 2023In diffusion models, UNet is the most popular network backbone, since its long skip connects (LSCs) to connect distant network blocks can aggregate long-distant information and alleviate vanishing gradient. Unfortunately, UNet often suffers from unstable training in diffusion models which can be alleviated by scaling its LSC coefficients smaller. However, theoretical understandings of the instability of UNet in diffusion models and also the performance improvement of LSC scaling remain absent yet. To solve this issue, we theoretically show that the coefficients of LSCs in UNet have big effects on the stableness of the forward and backward propagation and robustness of UNet. Specifically, the hidden feature and gradient of UNet at any layer can oscillate and their oscillation ranges are actually large which explains the instability of UNet training. Moreover, UNet is also provably sensitive to perturbed input, and predicts an output distant from the desired output, yielding oscillatory loss and thus oscillatory gradient. Besides, we also observe the theoretical benefits of the LSC coefficient scaling of UNet in the stableness of hidden features and gradient and also robustness. Finally, inspired by our theory, we propose an effective coefficient scaling framework ScaleLong that scales the coefficients of LSC in UNet and better improves the training stability of UNet. Experimental results on four famous datasets show that our methods are superior to stabilize training and yield about 1.5x training acceleration on different diffusion models with UNet or UViT backbones. Code: https://github.com/sail-sg/ScaleLong
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use
Oct 12, 2023



Large language models (LLMs) have garnered significant attention due to their impressive natural language processing (NLP) capabilities. Recently, many studies have focused on the tool utilization ability of LLMs. They primarily investigated how LLMs effectively collaborate with given specific tools. However, in scenarios where LLMs serve as intelligent agents, as seen in applications like AutoGPT and MetaGPT, LLMs are expected to engage in intricate decision-making processes that involve deciding whether to employ a tool and selecting the most suitable tool(s) from a collection of available tools to fulfill user requests. Therefore, in this paper, we introduce MetaTool, a benchmark designed to evaluate whether LLMs have tool usage awareness and can correctly choose tools. Specifically, we create a dataset called ToolE within the benchmark. This dataset contains various types of user queries in the form of prompts that trigger LLMs to use tools, including both single-tool and multi-tool scenarios. Subsequently, we set the tasks for both tool usage awareness and tool selection. We define four subtasks from different perspectives in tool selection, including tool selection with similar choices, tool selection in specific scenarios, tool selection with possible reliability issues, and multi-tool selection. We conduct experiments involving nine popular LLMs and find that the majority of them still struggle to effectively select tools, highlighting the existing gaps between LLMs and genuine intelligent agents. However, through the error analysis, we found there is still significant room for improvement. Finally, we conclude with insights for tool developers that follow ChatGPT to provide detailed descriptions that can enhance the tool selection performance of LLMs.
3DHacker: Spectrum-based Decision Boundary Generation for Hard-label 3D Point Cloud Attack
Aug 15, 2023



With the maturity of depth sensors, the vulnerability of 3D point cloud models has received increasing attention in various applications such as autonomous driving and robot navigation. Previous 3D adversarial attackers either follow the white-box setting to iteratively update the coordinate perturbations based on gradients, or utilize the output model logits to estimate noisy gradients in the black-box setting. However, these attack methods are hard to be deployed in real-world scenarios since realistic 3D applications will not share any model details to users. Therefore, we explore a more challenging yet practical 3D attack setting, \textit{i.e.}, attacking point clouds with black-box hard labels, in which the attacker can only have access to the prediction label of the input. To tackle this setting, we propose a novel 3D attack method, termed \textbf{3D} \textbf{H}ard-label att\textbf{acker} (\textbf{3DHacker}), based on the developed decision boundary algorithm to generate adversarial samples solely with the knowledge of class labels. Specifically, to construct the class-aware model decision boundary, 3DHacker first randomly fuses two point clouds of different classes in the spectral domain to craft their intermediate sample with high imperceptibility, then projects it onto the decision boundary via binary search. To restrict the final perturbation size, 3DHacker further introduces an iterative optimization strategy to move the intermediate sample along the decision boundary for generating adversarial point clouds with smallest trivial perturbations. Extensive evaluations show that, even in the challenging hard-label setting, 3DHacker still competitively outperforms existing 3D attacks regarding the attack performance as well as adversary quality.
Graph Agent Network: Empowering Nodes with Decentralized Communications Capabilities for Adversarial Resilience
Jun 12, 2023End-to-end training with global optimization have popularized graph neural networks (GNNs) for node classification, yet inadvertently introduced vulnerabilities to adversarial edge-perturbing attacks. Adversaries can exploit the inherent opened interfaces of GNNs' input and output, perturbing critical edges and thus manipulating the classification results. Current defenses, due to their persistent utilization of global-optimization-based end-to-end training schemes, inherently encapsulate the vulnerabilities of GNNs. This is specifically evidenced in their inability to defend against targeted secondary attacks. In this paper, we propose the Graph Agent Network (GAgN) to address the aforementioned vulnerabilities of GNNs. GAgN is a graph-structured agent network in which each node is designed as an 1-hop-view agent. Through the decentralized interactions between agents, they can learn to infer global perceptions to perform tasks including inferring embeddings, degrees and neighbor relationships for given nodes. This empowers nodes to filtering adversarial edges while carrying out classification tasks. Furthermore, agents' limited view prevents malicious messages from propagating globally in GAgN, thereby resisting global-optimization-based secondary attacks. We prove that single-hidden-layer multilayer perceptrons (MLPs) are theoretically sufficient to achieve these functionalities. Experimental results show that GAgN effectively implements all its intended capabilities and, compared to state-of-the-art defenses, achieves optimal classification accuracy on the perturbed datasets.
Fast Diffusion Model
Jun 12, 2023



Despite their success in real data synthesis, diffusion models (DMs) often suffer from slow and costly training and sampling issues, limiting their broader applications. To mitigate this, we propose a Fast Diffusion Model (FDM) which improves the diffusion process of DMs from a stochastic optimization perspective to speed up both training and sampling. Specifically, we first find that the diffusion process of DMs accords with the stochastic optimization process of stochastic gradient descent (SGD) on a stochastic time-variant problem. Note that momentum SGD uses both the current gradient and an extra momentum, achieving more stable and faster convergence. We are inspired to introduce momentum into the diffusion process to accelerate both training and sampling. However, this comes with the challenge of deriving the noise perturbation kernel from the momentum-based diffusion process. To this end, we frame the momentum-based process as a Damped Oscillation system whose critically damped state -- the kernel solution -- avoids oscillation and thus has a faster convergence speed of the diffusion process. Empirical results show that our FDM can be applied to several popular DM frameworks, e.g. VP, VE, and EDM, and reduces their training cost by about 50% with comparable image synthesis performance on CIFAR-10, FFHQ, and AFHQv2 datasets. Moreover, FDM decreases their sampling steps by about $3\times$ to achieve similar performance under the same deterministic samplers. The code is available at https://github.com/sail-sg/FDM.
Transform-Equivariant Consistency Learning for Temporal Sentence Grounding
May 06, 2023This paper addresses the temporal sentence grounding (TSG). Although existing methods have made decent achievements in this task, they not only severely rely on abundant video-query paired data for training, but also easily fail into the dataset distribution bias. To alleviate these limitations, we introduce a novel Equivariant Consistency Regulation Learning (ECRL) framework to learn more discriminative query-related frame-wise representations for each video, in a self-supervised manner. Our motivation comes from that the temporal boundary of the query-guided activity should be consistently predicted under various video-level transformations. Concretely, we first design a series of spatio-temporal augmentations on both foreground and background video segments to generate a set of synthetic video samples. In particular, we devise a self-refine module to enhance the completeness and smoothness of the augmented video. Then, we present a novel self-supervised consistency loss (SSCL) applied on the original and augmented videos to capture their invariant query-related semantic by minimizing the KL-divergence between the sequence similarity of two videos and a prior Gaussian distribution of timestamp distance. At last, a shared grounding head is introduced to predict the transform-equivariant query-guided segment boundaries for both the original and augmented videos. Extensive experiments on three challenging datasets (ActivityNet, TACoS, and Charades-STA) demonstrate both effectiveness and efficiency of our proposed ECRL framework.