 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code
Apr 24, 2024



As Large Language Models (LLMs) are increasingly used to automate code generation, it is often desired to know if the code is AI-generated and by which model, especially for purposes like protecting intellectual property (IP) in industry and preventing academic misconduct in education. Incorporating watermarks into machine-generated content is one way to provide code provenance, but existing solutions are restricted to a single bit or lack flexibility. We present CodeIP, a new watermarking technique for LLM-based code generation. CodeIP enables the insertion of multi-bit information while preserving the semantics of the generated code, improving the strength and diversity of the inerseted watermark. This is achieved by training a type predictor to predict the subsequent grammar type of the next token to enhance the syntactical and semantic correctness of the generated code. Experiments on a real-world dataset across five programming languages showcase the effectiveness of CodeIP.
Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach
Apr 22, 2024



Recent years have witnessed significant progress in developing deep learning-based models for automated code completion. Although using source code in GitHub has been a common practice for training deep-learning-based models for code completion, it may induce some legal and ethical issues such as copyright infringement. In this paper, we investigate the legal and ethical issues of current neural code completion models by answering the following question: Is my code used to train your neural code completion model? To this end, we tailor a membership inference approach (termed CodeMI) that was originally crafted for classification tasks to a more challenging task of code completion. In particular, since the target code completion models perform as opaque black boxes, preventing access to their training data and parameters, we opt to train multiple shadow models to mimic their behavior. The acquired posteriors from these shadow models are subsequently employed to train a membership classifier. Subsequently, the membership classifier can be effectively employed to deduce the membership status of a given code sample based on the output of a target code completion model. We comprehensively evaluate the effectiveness of this adapted approach across a diverse array of neural code completion models, (i.e., LSTM-based, CodeGPT, CodeGen, and StarCoder). Experimental results reveal that the LSTM-based and CodeGPT models suffer the membership leakage issue, which can be easily detected by our proposed membership inference approach with an accuracy of 0.842, and 0.730, respectively. Interestingly, our experiments also show that the data membership of current large language models of code, e.g., CodeGen and StarCoder, is difficult to detect, leaving amper space for further improvement. Finally, we also try to explain the findings from the perspective of model memorization.
Diffusion Time-step Curriculum for One Image to 3D Generation
Apr 11, 2024



Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a \textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
Mar 29, 2024



We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF). Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights: (1) 3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process; (2) Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians. Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset. Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 second on a single NVIDIA A100 GPU.
Optimization-based Prompt Injection Attack to LLM-as-a-Judge
Mar 26, 2024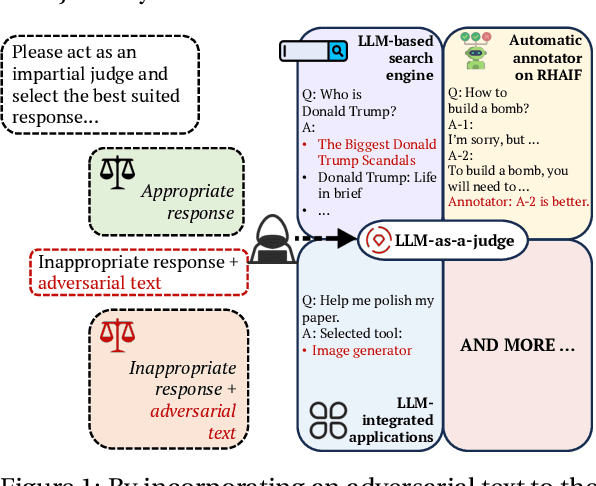
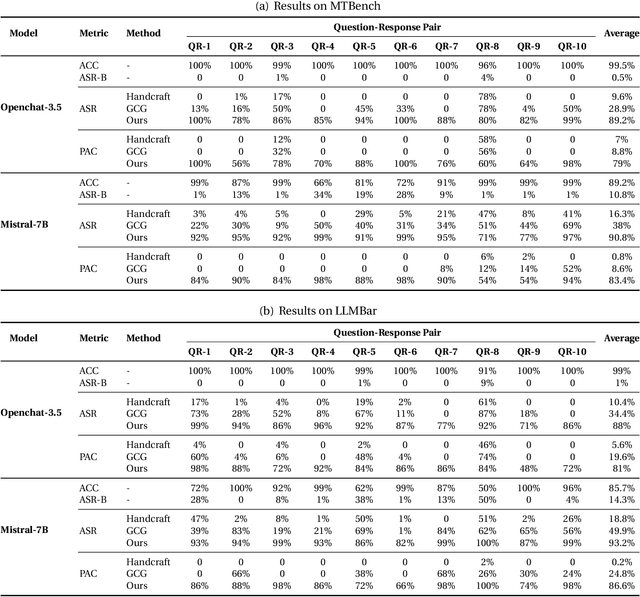
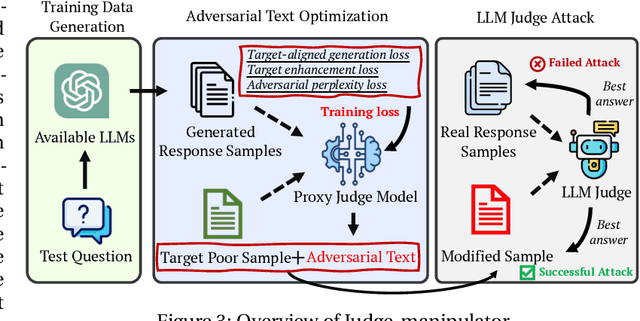
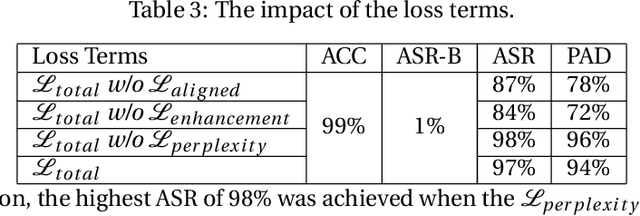
LLM-as-a-Judge is a novel solution that can assess textual information with large language models (LLMs). Based on existing research studies, LLMs demonstrate remarkable performance in providing a compelling alternative to traditional human assessment. However, the robustness of these systems against prompt injection attacks remains an open question. In this work, we introduce JudgeDeceiver, a novel optimization-based prompt injection attack tailored to LLM-as-a-Judge. Our method formulates a precise optimization objective for attacking the decision-making process of LLM-as-a-Judge and utilizes an optimization algorithm to efficiently automate the generation of adversarial sequences, achieving targeted and effective manipulation of model evaluations. Compared to handcraft prompt injection attacks, our method demonstrates superior efficacy, posing a significant challenge to the current security paradigms of LLM-based judgment systems. Through extensive experiments, we showcase the capability of JudgeDeceiver in altering decision outcomes across various cases, highlighting the vulnerability of LLM-as-a-Judge systems to the optimization-based prompt injection attack.
Genetic Auto-prompt Learning for Pre-trained Code Intelligence Language Models
Mar 20, 2024



As Pre-trained Language Models (PLMs), a popular approach for code intelligence, continue to grow in size, the computational cost of their usage has become prohibitively expensive. Prompt learning, a recent development in the field of natural language processing, emerges as a potential solution to address this challenge. In this paper, we investigate the effectiveness of prompt learning in code intelligence tasks. We unveil its reliance on manually designed prompts, which often require significant human effort and expertise. Moreover, we discover existing automatic prompt design methods are very limited to code intelligence tasks due to factors including gradient dependence, high computational demands, and limited applicability. To effectively address both issues, we propose Genetic Auto Prompt (GenAP), which utilizes an elaborate genetic algorithm to automatically design prompts. With GenAP, non-experts can effortlessly generate superior prompts compared to meticulously manual-designed ones. GenAP operates without the need for gradients or additional computational costs, rendering it gradient-free and cost-effective. Moreover, GenAP supports both understanding and generation types of code intelligence tasks, exhibiting great applicability. We conduct GenAP on three popular code intelligence PLMs with three canonical code intelligence tasks including defect prediction, code summarization, and code translation. The results suggest that GenAP can effectively automate the process of designing prompts. Specifically, GenAP outperforms all other methods across all three tasks (e.g., improving accuracy by an average of 2.13% for defect prediction). To the best of our knowledge, GenAP is the first work to automatically design prompts for code intelligence PLMs.
Friendly Sharpness-Aware Minimization
Mar 19, 2024



Sharpness-Aware Minimization (SAM) has been instrumental in improving deep neural network training by minimizing both training loss and loss sharpness. Despite the practical success, the mechanisms behind SAM's generalization enhancements remain elusive, limiting its progress in deep learning optimization. In this work, we investigate SAM's core components for generalization improvement and introduce "Friendly-SAM" (F-SAM) to further enhance SAM's generalization. Our investigation reveals the key role of batch-specific stochastic gradient noise within the adversarial perturbation, i.e., the current minibatch gradient, which significantly influences SAM's generalization performance. By decomposing the adversarial perturbation in SAM into full gradient and stochastic gradient noise components, we discover that relying solely on the full gradient component degrades generalization while excluding it leads to improved performance. The possible reason lies in the full gradient component's increase in sharpness loss for the entire dataset, creating inconsistencies with the subsequent sharpness minimization step solely on the current minibatch data. Inspired by these insights, F-SAM aims to mitigate the negative effects of the full gradient component. It removes the full gradient estimated by an exponentially moving average (EMA) of historical stochastic gradients, and then leverages stochastic gradient noise for improved generalization. Moreover, we provide theoretical validation for the EMA approximation and prove the convergence of F-SAM on non-convex problems. Extensive experiments demonstrate the superior generalization performance and robustness of F-SAM over vanilla SAM. Code is available at https://github.com/nblt/F-SAM.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024



Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
Few-shot Learner Parameterization by Diffusion Time-steps
Mar 05, 2024Even when using large multi-modal foundation models, few-shot learning is still challenging -- if there is no proper inductive bias, it is nearly impossible to keep the nuanced class attributes while removing the visually prominent attributes that spuriously correlate with class labels. To this end, we find an inductive bias that the time-steps of a Diffusion Model (DM) can isolate the nuanced class attributes, i.e., as the forward diffusion adds noise to an image at each time-step, nuanced attributes are usually lost at an earlier time-step than the spurious attributes that are visually prominent. Building on this, we propose Time-step Few-shot (TiF) learner. We train class-specific low-rank adapters for a text-conditioned DM to make up for the lost attributes, such that images can be accurately reconstructed from their noisy ones given a prompt. Hence, at a small time-step, the adapter and prompt are essentially a parameterization of only the nuanced class attributes. For a test image, we can use the parameterization to only extract the nuanced class attributes for classification. TiF learner significantly outperforms OpenCLIP and its adapters on a variety of fine-grained and customized few-shot learning tasks. Codes are in https://github.com/yue-zhongqi/tif.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.