 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Design of Active Kinesthetic Garments
Oct 14, 2022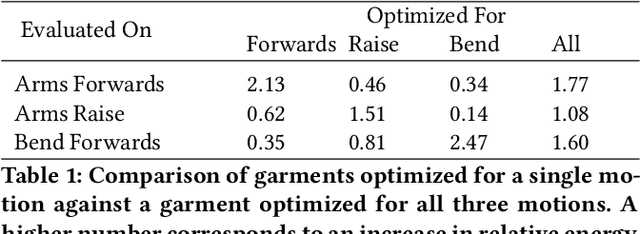
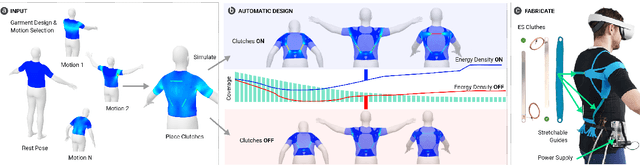
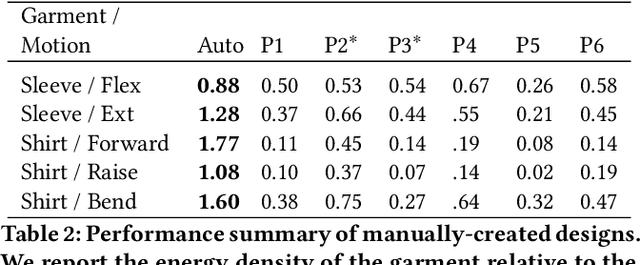
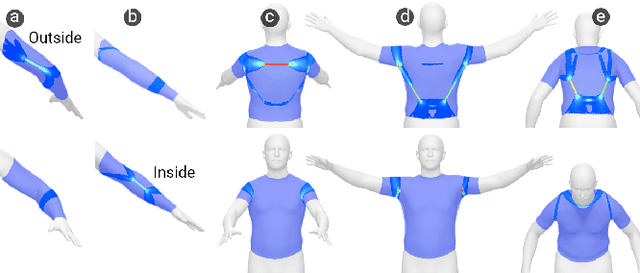
Garments with the ability to provide kinesthetic force-feedback on-demand can augment human capabilities in a non-obtrusive way, enabling numerous applications in VR haptics, motion assistance, and robotic control. However, designing such garments is a complex, and often manual task, particularly when the goal is to resist multiple motions with a single design. In this work, we propose a computational pipeline for designing connecting structures between active components - one of the central challenges in this context. We focus on electrostatic (ES) clutches that are compliant in their passive state while strongly resisting elongation when activated. Our method automatically computes optimized connecting structures that efficiently resist a range of pre-defined body motions on demand. We propose a novel dual-objective optimization approach to simultaneously maximize the resistance to motion when clutches are active, while minimizing resistance when inactive. We demonstrate our method on a set of problems involving different body sites and a range of motions. We further fabricate and evaluate a subset of our automatically created designs against manually created baselines using mechanical testing and in a VR pointing study.
Reconstructing Action-Conditioned Human-Object Interactions Using Commonsense Knowledge Priors
Sep 06, 2022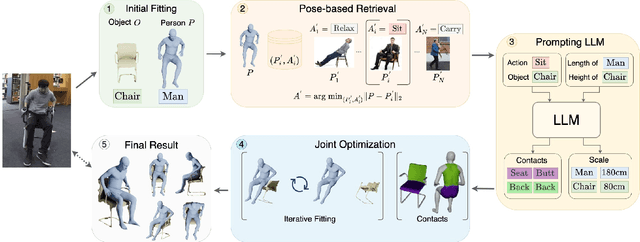
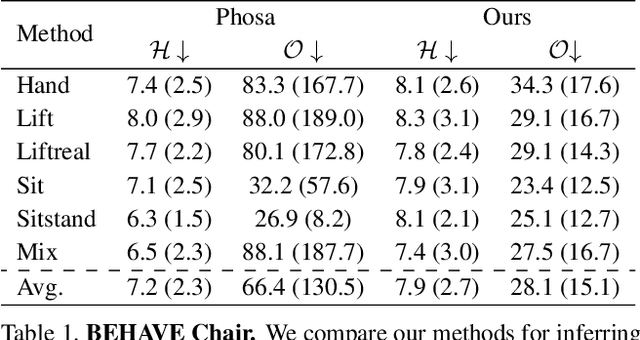
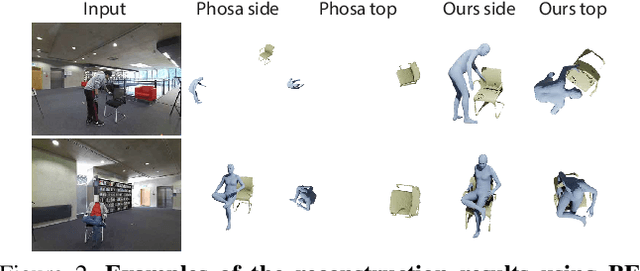
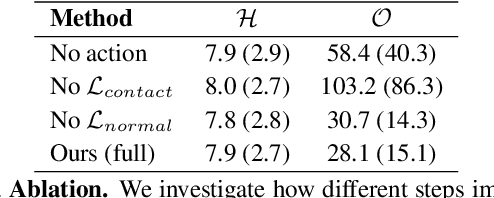
We present a method for inferring diverse 3D models of human-object interactions from images. Reasoning about how humans interact with objects in complex scenes from a single 2D image is a challenging task given ambiguities arising from the loss of information through projection. In addition, modeling 3D interactions requires the generalization ability towards diverse object categories and interaction types. We propose an action-conditioned modeling of interactions that allows us to infer diverse 3D arrangements of humans and objects without supervision on contact regions or 3D scene geometry. Our method extracts high-level commonsense knowledge from large language models (such as GPT-3), and applies them to perform 3D reasoning of human-object interactions. Our key insight is priors extracted from large language models can help in reasoning about human-object contacts from textural prompts only. We quantitatively evaluate the inferred 3D models on a large human-object interaction dataset and show how our method leads to better 3D reconstructions. We further qualitatively evaluate the effectiveness of our method on real images and demonstrate its generalizability towards interaction types and object categories.
EyeNeRF: A Hybrid Representation for Photorealistic Synthesis, Animation and Relighting of Human Eyes
Jun 16, 2022
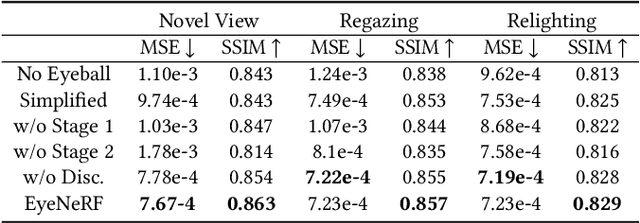
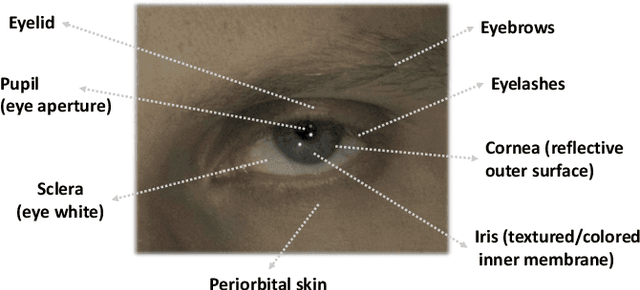
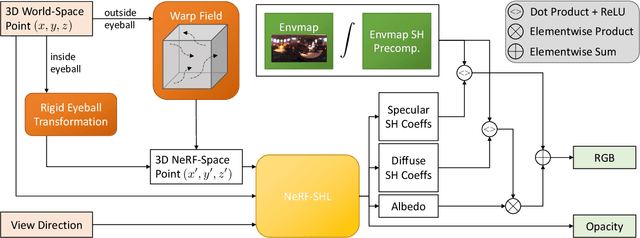
A unique challenge in creating high-quality animatable and relightable 3D avatars of people is modeling human eyes. The challenge of synthesizing eyes is multifold as it requires 1) appropriate representations for the various components of the eye and the periocular region for coherent viewpoint synthesis, capable of representing diffuse, refractive and highly reflective surfaces, 2) disentangling skin and eye appearance from environmental illumination such that it may be rendered under novel lighting conditions, and 3) capturing eyeball motion and the deformation of the surrounding skin to enable re-gazing. These challenges have traditionally necessitated the use of expensive and cumbersome capture setups to obtain high-quality results, and even then, modeling of the eye region holistically has remained elusive. We present a novel geometry and appearance representation that enables high-fidelity capture and photorealistic animation, view synthesis and relighting of the eye region using only a sparse set of lights and cameras. Our hybrid representation combines an explicit parametric surface model for the eyeball with implicit deformable volumetric representations for the periocular region and the interior of the eye. This novel hybrid model has been designed to address the various parts of that challenging facial area - the explicit eyeball surface allows modeling refraction and high-frequency specular reflection at the cornea, whereas the implicit representation is well suited to model lower-frequency skin reflection via spherical harmonics and can represent non-surface structures such as hair or diffuse volumetric bodies, both of which are a challenge for explicit surface models. We show that for high-resolution close-ups of the eye, our model can synthesize high-fidelity animated gaze from novel views under unseen illumination conditions.
TempoRL: Temporal Priors for Exploration in Off-Policy Reinforcement Learning
May 26, 2022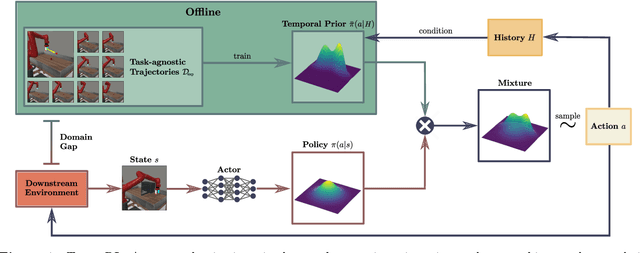

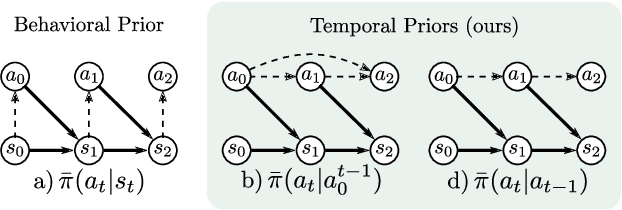

Efficient exploration is a crucial challenge in deep reinforcement learning. Several methods, such as behavioral priors, are able to leverage offline data in order to efficiently accelerate reinforcement learning on complex tasks. However, if the task at hand deviates excessively from the demonstrated task, the effectiveness of such methods is limited. In our work, we propose to learn features from offline data that are shared by a more diverse range of tasks, such as correlation between actions and directedness. Therefore, we introduce state-independent temporal priors, which directly model temporal consistency in demonstrated trajectories, and are capable of driving exploration in complex tasks, even when trained on data collected on simpler tasks. Furthermore, we introduce a novel integration scheme for action priors in off-policy reinforcement learning by dynamically sampling actions from a probabilistic mixture of policy and action prior. We compare our approach against strong baselines and provide empirical evidence that it can accelerate reinforcement learning in long-horizon continuous control tasks under sparse reward settings.
Articulated Objects in Free-form Hand Interaction
Apr 28, 2022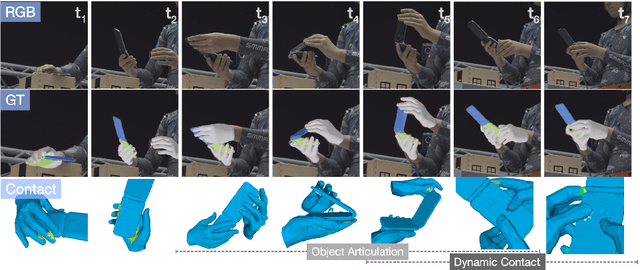

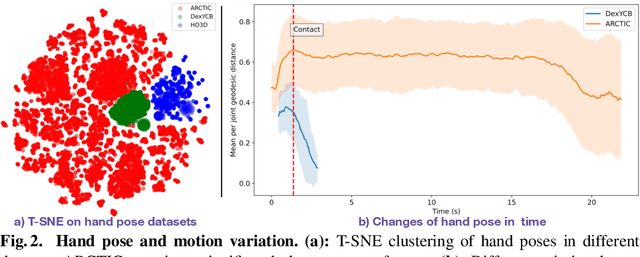
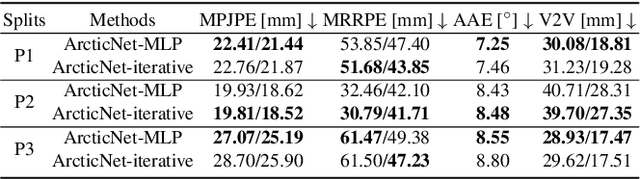
We use our hands to interact with and to manipulate objects. Articulated objects are especially interesting since they often require the full dexterity of human hands to manipulate them. To understand, model, and synthesize such interactions, automatic and robust methods that reconstruct hands and articulated objects in 3D from a color image are needed. Existing methods for estimating 3D hand and object pose from images focus on rigid objects. In part, because such methods rely on training data and no dataset of articulated object manipulation exists. Consequently, we introduce ARCTIC - the first dataset of free-form interactions of hands and articulated objects. ARCTIC has 1.2M images paired with accurate 3D meshes for both hands and for objects that move and deform over time. The dataset also provides hand-object contact information. To show the value of our dataset, we perform two novel tasks on ARCTIC: (1) 3D reconstruction of two hands and an articulated object in interaction; (2) an estimation of dense hand-object relative distances, which we call interaction field estimation. For the first task, we present ArcticNet, a baseline method for the task of jointly reconstructing two hands and an articulated object from an RGB image. For interaction field estimation, we predict the relative distances from each hand vertex to the object surface, and vice versa. We introduce InterField, the first method that estimates such distances from a single RGB image. We provide qualitative and quantitative experiments for both tasks, and provide detailed analysis on the data. Code and data will be available at https://arctic.is.tue.mpg.de.
PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence
Apr 08, 2022
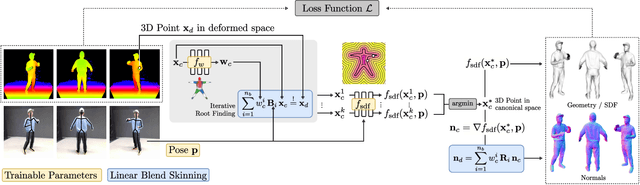
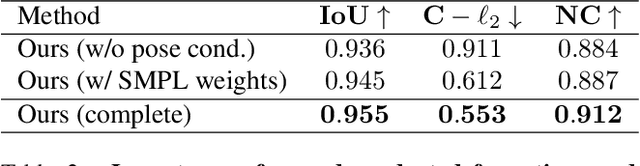
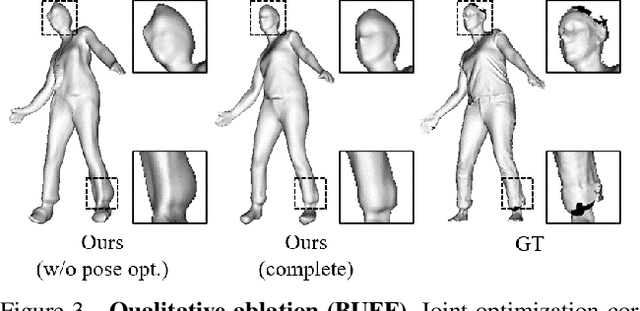
We present a novel method to learn Personalized Implicit Neural Avatars (PINA) from a short RGB-D sequence. This allows non-expert users to create a detailed and personalized virtual copy of themselves, which can be animated with realistic clothing deformations. PINA does not require complete scans, nor does it require a prior learned from large datasets of clothed humans. Learning a complete avatar in this setting is challenging, since only few depth observations are available, which are noisy and incomplete (i.e. only partial visibility of the body per frame). We propose a method to learn the shape and non-rigid deformations via a pose-conditioned implicit surface and a deformation field, defined in canonical space. This allows us to fuse all partial observations into a single consistent canonical representation. Fusion is formulated as a global optimization problem over the pose, shape and skinning parameters. The method can learn neural avatars from real noisy RGB-D sequences for a diverse set of people and clothing styles and these avatars can be animated given unseen motion sequences.
LiP-Flow: Learning Inference-time Priors for Codec Avatars via Normalizing Flows in Latent Space
Mar 15, 2022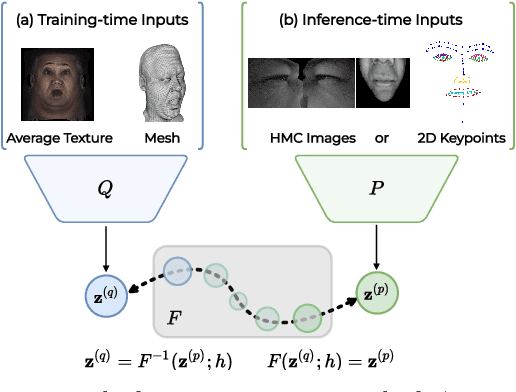
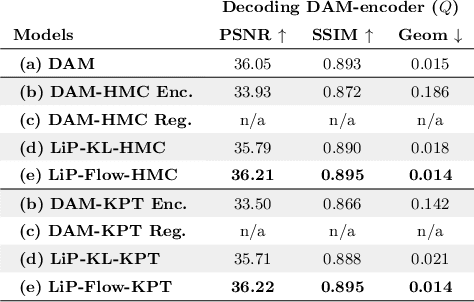

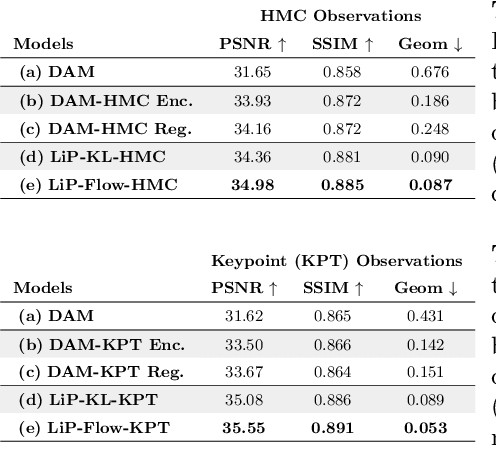
Neural face avatars that are trained from multi-view data captured in camera domes can produce photo-realistic 3D reconstructions. However, at inference time, they must be driven by limited inputs such as partial views recorded by headset-mounted cameras or a front-facing camera, and sparse facial landmarks. To mitigate this asymmetry, we introduce a prior model that is conditioned on the runtime inputs and tie this prior space to the 3D face model via a normalizing flow in the latent space. Our proposed model, LiP-Flow, consists of two encoders that learn representations from the rich training-time and impoverished inference-time observations. A normalizing flow bridges the two representation spaces and transforms latent samples from one domain to another, allowing us to define a latent likelihood objective. We trained our model end-to-end to maximize the similarity of both representation spaces and the reconstruction quality, making the 3D face model aware of the limited driving signals. We conduct extensive evaluations where the latent codes are optimized to reconstruct 3D avatars from partial or sparse observations. We show that our approach leads to an expressive and effective prior, capturing facial dynamics and subtle expressions better.
In the Arms of a Robot: Designing Autonomous Hugging Robots with Intra-Hug Gestures
Feb 20, 2022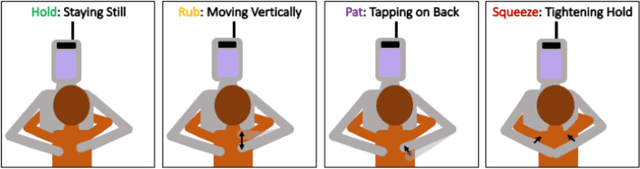
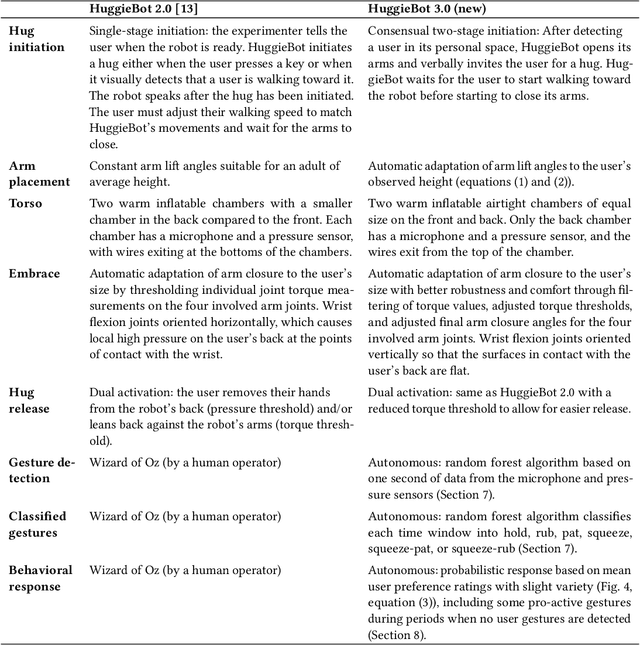


Hugs are complex affective interactions that often include gestures like squeezes. We present six new guidelines for designing interactive hugging robots, which we validate through two studies with our custom robot. To achieve autonomy, we investigated robot responses to four human intra-hug gestures: holding, rubbing, patting, and squeezing. Thirty-two users each exchanged and rated sixteen hugs with an experimenter-controlled HuggieBot 2.0. The robot's inflated torso's microphone and pressure sensor collected data of the subjects' demonstrations that were used to develop a perceptual algorithm that classifies user actions with 88\% accuracy. Users enjoyed robot squeezes, regardless of their performed action, they valued variety in the robot response, and they appreciated robot-initiated intra-hug gestures. From average user ratings, we created a probabilistic behavior algorithm that chooses robot responses in real time. We implemented improvements to the robot platform to create HuggieBot 3.0 and then validated its gesture perception system and behavior algorithm with sixteen users. The robot's responses and proactive gestures were greatly enjoyed. Users found the robot more natural, enjoyable, and intelligent in the last phase of the experiment than in the first. After the study, they felt more understood by the robot and thought robots were nicer to hug.
gDNA: Towards Generative Detailed Neural Avatars
Jan 11, 2022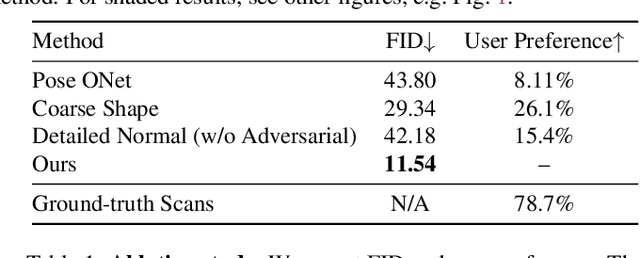
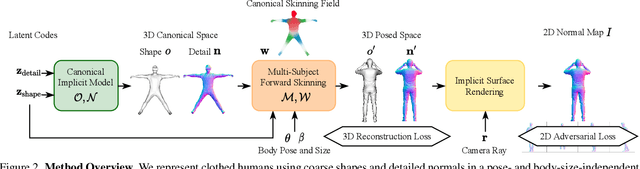

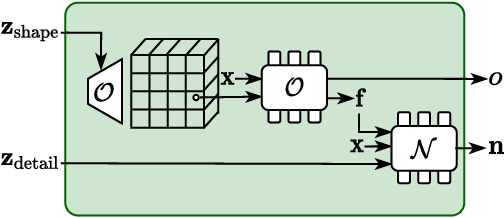
To make 3D human avatars widely available, we must be able to generate a variety of 3D virtual humans with varied identities and shapes in arbitrary poses. This task is challenging due to the diversity of clothed body shapes, their complex articulations, and the resulting rich, yet stochastic geometric detail in clothing. Hence, current methods to represent 3D people do not provide a full generative model of people in clothing. In this paper, we propose a novel method that learns to generate detailed 3D shapes of people in a variety of garments with corresponding skinning weights. Specifically, we devise a multi-subject forward skinning module that is learned from only a few posed, un-rigged scans per subject. To capture the stochastic nature of high-frequency details in garments, we leverage an adversarial loss formulation that encourages the model to capture the underlying statistics. We provide empirical evidence that this leads to realistic generation of local details such as wrinkles. We show that our model is able to generate natural human avatars wearing diverse and detailed clothing. Furthermore, we show that our method can be used on the task of fitting human models to raw scans, outperforming the previous state-of-the-art.
SAGA: Stochastic Whole-Body Grasping with Contact
Dec 19, 2021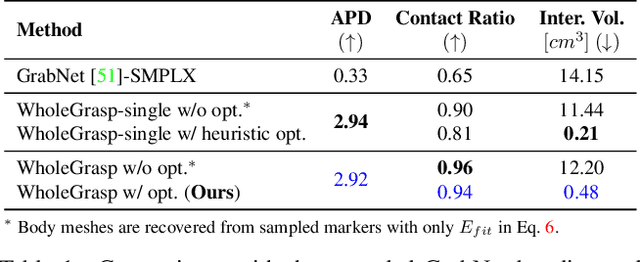

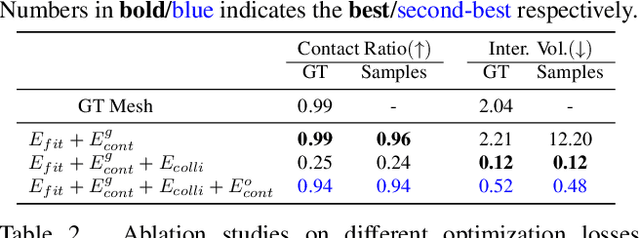
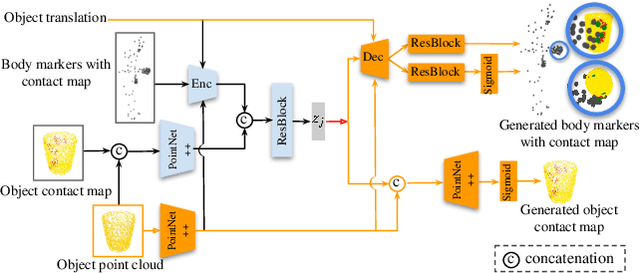
Human grasping synthesis has numerous applications including AR/VR, video games, and robotics. While some methods have been proposed to generate realistic hand-object interaction for object grasping and manipulation, they typically only consider the hand interacting with objects. In this work, our goal is to synthesize whole-body grasping motion. Given a 3D object, we aim to generate diverse and natural whole-body human motions that approach and grasp the object. This task is challenging as it requires modeling both whole-body dynamics and dexterous finger movements. To this end, we propose SAGA (StochAstic whole-body Grasping with contAct) which consists of two key components: (a) Static whole-body grasping pose generation. Specifically, we propose a multi-task generative model, to jointly learn static whole-body grasping poses and human-object contacts. (b) Grasping motion infilling. Given an initial pose and the generated whole-body grasping pose as the starting and ending poses of the motion respectively, we design a novel contact-aware generative motion infilling module to generate a diverse set of grasp-oriented motions. We demonstrate the effectiveness of our method being the first generative framework to synthesize realistic and expressive whole-body motions that approach and grasp randomly placed unseen objects. The code and videos are available at: https://jiahaoplus.github.io/SAGA/saga.html.