 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding internal audio sensing to internal vision enables human-like in-hand fabric recognition with soft robotic fingertips
Feb 13, 2026Distinguishing the feel of smooth silk from coarse cotton is a trivial everyday task for humans. When exploring such fabrics, fingertip skin senses both spatio-temporal force patterns and texture-induced vibrations that are integrated to form a haptic representation of the explored material. It is challenging to reproduce this rich, dynamic perceptual capability in robots because tactile sensors typically cannot achieve both high spatial resolution and high temporal sampling rate. In this work, we present a system that can sense both types of haptic information, and we investigate how each type influences robotic tactile perception of fabrics. Our robotic hand's middle finger and thumb each feature a soft tactile sensor: one is the open-source Minsight sensor that uses an internal camera to measure fingertip deformation and force at 50 Hz, and the other is our new sensor Minsound that captures vibrations through an internal MEMS microphone with a bandwidth from 50 Hz to 15 kHz. Inspired by the movements humans make to evaluate fabrics, our robot actively encloses and rubs folded fabric samples between its two sensitive fingers. Our results test the influence of each sensing modality on overall classification performance, showing high utility for the audio-based sensor. Our transformer-based method achieves a maximum fabric classification accuracy of 97 % on a dataset of 20 common fabrics. Incorporating an external microphone away from Minsound increases our method's robustness in loud ambient noise conditions. To show that this audio-visual tactile sensing approach generalizes beyond the training data, we learn general representations of fabric stretchiness, thickness, and roughness.
Open-Source Multi-Viewpoint Surgical Telerobotics
May 16, 2025As robots for minimally invasive surgery (MIS) gradually become more accessible and modular, we believe there is a great opportunity to rethink and expand the visualization and control paradigms that have characterized surgical teleoperation since its inception. We conjecture that introducing one or more additional adjustable viewpoints in the abdominal cavity would not only unlock novel visualization and collaboration strategies for surgeons but also substantially boost the robustness of machine perception toward shared autonomy. Immediate advantages include controlling a second viewpoint and teleoperating surgical tools from a different perspective, which would allow collaborating surgeons to adjust their views independently and still maneuver their robotic instruments intuitively. Furthermore, we believe that capturing synchronized multi-view 3D measurements of the patient's anatomy would unlock advanced scene representations. Accurate real-time intraoperative 3D perception will allow algorithmic assistants to directly control one or more robotic instruments and/or robotic cameras. Toward these goals, we are building a synchronized multi-viewpoint, multi-sensor robotic surgery system by integrating high-performance vision components and upgrading the da Vinci Research Kit control logic. This short paper reports a functional summary of our setup and elaborates on its potential impacts in research and future clinical practice. By fully open-sourcing our system, we will enable the research community to reproduce our setup, improve it, and develop powerful algorithms, effectively boosting clinical translation of cutting-edge research.
Holistic Fusion: Task- and Setup-Agnostic Robot Localization and State Estimation with Factor Graphs
Apr 08, 2025Seamless operation of mobile robots in challenging environments requires low-latency local motion estimation (e.g., dynamic maneuvers) and accurate global localization (e.g., wayfinding). While most existing sensor-fusion approaches are designed for specific scenarios, this work introduces a flexible open-source solution for task- and setup-agnostic multimodal sensor fusion that is distinguished by its generality and usability. Holistic Fusion formulates sensor fusion as a combined estimation problem of i) the local and global robot state and ii) a (theoretically unlimited) number of dynamic context variables, including automatic alignment of reference frames; this formulation fits countless real-world applications without any conceptual modifications. The proposed factor-graph solution enables the direct fusion of an arbitrary number of absolute, local, and landmark measurements expressed with respect to different reference frames by explicitly including them as states in the optimization and modeling their evolution as random walks. Moreover, local smoothness and consistency receive particular attention to prevent jumps in the robot state belief. HF enables low-latency and smooth online state estimation on typical robot hardware while simultaneously providing low-drift global localization at the IMU measurement rate. The efficacy of this released framework is demonstrated in five real-world scenarios on three robotic platforms, each with distinct task requirements.
Diffusion-Based Approximate MPC: Fast and Consistent Imitation of Multi-Modal Action Distributions
Apr 06, 2025Approximating model predictive control (MPC) using imitation learning (IL) allows for fast control without solving expensive optimization problems online. However, methods that use neural networks in a simple L2-regression setup fail to approximate multi-modal (set-valued) solution distributions caused by local optima found by the numerical solver or non-convex constraints, such as obstacles, significantly limiting the applicability of approximate MPC in practice. We solve this issue by using diffusion models to accurately represent the complete solution distribution (i.e., all modes) at high control rates (more than 1000 Hz). This work shows that diffusion based AMPC significantly outperforms L2-regression-based approximate MPC for multi-modal action distributions. In contrast to most earlier work on IL, we also focus on running the diffusion-based controller at a higher rate and in joint space instead of end-effector space. Additionally, we propose the use of gradient guidance during the denoising process to consistently pick the same mode in closed loop to prevent switching between solutions. We propose using the cost and constraint satisfaction of the original MPC problem during parallel sampling of solutions from the diffusion model to pick a better mode online. We evaluate our method on the fast and accurate control of a 7-DoF robot manipulator both in simulation and on hardware deployed at 250 Hz, achieving a speedup of more than 70 times compared to solving the MPC problem online and also outperforming the numerical optimization (used for training) in success ratio.
Visuo-Tactile Object Pose Estimation for a Multi-Finger Robot Hand with Low-Resolution In-Hand Tactile Sensing
Mar 25, 2025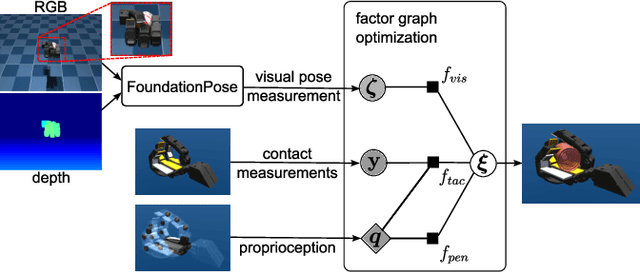
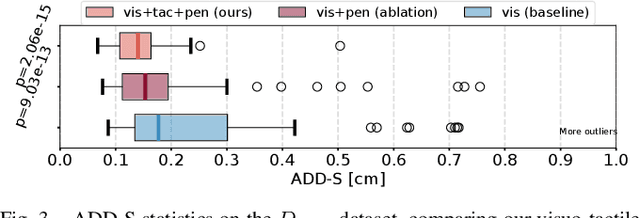
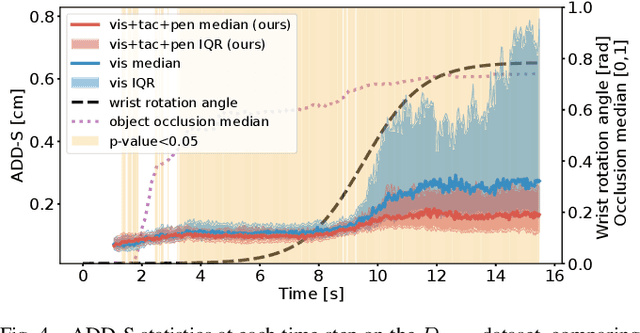
Accurate 3D pose estimation of grasped objects is an important prerequisite for robots to perform assembly or in-hand manipulation tasks, but object occlusion by the robot's own hand greatly increases the difficulty of this perceptual task. Here, we propose that combining visual information and proprioception with binary, low-resolution tactile contact measurements from across the interior surface of an articulated robotic hand can mitigate this issue. The visuo-tactile object-pose-estimation problem is formulated probabilistically in a factor graph. The pose of the object is optimized to align with the three kinds of measurements using a robust cost function to reduce the influence of visual or tactile outlier readings. The advantages of the proposed approach are first demonstrated in simulation: a custom 15-DoF robot hand with one binary tactile sensor per link grasps 17 YCB objects while observed by an RGB-D camera. This low-resolution in-hand tactile sensing significantly improves object-pose estimates under high occlusion and also high visual noise. We also show these benefits through grasping tests with a preliminary real version of our tactile hand, obtaining reasonable visuo-tactile estimates of object pose at approximately 13.3 Hz on average.
MultiViPerFrOG: A Globally Optimized Multi-Viewpoint Perception Framework for Camera Motion and Tissue Deformation
Aug 08, 2024Reconstructing the 3D shape of a deformable environment from the information captured by a moving depth camera is highly relevant to surgery. The underlying challenge is the fact that simultaneously estimating camera motion and tissue deformation in a fully deformable scene is an ill-posed problem, especially from a single arbitrarily moving viewpoint. Current solutions are often organ-specific and lack the robustness required to handle large deformations. Here we propose a multi-viewpoint global optimization framework that can flexibly integrate the output of low-level perception modules (data association, depth, and relative scene flow) with kinematic and scene-modeling priors to jointly estimate multiple camera motions and absolute scene flow. We use simulated noisy data to show three practical examples that successfully constrain the convergence to a unique solution. Overall, our method shows robustness to combined noisy input measures and can process hundreds of points in a few milliseconds. MultiViPerFrOG builds a generalized learning-free scaffolding for spatio-temporal encoding that can unlock advanced surgical scene representations and will facilitate the development of the computer-assisted-surgery technologies of the future.
Dense 3D Reconstruction Through Lidar: A Comparative Study on Ex-vivo Porcine Tissue
Jan 19, 2024New sensing technologies and more advanced processing algorithms are transforming computer-integrated surgery. While researchers are actively investigating depth sensing and 3D reconstruction for vision-based surgical assistance, it remains difficult to achieve real-time, accurate, and robust 3D representations of the abdominal cavity for minimally invasive surgery. Thus, this work uses quantitative testing on fresh ex-vivo porcine tissue to thoroughly characterize the quality with which a 3D laser-based time-of-flight sensor (lidar) can perform anatomical surface reconstruction. Ground-truth surface shapes are captured with a commercial laser scanner, and the resulting signed error fields are analyzed using rigorous statistical tools. When compared to modern learning-based stereo matching from endoscopic images, time-of-flight sensing demonstrates higher precision, lower processing delay, higher frame rate, and superior robustness against sensor distance and poor illumination. Furthermore, we report on the potential negative effect of near-infrared light penetration on the accuracy of lidar measurements across different tissue samples, identifying a significant measured depth offset for muscle in contrast to fat and liver. Our findings highlight the potential of lidar for intraoperative 3D perception and point toward new methods that combine complementary time-of-flight and spectral imaging.
Minsight: A Fingertip-Sized Vision-Based Tactile Sensor for Robotic Manipulation
Apr 21, 2023Intelligent interaction with the physical world requires perceptual abilities beyond vision and hearing; vibrant tactile sensing is essential for autonomous robots to dexterously manipulate unfamiliar objects or safely contact humans. Therefore, robotic manipulators need high-resolution touch sensors that are compact, robust, inexpensive, and efficient. The soft vision-based haptic sensor presented herein is a miniaturized and optimized version of the previously published sensor Insight. Minsight has the size and shape of a human fingertip and uses machine learning methods to output high-resolution maps of 3D contact force vectors at 60 Hz. Experiments confirm its excellent sensing performance, with a mean absolute force error of 0.07 N and contact location error of 0.6 mm across its surface area. Minsight's utility is shown in two robotic tasks on a 3-DoF manipulator. First, closed-loop force control enables the robot to track the movements of a human finger based only on tactile data. Second, the informative value of the sensor output is shown by detecting whether a hard lump is embedded within a soft elastomer with an accuracy of 98%. These findings indicate that Minsight can give robots the detailed fingertip touch sensing needed for dexterous manipulation and physical human-robot interaction.
Reconstructing Signing Avatars From Video Using Linguistic Priors
Apr 20, 2023



Sign language (SL) is the primary method of communication for the 70 million Deaf people around the world. Video dictionaries of isolated signs are a core SL learning tool. Replacing these with 3D avatars can aid learning and enable AR/VR applications, improving access to technology and online media. However, little work has attempted to estimate expressive 3D avatars from SL video; occlusion, noise, and motion blur make this task difficult. We address this by introducing novel linguistic priors that are universally applicable to SL and provide constraints on 3D hand pose that help resolve ambiguities within isolated signs. Our method, SGNify, captures fine-grained hand pose, facial expression, and body movement fully automatically from in-the-wild monocular SL videos. We evaluate SGNify quantitatively by using a commercial motion-capture system to compute 3D avatars synchronized with monocular video. SGNify outperforms state-of-the-art 3D body-pose- and shape-estimation methods on SL videos. A perceptual study shows that SGNify's 3D reconstructions are significantly more comprehensible and natural than those of previous methods and are on par with the source videos. Code and data are available at $\href{http://sgnify.is.tue.mpg.de}{\text{sgnify.is.tue.mpg.de}}$.
Multimodal Multi-User Surface Recognition with the Kernel Two-Sample Test
Mar 08, 2023



Machine learning and deep learning have been used extensively to classify physical surfaces through images and time-series contact data. However, these methods rely on human expertise and entail the time-consuming processes of data and parameter tuning. To overcome these challenges, we propose an easily implemented framework that can directly handle heterogeneous data sources for classification tasks. Our data-versus-data approach automatically quantifies distinctive differences in distributions in a high-dimensional space via kernel two-sample testing between two sets extracted from multimodal data (e.g., images, sounds, haptic signals). We demonstrate the effectiveness of our technique by benchmarking against expertly engineered classifiers for visual-audio-haptic surface recognition due to the industrial relevance, difficulty, and competitive baselines of this application; ablation studies confirm the utility of key components of our pipeline. As shown in our open-source code, we achieve 97.2% accuracy on a standard multi-user dataset with 108 surface classes, outperforming the state-of-the-art machine-learning algorithm by 6% on a more difficult version of the task. The fact that our classifier obtains this performance with minimal data processing in the standard algorithm setting reinforces the powerful nature of kernel methods for learning to recognize complex patterns.