 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSR-Net: Multi-Scale Relighting Network for One-to-One Relighting
Jul 13, 2021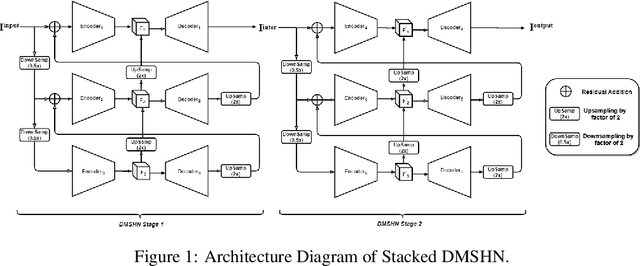


Deep image relighting allows photo enhancement by illumination-specific retouching without human effort and so it is getting much interest lately. Most of the existing popular methods available for relighting are run-time intensive and memory inefficient. Keeping these issues in mind, we propose the use of Stacked Deep Multi-Scale Hierarchical Network, which aggregates features from each image at different scales. Our solution is differentiable and robust for translating image illumination setting from input image to target image. Additionally, we have also shown that using a multi-step training approach to this problem with two different loss functions can significantly boost performance and can achieve a high quality reconstruction of a relighted image.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021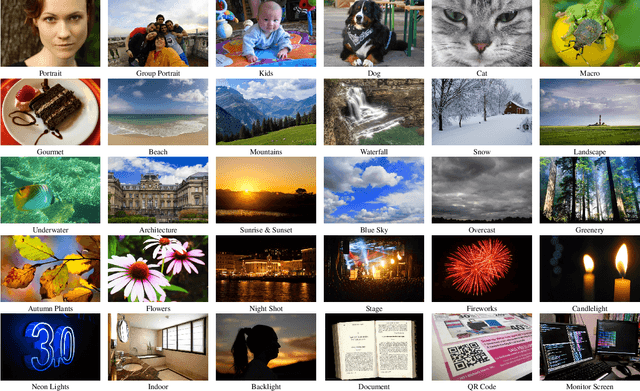
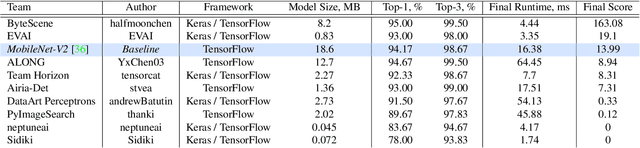

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021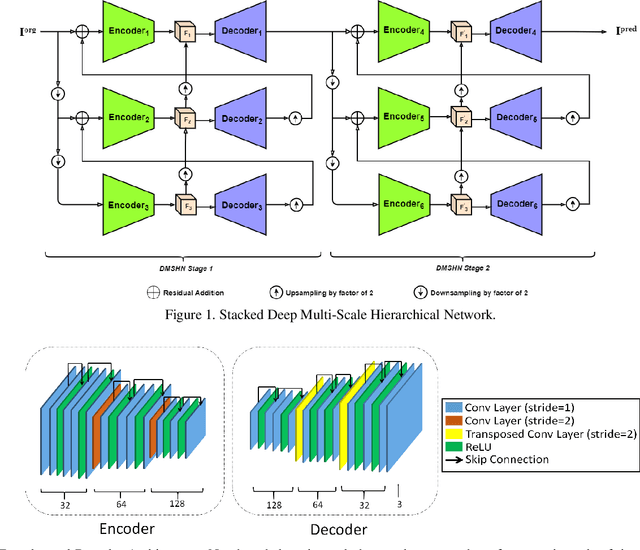
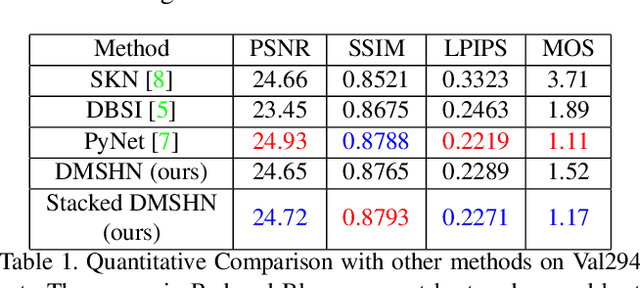

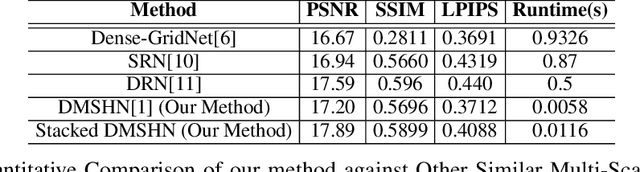
The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.
Efficient Space-time Video Super Resolution using Low-Resolution Flow and Mask Upsampling
May 03, 2021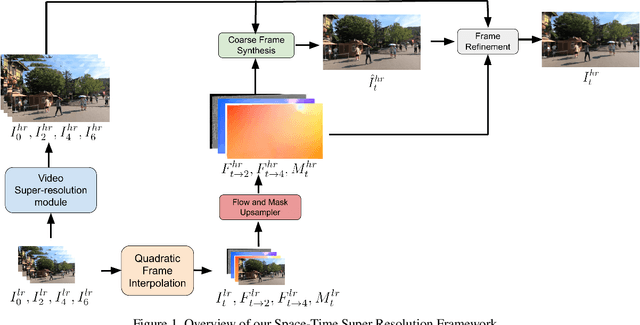
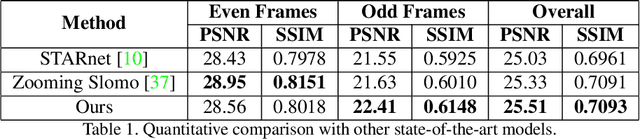

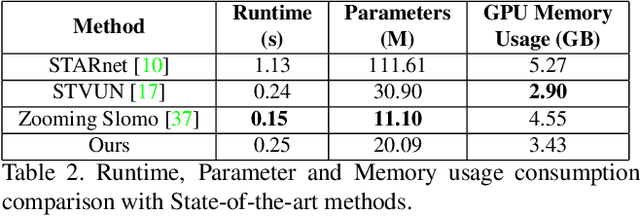
This paper explores an efficient solution for Space-time Super-Resolution, aiming to generate High-resolution Slow-motion videos from Low Resolution and Low Frame rate videos. A simplistic solution is the sequential running of Video Super Resolution and Video Frame interpolation models. However, this type of solutions are memory inefficient, have high inference time, and could not make the proper use of space-time relation property. To this extent, we first interpolate in LR space using quadratic modeling. Input LR frames are super-resolved using a state-of-the-art Video Super-Resolution method. Flowmaps and blending mask which are used to synthesize LR interpolated frame is reused in HR space using bilinear upsampling. This leads to a coarse estimate of HR intermediate frame which often contains artifacts along motion boundaries. We use a refinement network to improve the quality of HR intermediate frame via residual learning. Our model is lightweight and performs better than current state-of-the-art models in REDS STSR Validation set.
Colorectal Cancer Segmentation using Atrous Convolution and Residual Enhanced UNet
Mar 16, 2021
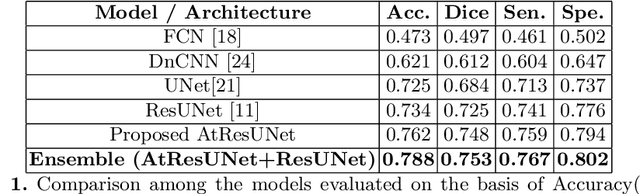
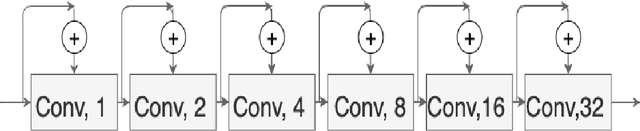
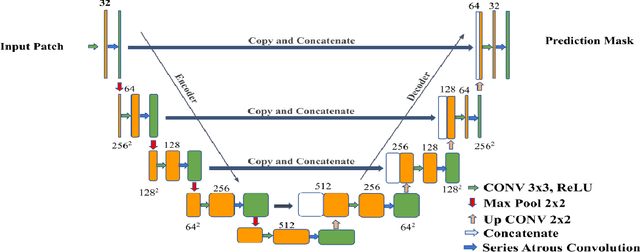
Colorectal cancer is a leading cause of death worldwide. However, early diagnosis dramatically increases the chances of survival, for which it is crucial to identify the tumor in the body. Since its imaging uses high-resolution techniques, annotating the tumor is time-consuming and requires particular expertise. Lately, methods built upon Convolutional Neural Networks(CNNs) have proven to be at par, if not better in many biomedical segmentation tasks. For the task at hand, we propose another CNN-based approach, which uses atrous convolutions and residual connections besides the conventional filters. The training and inference were made using an efficient patch-based approach, which significantly reduced unnecessary computations. The proposed AtResUNet was trained on the DigestPath 2019 Challenge dataset for colorectal cancer segmentation with results having a Dice Coefficient of 0.748.
DSRN: an Efficient Deep Network for Image Relighting
Feb 18, 2021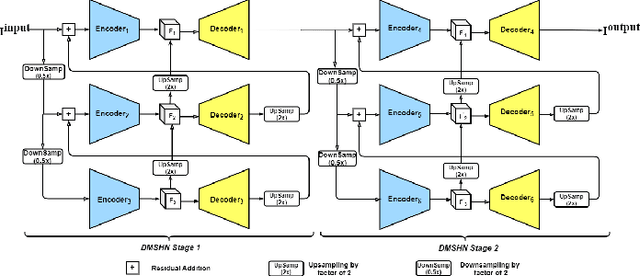
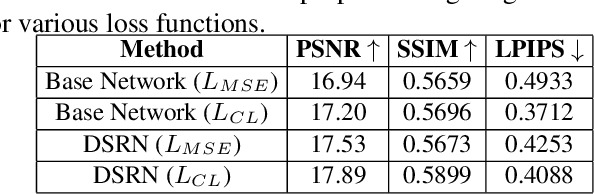
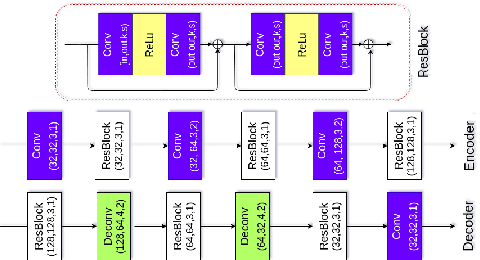
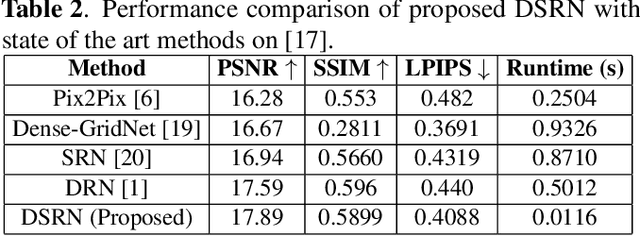
Custom and natural lighting conditions can be emulated in images of the scene during post-editing. Extraordinary capabilities of the deep learning framework can be utilized for such purpose. Deep image relighting allows automatic photo enhancement by illumination-specific retouching. Most of the state-of-the-art methods for relighting are run-time intensive and memory inefficient. In this paper, we propose an efficient, real-time framework Deep Stacked Relighting Network (DSRN) for image relighting by utilizing the aggregated features from input image at different scales. Our model is very lightweight with total size of about 42 MB and has an average inference time of about 0.0116s for image of resolution $1024 \times 1024$ which is faster as compared to other multi-scale models. Our solution is quite robust for translating image color temperature from input image to target image and also performs moderately for light gradient generation with respect to the target image. Additionally, we show that if images illuminated from opposite directions are used as input, the qualitative results improve over using a single input image.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020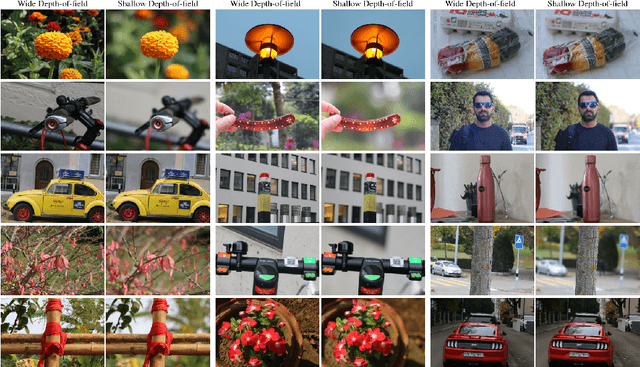


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
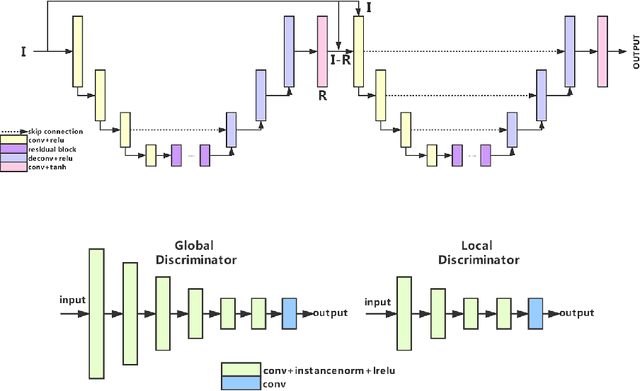
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020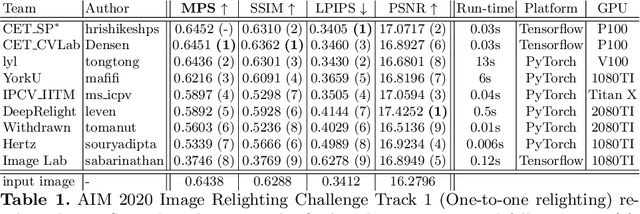

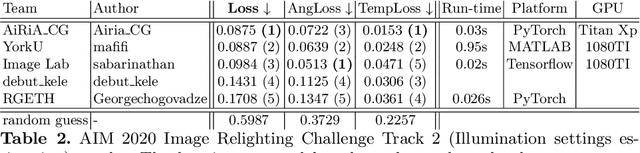

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020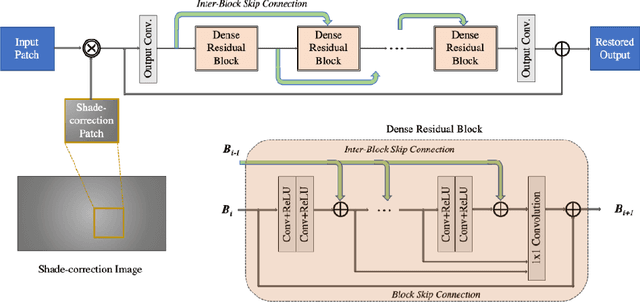
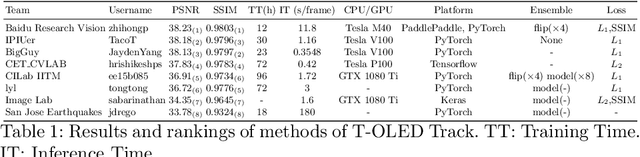
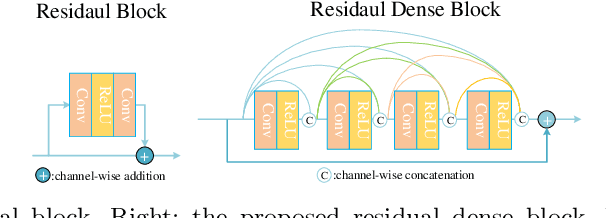
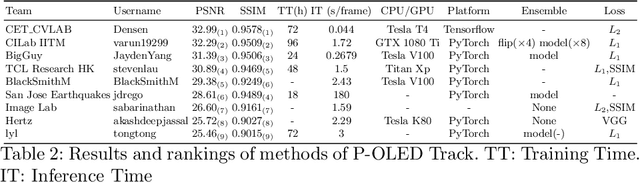
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020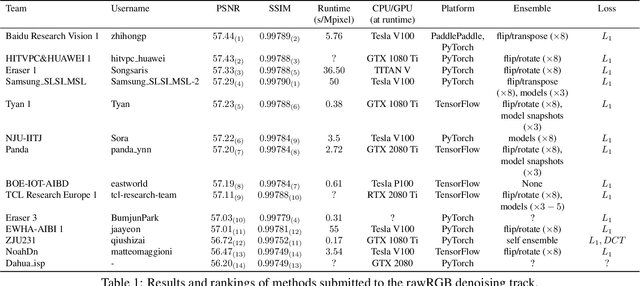
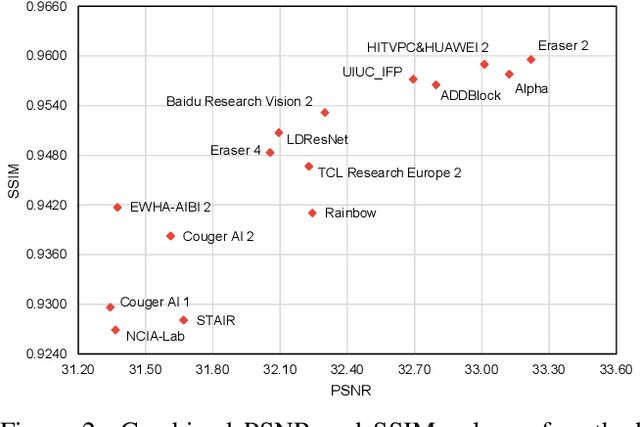
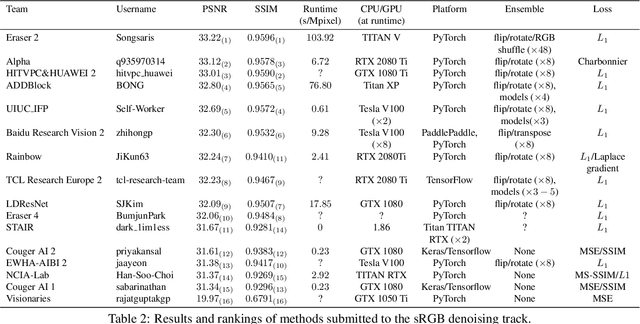
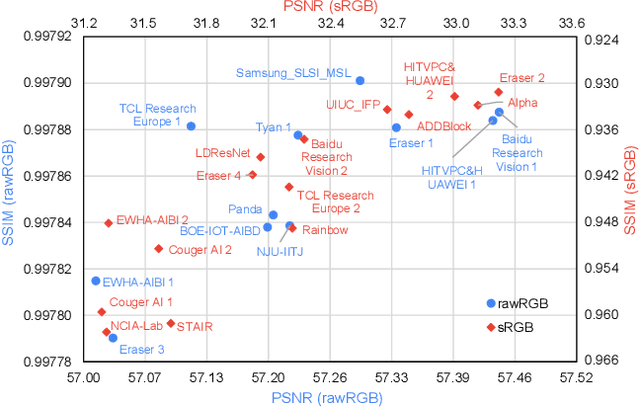
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.