 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond LoRA: Exploring Efficient Fine-Tuning Techniques for Time Series Foundational Models
Sep 17, 2024



Time Series Foundation Models (TSFMs) have recently garnered attention for their ability to model complex, large-scale time series data across domains such as retail, finance, and transportation. However, their application to sensitive, domain-specific fields like healthcare remains challenging, primarily due to the difficulty of fine-tuning these models for specialized, out-of-domain tasks with scarce publicly available datasets. In this work, we explore the use of Parameter-Efficient Fine-Tuning (PEFT) techniques to address these limitations, focusing on healthcare applications, particularly ICU vitals forecasting for sepsis patients. We introduce and evaluate two selective (BitFit and LayerNorm Tuning) and two additive (VeRA and FourierFT) PEFT techniques on multiple configurations of the Chronos TSFM for forecasting vital signs of sepsis patients. Our comparative analysis demonstrates that some of these PEFT methods outperform LoRA in terms of parameter efficiency and domain adaptation, establishing state-of-the-art (SOTA) results in ICU vital forecasting tasks. Interestingly, FourierFT applied to the Chronos (Tiny) variant surpasses the SOTA model while fine-tuning only 2,400 parameters compared to the 700K parameters of the benchmark.
Low-Rank Adaptation of Time Series Foundational Models for Out-of-Domain Modality Forecasting
May 16, 2024Low-Rank Adaptation (LoRA) is a widely used technique for fine-tuning large pre-trained or foundational models across different modalities and tasks. However, its application to time series data, particularly within foundational models, remains underexplored. This paper examines the impact of LoRA on contemporary time series foundational models: Lag-Llama, MOIRAI, and Chronos. We demonstrate LoRA's fine-tuning potential for forecasting the vital signs of sepsis patients in intensive care units (ICUs), emphasizing the models' adaptability to previously unseen, out-of-domain modalities. Integrating LoRA aims to enhance forecasting performance while reducing inefficiencies associated with fine-tuning large models on limited domain-specific data. Our experiments show that LoRA fine-tuning of time series foundational models significantly improves forecasting, achieving results comparable to state-of-the-art models trained from scratch on similar modalities. We conduct comprehensive ablation studies to demonstrate the trade-offs between the number of tunable parameters and forecasting performance and assess the impact of varying LoRA matrix ranks on model performance.
Interpretable Vital Sign Forecasting with Model Agnostic Attention Maps
May 06, 2024Sepsis is a leading cause of mortality in intensive care units (ICUs), representing a substantial medical challenge. The complexity of analyzing diverse vital signs to predict sepsis further aggravates this issue. While deep learning techniques have been advanced for early sepsis prediction, their 'black-box' nature obscures the internal logic, impairing interpretability in critical settings like ICUs. This paper introduces a framework that combines a deep learning model with an attention mechanism that highlights the critical time steps in the forecasting process, thus improving model interpretability and supporting clinical decision-making. We show that the attention mechanism could be adapted to various black box time series forecasting models such as N-HiTS and N-BEATS. Our method preserves the accuracy of conventional deep learning models while enhancing interpretability through attention-weight-generated heatmaps. We evaluated our model on the eICU-CRD dataset, focusing on forecasting vital signs for sepsis patients. We assessed its performance using mean squared error (MSE) and dynamic time warping (DTW) metrics. We explored the attention maps of N-HiTS and N-BEATS, examining the differences in their performance and identifying crucial factors influencing vital sign forecasting.
Remote Heart Rate Monitoring in Smart Environments from Videos with Self-supervised Pre-training
Oct 23, 2023Recent advances in deep learning have made it increasingly feasible to estimate heart rate remotely in smart environments by analyzing videos. However, a notable limitation of deep learning methods is their heavy reliance on extensive sets of labeled data for effective training. To address this issue, self-supervised learning has emerged as a promising avenue. Building on this, we introduce a solution that utilizes self-supervised contrastive learning for the estimation of remote photoplethysmography (PPG) and heart rate monitoring, thereby reducing the dependence on labeled data and enhancing performance. We propose the use of 3 spatial and 3 temporal augmentations for training an encoder through a contrastive framework, followed by utilizing the late-intermediate embeddings of the encoder for remote PPG and heart rate estimation. Our experiments on two publicly available datasets showcase the improvement of our proposed approach over several related works as well as supervised learning baselines, as our results approach the state-of-the-art. We also perform thorough experiments to showcase the effects of using different design choices such as the video representation learning method, the augmentations used in the pre-training stage, and others. We also demonstrate the robustness of our proposed method over the supervised learning approaches on reduced amounts of labeled data.
Privacy-Preserving Remote Heart Rate Estimation from Facial Videos
Jun 01, 2023



Remote Photoplethysmography (rPPG) is the process of estimating PPG from facial videos. While this approach benefits from contactless interaction, it is reliant on videos of faces, which often constitutes an important privacy concern. Recent research has revealed that deep learning techniques are vulnerable to attacks, which can result in significant data breaches making deep rPPG estimation even more sensitive. To address this issue, we propose a data perturbation method that involves extraction of certain areas of the face with less identity-related information, followed by pixel shuffling and blurring. Our experiments on two rPPG datasets (PURE and UBFC) show that our approach reduces the accuracy of facial recognition algorithms by over 60%, with minimal impact on rPPG extraction. We also test our method on three facial recognition datasets (LFW, CALFW, and AgeDB), where our approach reduced performance by nearly 50%. Our findings demonstrate the potential of our approach as an effective privacy-preserving solution for rPPG estimation.
Colorectal Cancer Segmentation using Atrous Convolution and Residual Enhanced UNet
Mar 16, 2021
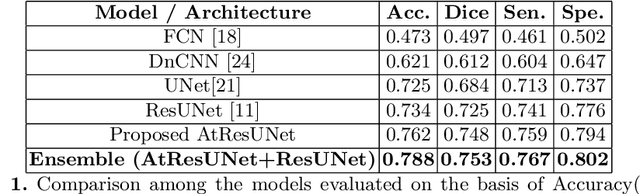
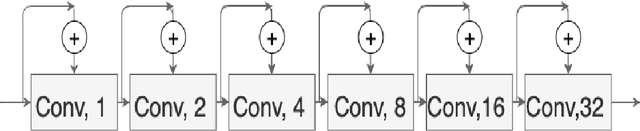
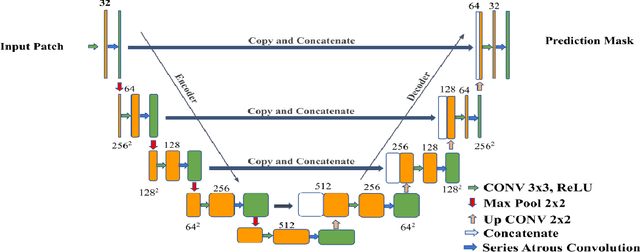
Colorectal cancer is a leading cause of death worldwide. However, early diagnosis dramatically increases the chances of survival, for which it is crucial to identify the tumor in the body. Since its imaging uses high-resolution techniques, annotating the tumor is time-consuming and requires particular expertise. Lately, methods built upon Convolutional Neural Networks(CNNs) have proven to be at par, if not better in many biomedical segmentation tasks. For the task at hand, we propose another CNN-based approach, which uses atrous convolutions and residual connections besides the conventional filters. The training and inference were made using an efficient patch-based approach, which significantly reduced unnecessary computations. The proposed AtResUNet was trained on the DigestPath 2019 Challenge dataset for colorectal cancer segmentation with results having a Dice Coefficient of 0.748.
Detector-SegMentor Network for Skin Lesion Localization and Segmentation
May 13, 2020
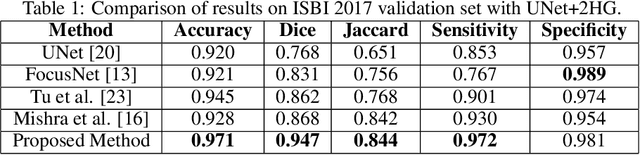
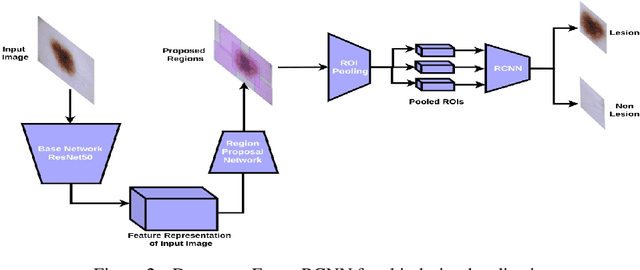

Melanoma is a life-threatening form of skin cancer when left undiagnosed at the early stages. Although there are more cases of non-melanoma cancer than melanoma cancer, melanoma cancer is more deadly. Early detection of melanoma is crucial for the timely diagnosis of melanoma cancer and prohibit its spread to distant body parts. Segmentation of skin lesion is a crucial step in the classification of melanoma cancer from the cancerous lesions in dermoscopic images. Manual segmentation of dermoscopic skin images is very time consuming and error-prone resulting in an urgent need for an intelligent and accurate algorithm. In this study, we propose a simple yet novel network-in-network convolution neural network(CNN) based approach for segmentation of the skin lesion. A Faster Region-based CNN (Faster RCNN) is used for preprocessing to predict bounding boxes of the lesions in the whole image which are subsequently cropped and fed into the segmentation network to obtain the lesion mask. The segmentation network is a combination of the UNet and Hourglass networks. We trained and evaluated our models on ISIC 2018 dataset and also cross-validated on PH\textsuperscript{2} and ISBI 2017 datasets. Our proposed method surpassed the state-of-the-art with Dice Similarity Coefficient of 0.915 and Accuracy 0.959 on ISIC 2018 dataset and Dice Similarity Coefficient of 0.947 and Accuracy 0.971 on ISBI 2017 dataset.