 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect and Segment for Open Vocabulary Object Detection
Dec 23, 2022Open vocabulary object detection has been greatly advanced by the recent development of vision-language pretrained model, which helps recognize novel objects with only semantic categories. The prior works mainly focus on knowledge transferring to the object proposal classification and employ class-agnostic box and mask prediction. In this work, we propose CondHead, a principled dynamic network design to better generalize the box regression and mask segmentation for open vocabulary setting. The core idea is to conditionally parameterize the network heads on semantic embedding and thus the model is guided with class-specific knowledge to better detect novel categories. Specifically, CondHead is composed of two streams of network heads, the dynamically aggregated head and the dynamically generated head. The former is instantiated with a set of static heads that are conditionally aggregated, these heads are optimized as experts and are expected to learn sophisticated prediction. The latter is instantiated with dynamically generated parameters and encodes general class-specific information. With such a conditional design, the detection model is bridged by the semantic embedding to offer strongly generalizable class-wise box and mask prediction. Our method brings significant improvement to the state-of-the-art open vocabulary object detection methods with very minor overhead, e.g., it surpasses a RegionClip model by 3.0 detection AP on novel categories, with only 1.1% more computation.
Image-based Artificial Intelligence empowered surrogate model and shape morpher for real-time blank shape optimisation in the hot stamping process
Dec 01, 2022As the complexity of modern manufacturing technologies increases, traditional trial-and-error design, which requires iterative and expensive simulations, becomes unreliable and time-consuming. This difficulty is especially significant for the design of hot-stamped safety-critical components, such as ultra-high-strength-steel (UHSS) B-pillars. To reduce design costs and ensure manufacturability, scalar-based Artificial-Intelligence-empowered surrogate modelling (SAISM) has been investigated and implemented, which can allow real-time manufacturability-constrained structural design optimisation. However, SAISM suffers from low accuracy and generalisability, and usually requires a high volume of training samples. To solve this problem, an image-based Artificial-intelligence-empowered surrogate modelling (IAISM) approach is developed in this research, in combination with an auto-decoder-based blank shape generator. The IAISM, which is based on a Mask-Res-SE-U-Net architecture, is trained to predict the full thinning field of the as-formed component given an arbitrary blank shape. Excellent prediction performance of IAISM is achieved with only 256 training samples, which indicates the small-data learning nature of engineering AI tasks using structured data representations. The trained auto-decoder, trained Mask-Res-SE-U-Net, and Adam optimiser are integrated to conduct blank optimisation by modifying the latent vector. The optimiser can rapidly find blank shapes that satisfy manufacturability criteria. As a high-accuracy and generalisable surrogate modelling and optimisation tool, the proposed pipeline is promising to be integrated into a full-chain digital twin to conduct real-time, multi-objective design optimisation.
Semantic Communication Enabling Robust Edge Intelligence for Time-Critical IoT Applications
Nov 28, 2022This paper aims to design robust Edge Intelligence using semantic communication for time-critical IoT applications. We systematically analyze the effect of image DCT coefficients on inference accuracy and propose the channel-agnostic effectiveness encoding for offloading by transmitting the most meaningful task data first. This scheme can well utilize all available communication resource and strike a balance between transmission latency and inference accuracy. Then, we design an effectiveness decoding by implementing a novel image augmentation process for convolutional neural network (CNN) training, through which an original CNN model is transformed into a Robust CNN model. We use the proposed training method to generate Robust MobileNet-v2 and Robust ResNet-50. The proposed Edge Intelligence framework consists of the proposed effectiveness encoding and effectiveness decoding. The experimental results show that the effectiveness decoding using the Robust CNN models perform consistently better under various image distortions caused by channel errors or limited communication resource. The proposed Edge Intelligence framework using semantic communication significantly outperforms the conventional approach under latency and data rate constraints, in particular, under ultra stringent deadlines and low data rate.
Design and Prototyping Distributed CNN Inference Acceleration in Edge Computing
Nov 28, 2022



For time-critical IoT applications using deep learning, inference acceleration through distributed computing is a promising approach to meet a stringent deadline. In this paper, we implement a working prototype of a new distributed inference acceleration method HALP using three raspberry Pi 4. HALP accelerates inference by designing a seamless collaboration among edge devices (EDs) in Edge Computing. We maximize the parallelization between communication and computation among the collaborative EDs by optimizing the task partitioning ratio based on the segment-based partitioning. Experimental results show that the distributed inference HALP achieves 1.7x inference acceleration for VGG-16. Then, we combine distributed inference with conventional neural network model compression by setting up different shrinking hyperparameters for MobileNet-V1. In this way, we can further accelerate inference but at the cost of inference accuracy loss. To strike a balance between latency and accuracy, we propose dynamic model selection to select a model which provides the highest accuracy within the latency constraint. It is shown that the model selection with distributed inference HALP can significantly improve service reliability compared to the conventional stand-alone computation.
Attention-based Feature Compression for CNN Inference Offloading in Edge Computing
Nov 24, 2022This paper studies the computational offloading of CNN inference in device-edge co-inference systems. Inspired by the emerging paradigm semantic communication, we propose a novel autoencoder-based CNN architecture (AECNN), for effective feature extraction at end-device. We design a feature compression module based on the channel attention method in CNN, to compress the intermediate data by selecting the most important features. To further reduce communication overhead, we can use entropy encoding to remove the statistical redundancy in the compressed data. At the receiver, we design a lightweight decoder to reconstruct the intermediate data through learning from the received compressed data to improve accuracy. To fasten the convergence, we use a step-by-step approach to train the neural networks obtained based on ResNet-50 architecture. Experimental results show that AECNN can compress the intermediate data by more than 256x with only about 4% accuracy loss, which outperforms the state-of-the-art work, BottleNet++. Compared to offloading inference task directly to edge server, AECNN can complete inference task earlier, in particular, under poor wireless channel condition, which highlights the effectiveness of AECNN in guaranteeing higher accuracy within time constraint.
Safe Control and Learning Using Generalized Action Governor
Nov 22, 2022This paper introduces the Generalized Action Governor, which is a supervisory scheme for augmenting a nominal closed-loop system with the capability of strictly handling constraints. After presenting its theory for general systems and introducing tailored design approaches for linear and discrete systems, we discuss its application to safe online learning, which aims to safely evolve control parameters using real-time data to improve performance for uncertain systems. In particular, we propose two safe learning algorithms based on integration of reinforcement learning/data-driven Koopman operator-based control with the generalized action governor. The developments are illustrated with a numerical example.
Detection of Strongly Lensed Arcs in Galaxy Clusters with Transformers
Nov 11, 2022Strong lensing in galaxy clusters probes properties of dense cores of dark matter halos in mass, studies the distant universe at flux levels and spatial resolutions otherwise unavailable, and constrains cosmological models independently. The next-generation large scale sky imaging surveys are expected to discover thousands of cluster-scale strong lenses, which would lead to unprecedented opportunities for applying cluster-scale strong lenses to solve astrophysical and cosmological problems. However, the large dataset challenges astronomers to identify and extract strong lensing signals, particularly strongly lensed arcs, because of their complexity and variety. Hence, we propose a framework to detect cluster-scale strongly lensed arcs, which contains a transformer-based detection algorithm and an image simulation algorithm. We embed prior information of strongly lensed arcs at cluster-scale into the training data through simulation and then train the detection algorithm with simulated images. We use the trained transformer to detect strongly lensed arcs from simulated and real data. Results show that our approach could achieve 99.63 % accuracy rate, 90.32 % recall rate, 85.37 % precision rate and 0.23 % false positive rate in detection of strongly lensed arcs from simulated images and could detect almost all strongly lensed arcs in real observation images. Besides, with an interpretation method, we have shown that our method could identify important information embedded in simulated data. Next step, to test the reliability and usability of our approach, we will apply it to available observations (e.g., DESI Legacy Imaging Surveys) and simulated data of upcoming large-scale sky surveys, such as the Euclid and the CSST.
Graph Reinforcement Learning-based CNN Inference Offloading in Dynamic Edge Computing
Oct 24, 2022This paper studies the computational offloading of CNN inference in dynamic multi-access edge computing (MEC) networks. To address the uncertainties in communication time and Edge servers' available capacity, we use early-exit mechanism to terminate the computation earlier to meet the deadline of inference tasks. We design a reward function to trade off the communication, computation and inference accuracy, and formulate the offloading problem of CNN inference as a maximization problem with the goal of maximizing the average inference accuracy and throughput in long term. To solve the maximization problem, we propose a graph reinforcement learning-based early-exit mechanism (GRLE), which outperforms the state-of-the-art work, deep reinforcement learning-based online offloading (DROO) and its enhanced method, DROO with early-exit mechanism (DROOE), under different dynamic scenarios. The experimental results show that GRLE achieves the average accuracy up to 3.41x over graph reinforcement learning (GRL) and 1.45x over DROOE, which shows the advantages of GRLE for offloading decision-making in dynamic MEC.
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Oct 11, 2022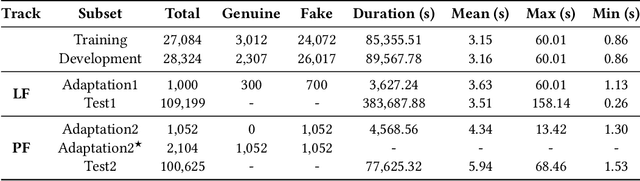
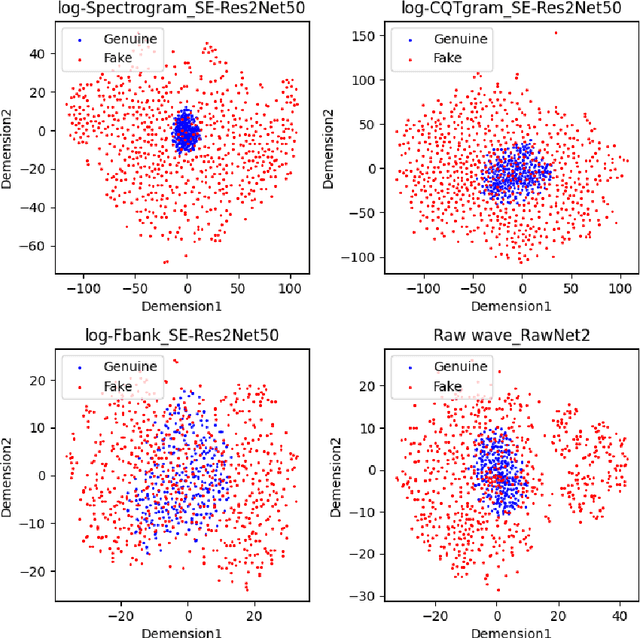
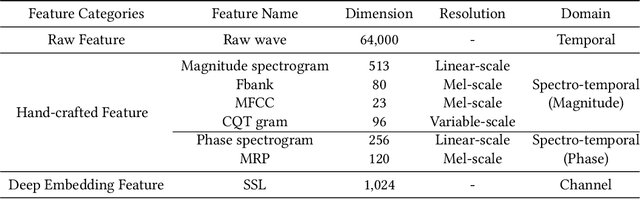

The Audio Deep Synthesis Detection (ADD) Challenge has been held to detect generated human-like speech. With our submitted system, this paper provides an overall assessment of track 1 (Low-quality Fake Audio Detection) and track 2 (Partially Fake Audio Detection). In this paper, spectro-temporal artifacts were detected using raw temporal signals, spectral features, as well as deep embedding features. To address track 1, low-quality data augmentation, domain adaptation via finetuning, and various complementary feature information fusion were aggregated in our system. Furthermore, we analyzed the clustering characteristics of subsystems with different features by visualization method and explained the effectiveness of our proposed greedy fusion strategy. As for track 2, frame transition and smoothing were detected using self-supervised learning structure to capture the manipulation of PF attacks in the time domain. We ranked 4th and 5th in track 1 and track 2, respectively.
KG-MTT-BERT: Knowledge Graph Enhanced BERT for Multi-Type Medical Text Classification
Oct 08, 2022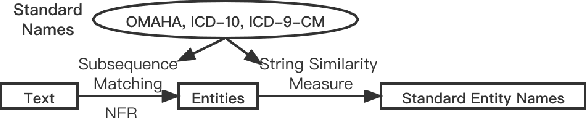
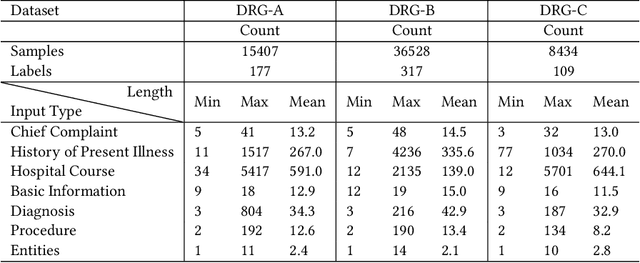
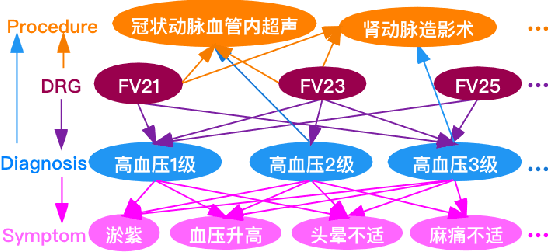
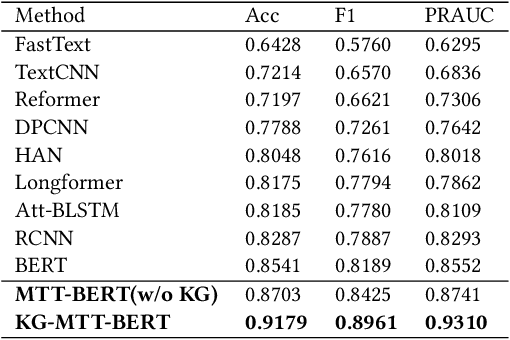
Medical text learning has recently emerged as a promising area to improve healthcare due to the wide adoption of electronic health record (EHR) systems. The complexity of the medical text such as diverse length, mixed text types, and full of medical jargon, poses a great challenge for developing effective deep learning models. BERT has presented state-of-the-art results in many NLP tasks, such as text classification and question answering. However, the standalone BERT model cannot deal with the complexity of the medical text, especially the lengthy clinical notes. Herein, we develop a new model called KG-MTT-BERT (Knowledge Graph Enhanced Multi-Type Text BERT) by extending the BERT model for long and multi-type text with the integration of the medical knowledge graph. Our model can outperform all baselines and other state-of-the-art models in diagnosis-related group (DRG) classification, which requires comprehensive medical text for accurate classification. We also demonstrated that our model can effectively handle multi-type text and the integration of medical knowledge graph can significantly improve the performance.