 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Unified Multimodal Representation Learning for Autonomous Driving
Mar 09, 2026Contrastive Language-Image Pre-training (CLIP) has shown impressive performance in aligning visual and textual representations. Recent studies have extended this paradigm to 3D vision to improve scene understanding for autonomous driving. A common strategy is to employ pairwise cosine similarity between modalities to guide the training of a 3D encoder. However, considering the similarity between individual modality pairs rather than all modalities jointly fails to ensure consistent and unified alignment across the entire multimodal space. In this paper, we propose a Contrastive Tensor Pre-training (CTP) framework that simultaneously aligns multiple modalities in a unified embedding space to enhance end-to-end autonomous driving. Compared with pairwise cosine similarity alignment, our method extends the 2D similarity matrix into a multimodal similarity tensor. Furthermore, we introduce a tensor loss to enable joint contrastive learning across all modalities. For experimental validation of our framework, we construct a text-image-point cloud triplet dataset derived from existing autonomous driving datasets. The results show that our proposed unified multimodal alignment framework achieves favorable performance for both scenarios: (i) aligning a 3D encoder with pretrained CLIP encoders, and (ii) pretraining all encoders from scratch.
NaviDriveVLM: Decoupling High-Level Reasoning and Motion Planning for Autonomous Driving
Mar 09, 2026Vision-language models (VLMs) have emerged as a promising direction for end-to-end autonomous driving (AD) by jointly modeling visual observations, driving context, and language-based reasoning. However, existing VLM-based systems face a trade-off between high-level reasoning and motion planning: large models offer strong semantic understanding but are costly to adapt for precise control, whereas small VLM models can be fine-tuned efficiently but often exhibit weaker reasoning. We propose NaviDriveVLM, a decoupled framework that separates reasoning from action generation using a large-scale Navigator and a lightweight trainable Driver. This design preserves reasoning ability, reduces training cost, and provides an explicit interpretable intermediate representation for downstream planning. Experiments on the nuScenes benchmark show that NaviDriveVLM outperforms large VLM baselines in end-to-end motion planning.
A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
Mar 31, 2025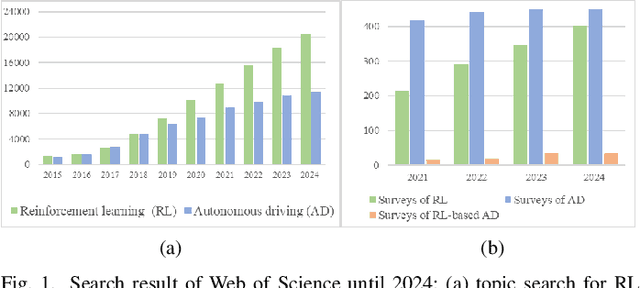

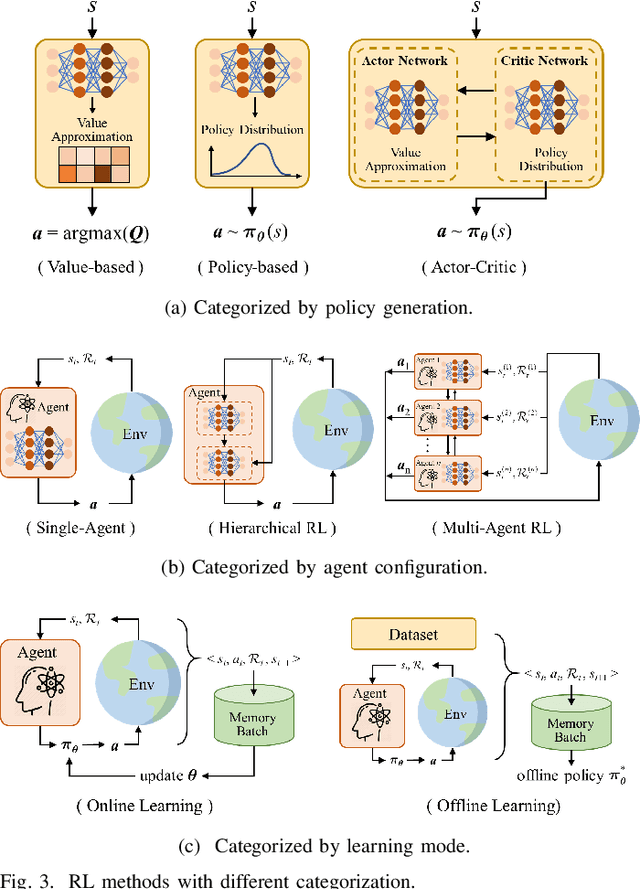
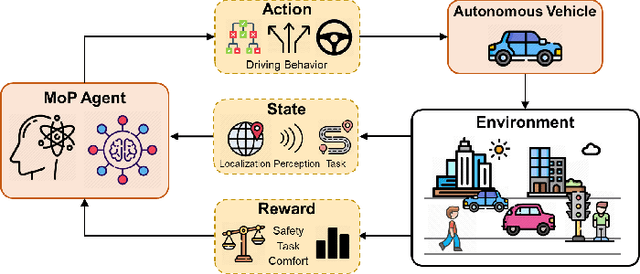
Reinforcement learning (RL), with its ability to explore and optimize policies in complex, dynamic decision-making tasks, has emerged as a promising approach to addressing motion planning (MoP) challenges in autonomous driving (AD). Despite rapid advancements in RL and AD, a systematic description and interpretation of the RL design process tailored to diverse driving tasks remains underdeveloped. This survey provides a comprehensive review of RL-based MoP for AD, focusing on lessons from task-specific perspectives. We first outline the fundamentals of RL methodologies, and then survey their applications in MoP, analyzing scenario-specific features and task requirements to shed light on their influence on RL design choices. Building on this analysis, we summarize key design experiences, extract insights from various driving task applications, and provide guidance for future implementations. Additionally, we examine the frontier challenges in RL-based MoP, review recent efforts to addresse these challenges, and propose strategies for overcoming unresolved issues.
Learning Autonomy: Off-Road Navigation Enhanced by Human Input
Feb 26, 2025In the area of autonomous driving, navigating off-road terrains presents a unique set of challenges, from unpredictable surfaces like grass and dirt to unexpected obstacles such as bushes and puddles. In this work, we present a novel learning-based local planner that addresses these challenges by directly capturing human driving nuances from real-world demonstrations using only a monocular camera. The key features of our planner are its ability to navigate in challenging off-road environments with various terrain types and its fast learning capabilities. By utilizing minimal human demonstration data (5-10 mins), it quickly learns to navigate in a wide array of off-road conditions. The local planner significantly reduces the real world data required to learn human driving preferences. This allows the planner to apply learned behaviors to real-world scenarios without the need for manual fine-tuning, demonstrating quick adjustment and adaptability in off-road autonomous driving technology.
Targeted collapse regularized autoencoder for anomaly detection: black hole at the center
Jun 22, 2023



Autoencoders have been extensively used in the development of recent anomaly detection techniques. The premise of their application is based on the notion that after training the autoencoder on normal training data, anomalous inputs will exhibit a significant reconstruction error. Consequently, this enables a clear differentiation between normal and anomalous samples. In practice, however, it is observed that autoencoders can generalize beyond the normal class and achieve a small reconstruction error on some of the anomalous samples. To improve the performance, various techniques propose additional components and more sophisticated training procedures. In this work, we propose a remarkably straightforward alternative: instead of adding neural network components, involved computations, and cumbersome training, we complement the reconstruction loss with a computationally light term that regulates the norm of representations in the latent space. The simplicity of our approach minimizes the requirement for hyperparameter tuning and customization for new applications which, paired with its permissive data modality constraint, enhances the potential for successful adoption across a broad range of applications. We test the method on various visual and tabular benchmarks and demonstrate that the technique matches and frequently outperforms alternatives. We also provide a theoretical analysis and numerical simulations that help demonstrate the underlying process that unfolds during training and how it can help with anomaly detection. This mitigates the black-box nature of autoencoder-based anomaly detection algorithms and offers an avenue for further investigation of advantages, fail cases, and potential new directions.
KARNet: Kalman Filter Augmented Recurrent Neural Network for Learning World Models in Autonomous Driving Tasks
May 24, 2023



Autonomous driving has received a great deal of attention in the automotive industry and is often seen as the future of transportation. The development of autonomous driving technology has been greatly accelerated by the growth of end-to-end machine learning techniques that have been successfully used for perception, planning, and control tasks. An important aspect of autonomous driving planning is knowing how the environment evolves in the immediate future and taking appropriate actions. An autonomous driving system should effectively use the information collected from the various sensors to form an abstract representation of the world to maintain situational awareness. For this purpose, deep learning models can be used to learn compact latent representations from a stream of incoming data. However, most deep learning models are trained end-to-end and do not incorporate any prior knowledge (e.g., from physics) of the vehicle in the architecture. In this direction, many works have explored physics-infused neural network (PINN) architectures to infuse physics models during training. Inspired by this observation, we present a Kalman filter augmented recurrent neural network architecture to learn the latent representation of the traffic flow using front camera images only. We demonstrate the efficacy of the proposed model in both imitation and reinforcement learning settings using both simulated and real-world datasets. The results show that incorporating an explicit model of the vehicle (states estimated using Kalman filtering) in the end-to-end learning significantly increases performance.
Experience-Based Evolutionary Algorithms for Expensive Optimization
Apr 09, 2023



Optimization algorithms are very different from human optimizers. A human being would gain more experiences through problem-solving, which helps her/him in solving a new unseen problem. Yet an optimization algorithm never gains any experiences by solving more problems. In recent years, efforts have been made towards endowing optimization algorithms with some abilities of experience learning, which is regarded as experience-based optimization. In this paper, we argue that hard optimization problems could be tackled efficiently by making better use of experiences gained in related problems. We demonstrate our ideas in the context of expensive optimization, where we aim to find a near-optimal solution to an expensive optimization problem with as few fitness evaluations as possible. To achieve this, we propose an experience-based surrogate-assisted evolutionary algorithm (SAEA) framework to enhance the optimization efficiency of expensive problems, where experiences are gained across related expensive tasks via a novel meta-learning method. These experiences serve as the task-independent parameters of a deep kernel learning surrogate, then the solutions sampled from the target task are used to adapt task-specific parameters for the surrogate. With the help of experience learning, competitive regression-based surrogates can be initialized using only 1$d$ solutions from the target task ($d$ is the dimension of the decision space). Our experimental results on expensive multi-objective and constrained optimization problems demonstrate that experiences gained from related tasks are beneficial for the saving of evaluation budgets on the target problem.
Safe Control and Learning Using Generalized Action Governor
Nov 22, 2022



This paper introduces the Generalized Action Governor, which is a supervisory scheme for augmenting a nominal closed-loop system with the capability of strictly handling constraints. After presenting its theory for general systems and introducing tailored design approaches for linear and discrete systems, we discuss its application to safe online learning, which aims to safely evolve control parameters using real-time data to improve performance for uncertain systems. In particular, we propose two safe learning algorithms based on integration of reinforcement learning/data-driven Koopman operator-based control with the generalized action governor. The developments are illustrated with a numerical example.
Robust Action Governor for Uncertain Piecewise Affine Systems with Non-convex Constraints and Safe Reinforcement Learning
Jul 17, 2022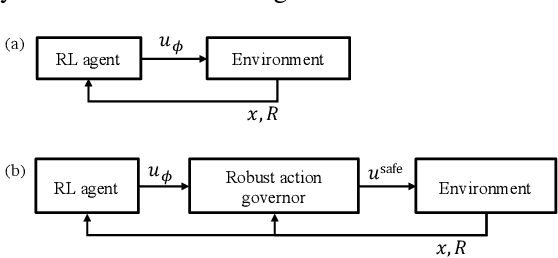
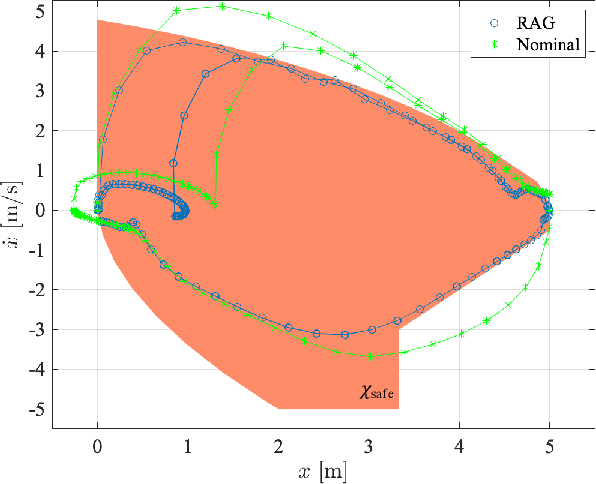
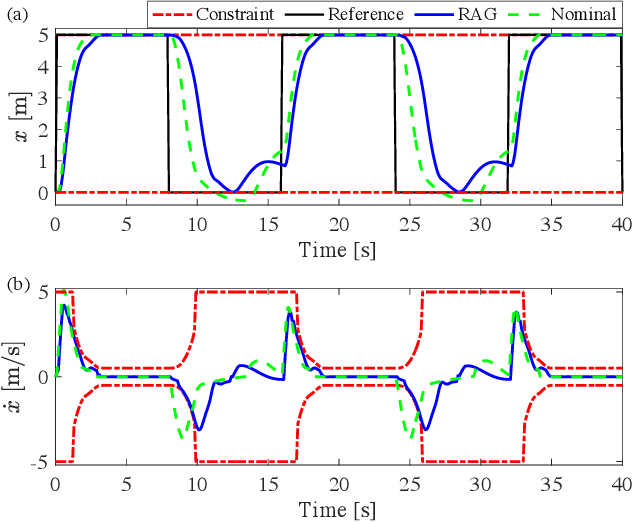
The action governor is an add-on scheme to a nominal control loop that monitors and adjusts the control actions to enforce safety specifications expressed as pointwise-in-time state and control constraints. In this paper, we introduce the Robust Action Governor (RAG) for systems the dynamics of which can be represented using discrete-time Piecewise Affine (PWA) models with both parametric and additive uncertainties and subject to non-convex constraints. We develop the theoretical properties and computational approaches for the RAG. After that, we introduce the use of the RAG for realizing safe Reinforcement Learning (RL), i.e., ensuring all-time constraint satisfaction during online RL exploration-and-exploitation process. This development enables safe real-time evolution of the control policy and adaptation to changes in the operating environment and system parameters (due to aging, damage, etc.). We illustrate the effectiveness of the RAG in constraint enforcement and safe RL using the RAG by considering their applications to a soft-landing problem of a mass-spring-damper system.
Robust AI Driving Strategy for Autonomous Vehicles
Jul 16, 2022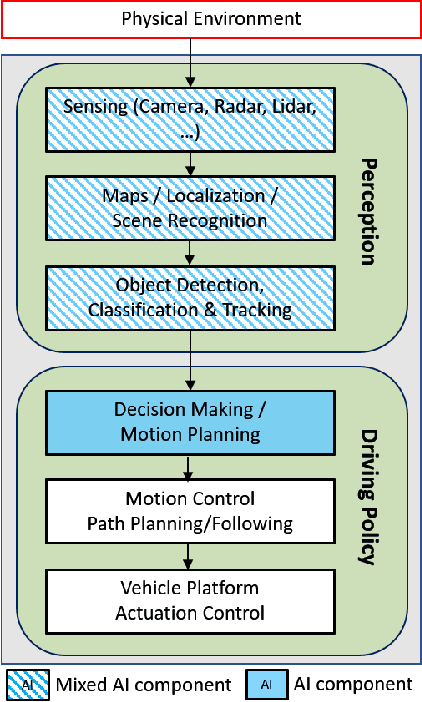

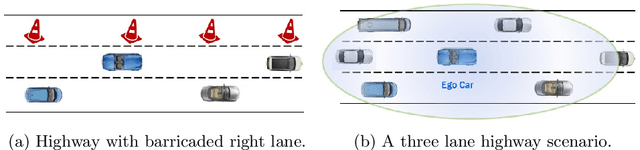
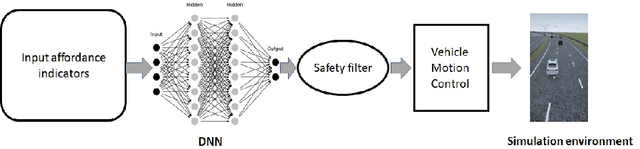
There has been significant progress in sensing, perception, and localization for automated driving, However, due to the wide spectrum of traffic/road structure scenarios and the long tail distribution of human driver behavior, it has remained an open challenge for an intelligent vehicle to always know how to make and execute the best decision on road given available sensing / perception / localization information. In this chapter, we talk about how artificial intelligence and more specifically, reinforcement learning, can take advantage of operational knowledge and safety reflex to make strategical and tactical decisions. We discuss some challenging problems related to the robustness of reinforcement learning solutions and their implications to the practical design of driving strategies for autonomous vehicles. We focus on automated driving on highway and the integration of reinforcement learning, vehicle motion control, and control barrier function, leading to a robust AI driving strategy that can learn and adapt safely.