 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimble: Efficiently Compiling Dynamic Neural Networks for Model Inference
Jun 04, 2020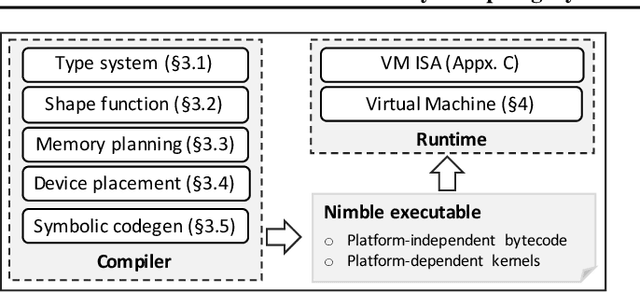
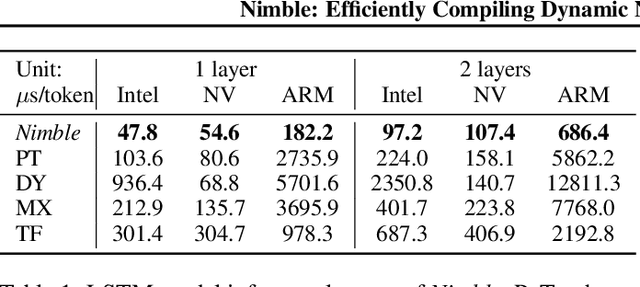
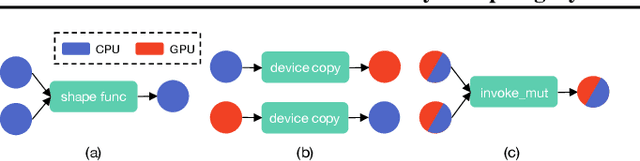
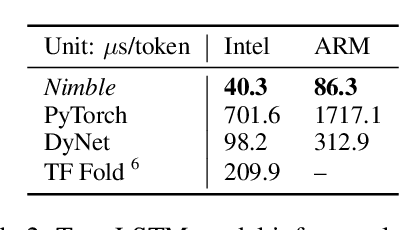
Modern deep neural networks increasingly make use of features such as dynamic control flow, data structures and dynamic tensor shapes. Existing deep learning systems focus on optimizing and executing static neural networks which assume a pre-determined model architecture and input data shapes--assumptions which are violated by dynamic neural networks. Therefore, executing dynamic models with deep learning systems is currently both inflexible and sub-optimal, if not impossible. Optimizing dynamic neural networks is more challenging than static neural networks; optimizations must consider all possible execution paths and tensor shapes. This paper proposes Nimble, a high-performance and flexible system to optimize, compile, and execute dynamic neural networks on multiple platforms. Nimble handles model dynamism by introducing a dynamic type system, a set of dynamism-oriented optimizations, and a light-weight virtual machine runtime. Our evaluation demonstrates that Nimble outperforms state-of-the-art deep learning frameworks and runtime systems for dynamic neural networks by up to 20x on hardware platforms including Intel CPUs, ARM CPUs, and Nvidia GPUs.
Learning Context-Based Non-local Entropy Modeling for Image Compression
May 10, 2020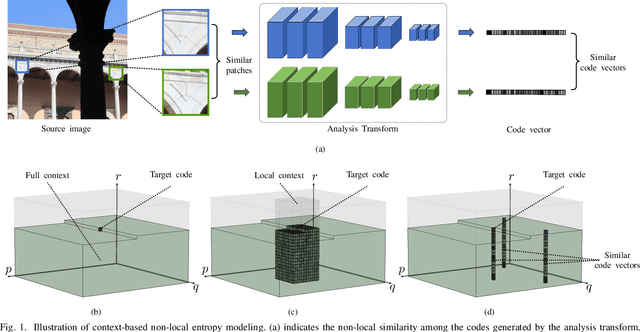
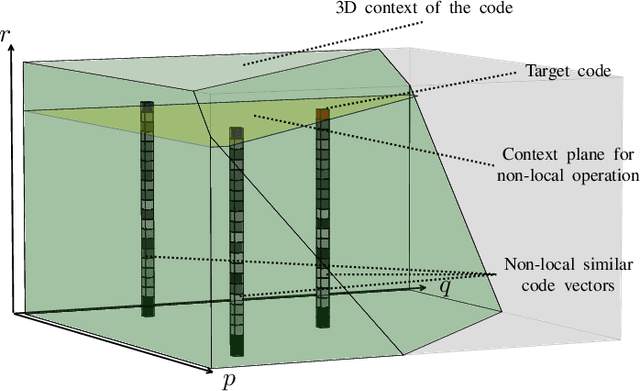
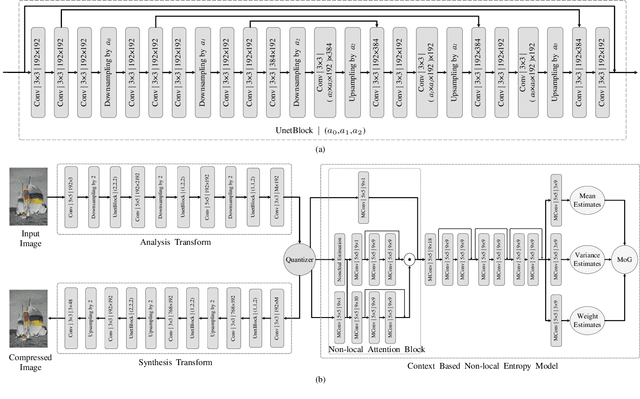
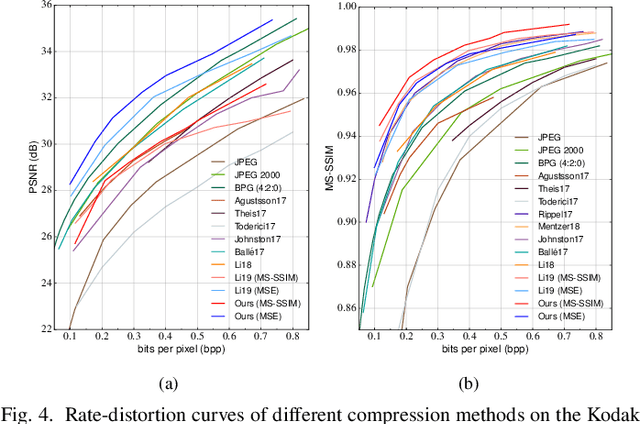
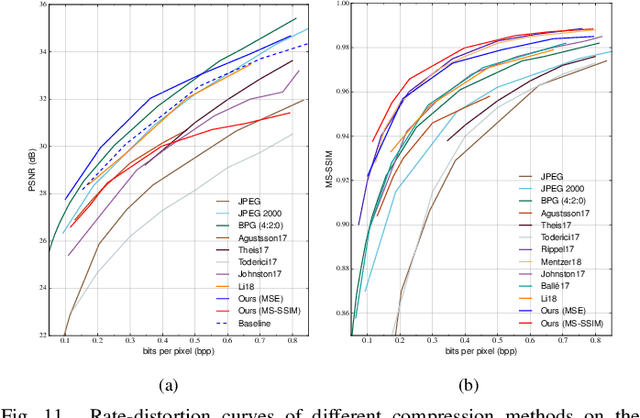
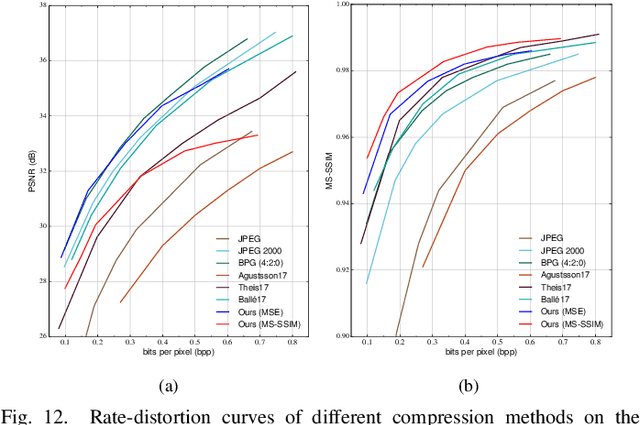
The entropy of the codes usually serves as the rate loss in the recent learned lossy image compression methods. Precise estimation of the probabilistic distribution of the codes plays a vital role in the performance. However, existing deep learning based entropy modeling methods generally assume the latent codes are statistically independent or depend on some side information or local context, which fails to take the global similarity within the context into account and thus hinder the accurate entropy estimation. To address this issue, we propose a non-local operation for context modeling by employing the global similarity within the context. Specifically, we first introduce the proxy similarity functions and spatial masks to handle the missing reference problem in context modeling. Then, we combine the local and the global context via a non-local attention block and employ it in masked convolutional networks for entropy modeling. The entropy model is further adopted as the rate loss in a joint rate-distortion optimization to guide the training of the analysis transform and the synthesis transform network in transforming coding framework. Considering that the width of the transforms is essential in training low distortion models, we finally produce a U-Net block in the transforms to increase the width with manageable memory consumption and time complexity. Experiments on Kodak and Tecnick datasets demonstrate the superiority of the proposed context-based non-local attention block in entropy modeling and the U-Net block in low distortion compression against the existing image compression standards and recent deep image compression models.
Improving Semantic Segmentation via Self-Training
May 06, 2020
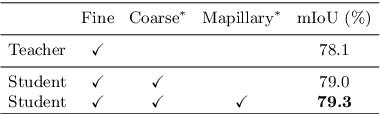
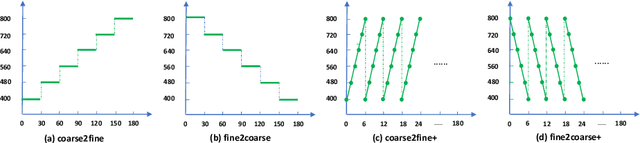
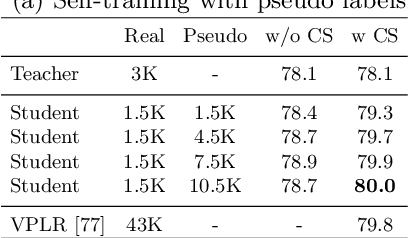
Deep learning usually achieves the best results with complete supervision. In the case of semantic segmentation, this means that large amounts of pixelwise annotations are required to learn accurate models. In this paper, we show that we can obtain state-of-the-art results using a semi-supervised approach, specifically a self-training paradigm. We first train a teacher model on labeled data, and then generate pseudo labels on a large set of unlabeled data. Our robust training framework can digest human-annotated and pseudo labels jointly and achieve top performances on Cityscapes, CamVid and KITTI datasets while requiring significantly less supervision. We also demonstrate the effectiveness of self-training on a challenging cross-domain generalization task, outperforming conventional finetuning method by a large margin. Lastly, to alleviate the computational burden caused by the large amount of pseudo labels, we propose a fast training schedule to accelerate the training of segmentation models by up to 2x without performance degradation.
ResNeSt: Split-Attention Networks
Apr 19, 2020
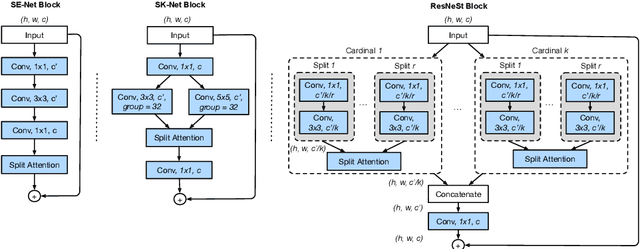
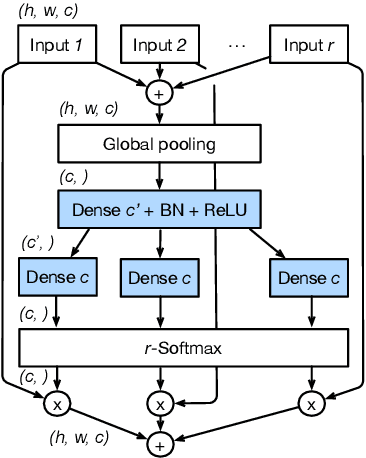
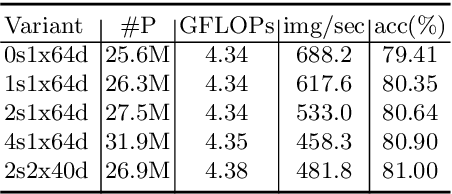
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Mar 13, 2020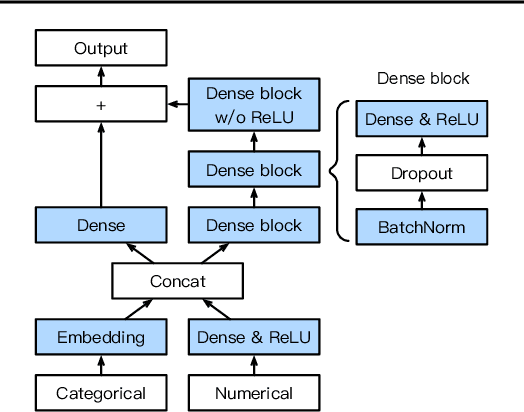

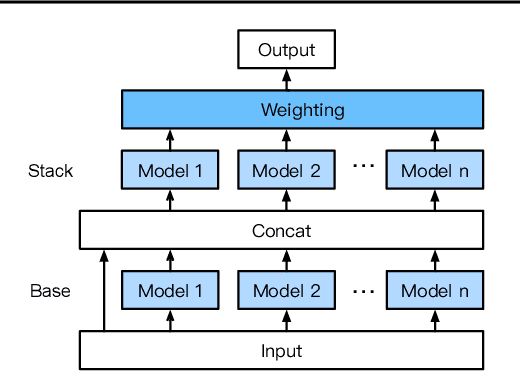

We introduce AutoGluon-Tabular, an open-source AutoML framework that requires only a single line of Python to train highly accurate machine learning models on an unprocessed tabular dataset such as a CSV file. Unlike existing AutoML frameworks that primarily focus on model/hyperparameter selection, AutoGluon-Tabular succeeds by ensembling multiple models and stacking them in multiple layers. Experiments reveal that our multi-layer combination of many models offers better use of allocated training time than seeking out the best. A second contribution is an extensive evaluation of public and commercial AutoML platforms including TPOT, H2O, AutoWEKA, auto-sklearn, AutoGluon, and Google AutoML Tables. Tests on a suite of 50 classification and regression tasks from Kaggle and the OpenML AutoML Benchmark reveal that AutoGluon is faster, more robust, and much more accurate. We find that AutoGluon often even outperforms the best-in-hindsight combination of all of its competitors. In two popular Kaggle competitions, AutoGluon beat 99% of the participating data scientists after merely 4h of training on the raw data.
GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing
Jul 09, 2019
We present GluonCV and GluonNLP, the deep learning toolkits for computer vision and natural language processing based on Apache MXNet (incubating). These toolkits provide state-of-the-art pre-trained models, training scripts, and training logs, to facilitate rapid prototyping and promote reproducible research. We also provide modular APIs with flexible building blocks to enable efficient customization. Leveraging the MXNet ecosystem, the deep learning models in GluonCV and GluonNLP can be deployed onto a variety of platforms with different programming languages. Benefiting from open source under the Apache 2.0 license, GluonCV and GluonNLP have attracted 100 contributors worldwide on GitHub. Models of GluonCV and GluonNLP have been downloaded for more than 1.6 million times in fewer than 10 months.
Efficient and Effective Context-Based Convolutional Entropy Modeling for Image Compression
Jun 24, 2019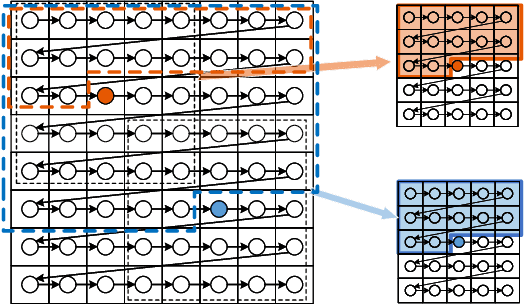
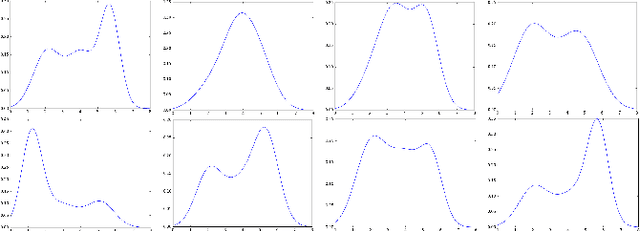
It has long been understood that precisely estimating the probabilistic structure of natural visual images is crucial for image compression. Despite the remarkable success of recent end-to-end optimized image compression, the latent code representation is assumed to be fully statistically factorized such that the entropy modeling is feasible. Here we describe context-based convolutional networks (CCNs) that exploit statistical redundancies in the codes for improved entropy modeling. We introduce a 3D zigzag coding order together with a 3D code dividing technique to define proper context and to achieve parallel entropy decoding, both of which boil down to place translation-invariant binary masks on convolution filters of CCNs. We demonstrate the power of CCNs for entropy modeling in both lossless and lossy image compression. For the former, we directly apply a CCN to binarized image planes for estimating the Bernoulli distribution of each code. For the latter, the categorical distribution of each code is represented by a discretized mixture of Gaussian distributions, whose parameters are estimated by three CCNs. We jointly optimize the CCN-based entropy model with analysis and synthesis transforms for rate-distortion performance. Experiments on two image datasets show that the proposed lossless and lossy image compression methods based on CCNs generally exhibit better compression performance than existing methods with manageable computational complexity.
Dynamic Mini-batch SGD for Elastic Distributed Training: Learning in the Limbo of Resources
May 02, 2019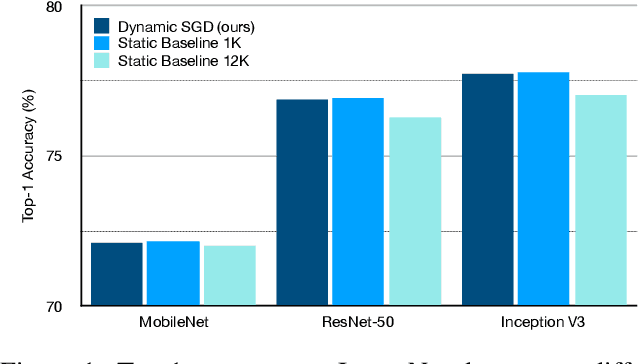
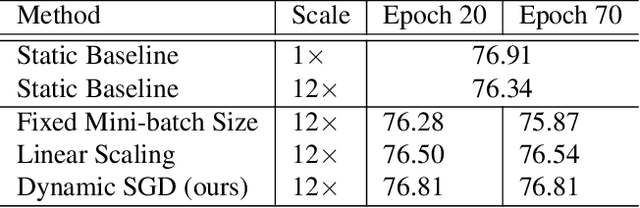
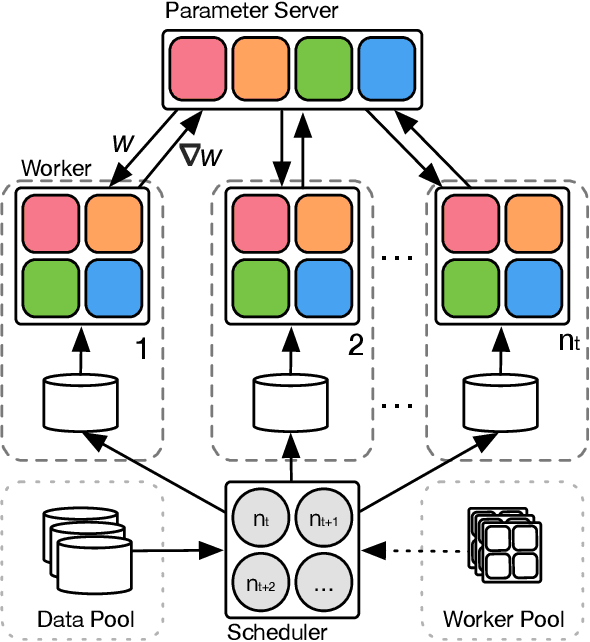
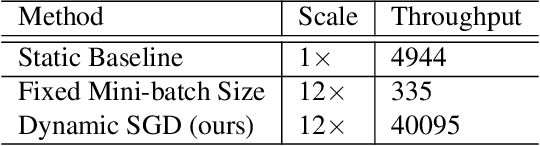
With an increasing demand for training powers for deep learning algorithms and the rapid growth of computation resources in data centers, it is desirable to dynamically schedule different distributed deep learning tasks to maximize resource utilization and reduce cost. In this process, different tasks may receive varying numbers of machines at different time, a setting we call elastic distributed training. Despite the recent successes in large mini-batch distributed training, these methods are rarely tested in elastic distributed training environments and suffer degraded performance in our experiments, when we adjust the learning rate linearly immediately with respect to the batch size. One difficulty we observe is that the noise in the stochastic momentum estimation is accumulated over time and will have delayed effects when the batch size changes. We therefore propose to smoothly adjust the learning rate over time to alleviate the influence of the noisy momentum estimation. Our experiments on image classification, object detection and semantic segmentation have demonstrated that our proposed Dynamic SGD method achieves stabilized performance when varying the number of GPUs from 8 to 128. We also provide theoretical understanding on the optimality of linear learning rate scheduling and the effects of stochastic momentum.
Language Models with Transformers
Apr 20, 2019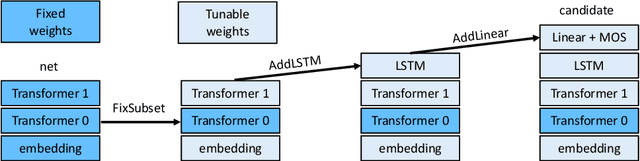
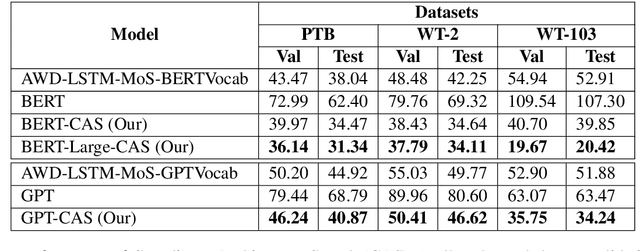
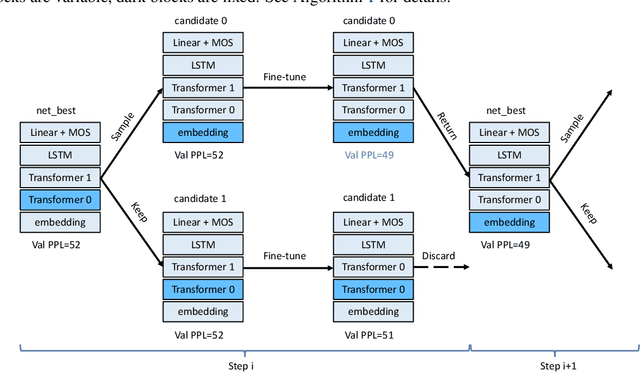
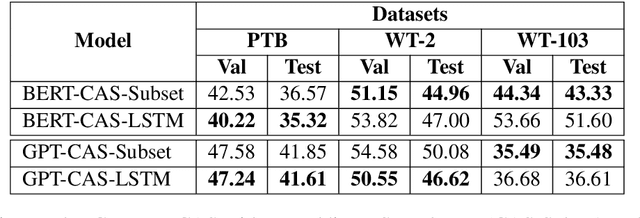
The Transformer architecture is superior to RNN-based models in computational efficiency. Recently, GPT and BERT demonstrate the efficacy of Transformer models on various NLP tasks using pre-trained language models on large-scale corpora. Surprisingly, these Transformer architectures are suboptimal for language model itself. Neither self-attention nor the positional encoding in the Transformer is able to efficiently incorporate the word-level sequential context crucial to language modeling. In this paper, we explore effective Transformer architectures for language model, including adding additional LSTM layers to better capture the sequential context while still keeping the computation efficient. We propose Coordinate Architecture Search (CAS) to find an effective architecture through iterative refinement of the model. Experimental results on the PTB, WikiText-2, and WikiText-103 show that CAS achieves perplexities between 20.42 and 34.11 on all problems, i.e. on average an improvement of 12.0 perplexity units compared to state-of-the-art LSTMs.
Bag of Freebies for Training Object Detection Neural Networks
Apr 12, 2019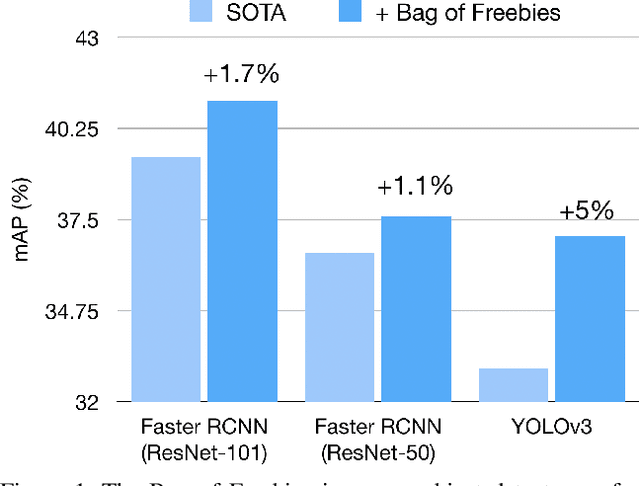
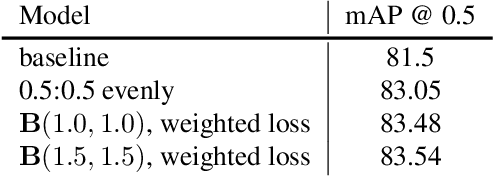


Training heuristics greatly improve various image classification model accuracies~\cite{he2018bag}. Object detection models, however, have more complex neural network structures and optimization targets. The training strategies and pipelines dramatically vary among different models. In this works, we explore training tweaks that apply to various models including Faster R-CNN and YOLOv3. These tweaks do not change the model architectures, therefore, the inference costs remain the same. Our empirical results demonstrate that, however, these freebies can improve up to 5% absolute precision compared to state-of-the-art baselines.