 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKascade: A Practical Sparse Attention Method for Long-Context LLM Inference
Dec 18, 2025



Attention is the dominant source of latency during long-context LLM inference, an increasingly popular workload with reasoning models and RAG. We propose Kascade, a training-free sparse attention method that leverages known observations such as 1) post-softmax attention is intrinsically sparse, and 2) the identity of high-weight keys is stable across nearby layers. Kascade computes exact Top-k indices in a small set of anchor layers, then reuses those indices in intermediate reuse layers. The anchor layers are selected algorithmically, via a dynamic-programming objective that maximizes cross-layer similarity over a development set, allowing easy deployment across models. The method incorporates efficient implementation constraints (e.g. tile-level operations), across both prefill and decode attention. The Top-k selection and reuse in Kascade is head-aware and we show in our experiments that this is critical for high accuracy. Kascade achieves up to 4.1x speedup in decode attention and 2.2x speedup in prefill attention over FlashAttention-3 baseline on H100 GPUs while closely matching dense attention accuracy on long-context benchmarks such as LongBench and AIME-24.
TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference
May 16, 2025Distributed inference of large language models (LLMs) can introduce overheads of up to 20% even over GPUs connected via high-speed interconnects such as NVLINK. Multiple techniques have been proposed to mitigate these overheads by decomposing computations into finer-grained tasks and overlapping communication with sub-tasks as they complete. However, fine-grained decomposition of a large computation into many smaller computations on GPUs results in overheads. Further, the communication itself uses many streaming multiprocessors (SMs), adding to the overhead. We present TokenWeave to address these challenges. TokenWeave proposes a Token-Splitting technique that divides the tokens in the inference batch into two approximately equal subsets in a wave-aware manner. The computation of one subset is then overlapped with the communication of the other. In addition, TokenWeave optimizes the order of the layer normalization computation with respect to communication operations and implements a novel fused AllReduce-RMSNorm kernel carefully leveraging Multimem instruction support available on NVIDIA Hopper GPUs. These optimizations allow TokenWeave to perform communication and RMSNorm using only 2-8 SMs. Moreover, our kernel enables the memory bound RMSNorm to be overlapped with the other batch's computation, providing additional gains. Our evaluations demonstrate up to 29% latency gains and up to 26% throughput gains across multiple models and workloads. In several settings, TokenWeave results in better performance compared to an equivalent model with all communication removed.
Niyama : Breaking the Silos of LLM Inference Serving
Mar 28, 2025



The widespread adoption of Large Language Models (LLMs) has enabled diverse applications with very different latency requirements. Existing LLM serving frameworks rely on siloed infrastructure with coarse-grained workload segregation -- interactive and batch -- leading to inefficient resource utilization and limited support for fine-grained Quality-of-Service (QoS) differentiation. This results in operational inefficiencies, over-provisioning and poor load management during traffic surges. We present Niyama, a novel QoS-driven inference serving system that enables efficient co-scheduling of diverse workloads on shared infrastructure. Niyama introduces fine-grained QoS classification allowing applications to specify precise latency requirements, and dynamically adapts scheduling decisions based on real-time system state. Leveraging the predictable execution characteristics of LLM inference, Niyama implements a dynamic chunking mechanism to improve overall throughput while maintaining strict QoS guarantees. Additionally, Niyama employs a hybrid prioritization policy that balances fairness and efficiency, and employs selective request relegation that enables graceful service degradation during overload conditions. Our evaluation demonstrates that Niyama increases serving capacity by 32% compared to current siloed deployments, while maintaining QoS guarantees. Notably, under extreme load, our system reduces SLO violations by an order of magnitude compared to current strategies.
Accuracy is Not All You Need
Jul 12, 2024



When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on various benchmarks.If the accuracies of the baseline model and the compressed model are close, it is assumed that there was negligible degradation in quality.However, even when the accuracy of baseline and compressed model are similar, we observe the phenomenon of flips, wherein answers change from correct to incorrect and vice versa in proportion.We conduct a detailed study of metrics across multiple compression techniques, models and datasets, demonstrating that the behavior of compressed models as visible to end-users is often significantly different from the baseline model, even when accuracy is similar.We further evaluate compressed models qualitatively and quantitatively using MT-Bench and show that compressed models are significantly worse than baseline models in this free-form generative task.Thus, we argue that compression techniques should also be evaluated using distance metrics.We propose two such metrics, KL-Divergence and flips, and show that they are well correlated.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024



Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024



Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024



Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Aug 31, 2023



Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill phase effectively saturates GPU compute at small batch sizes, the decode phase results in low compute utilization as it generates one token at a time per request. The varying prefill and decode times also lead to imbalance across micro-batches when using pipeline parallelism, resulting in further inefficiency due to bubbles. We present SARATHI to address these challenges. SARATHI employs chunked-prefills, which splits a prefill request into equal sized chunks, and decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests 'piggyback' and cost up to an order of magnitude less compared to a decode-only batch. Chunked-prefills allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform compute design of these batches ameliorates the imbalance between micro-batches, significantly reducing pipeline bubbles. Our techniques yield significant improvements in inference performance across models and hardware. For the LLaMA-13B model on A6000 GPU, SARATHI improves decode throughput by up to 10x, and accelerates end-to-end throughput by up to 1.33x. For LLaMa-33B on A100 GPU, we achieve 1.25x higher end-to-end-throughput and up to 4.25x higher decode throughput. When used with pipeline parallelism on GPT-3, SARATHI reduces bubbles by 6.29x, resulting in an end-to-end throughput improvement of 1.91x.
"Can't Take the Pressure?": Examining the Challenges of Blood Pressure Estimation via Pulse Wave Analysis
Apr 23, 2023



The use of observed wearable sensor data (e.g., photoplethysmograms [PPG]) to infer health measures (e.g., glucose level or blood pressure) is a very active area of research. Such technology can have a significant impact on health screening, chronic disease management and remote monitoring. A common approach is to collect sensor data and corresponding labels from a clinical grade device (e.g., blood pressure cuff), and train deep learning models to map one to the other. Although well intentioned, this approach often ignores a principled analysis of whether the input sensor data has enough information to predict the desired metric. We analyze the task of predicting blood pressure from PPG pulse wave analysis. Our review of the prior work reveals that many papers fall prey data leakage, and unrealistic constraints on the task and the preprocessing steps. We propose a set of tools to help determine if the input signal in question (e.g., PPG) is indeed a good predictor of the desired label (e.g., blood pressure). Using our proposed tools, we have found that blood pressure prediction using PPG has a high multi-valued mapping factor of 33.2% and low mutual information of 9.8%. In comparison, heart rate prediction using PPG, a well-established task, has a very low multi-valued mapping factor of 0.75% and high mutual information of 87.7%. We argue that these results provide a more realistic representation of the current progress towards to goal of wearable blood pressure measurement via PPG pulse wave analysis.
Towards Automating Retinoscopy for Refractive Error Diagnosis
Aug 10, 2022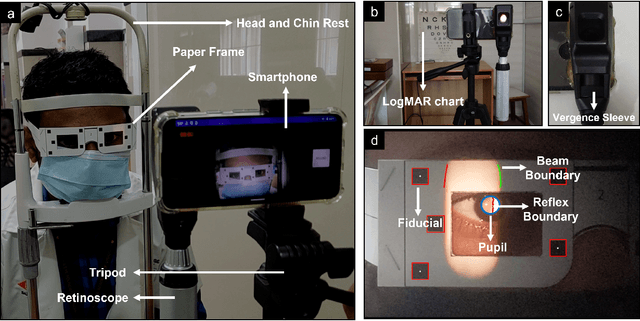
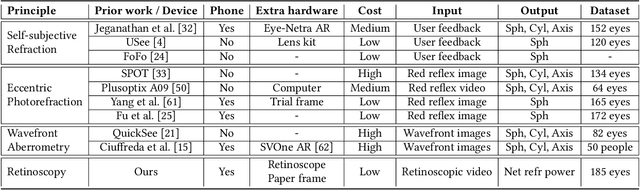
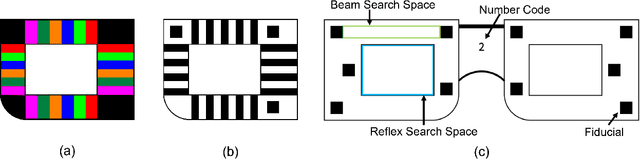

Refractive error is the most common eye disorder and is the key cause behind correctable visual impairment, responsible for nearly 80% of the visual impairment in the US. Refractive error can be diagnosed using multiple methods, including subjective refraction, retinoscopy, and autorefractors. Although subjective refraction is the gold standard, it requires cooperation from the patient and hence is not suitable for infants, young children, and developmentally delayed adults. Retinoscopy is an objective refraction method that does not require any input from the patient. However, retinoscopy requires a lens kit and a trained examiner, which limits its use for mass screening. In this work, we automate retinoscopy by attaching a smartphone to a retinoscope and recording retinoscopic videos with the patient wearing a custom pair of paper frames. We develop a video processing pipeline that takes retinoscopic videos as input and estimates the net refractive error based on our proposed extension of the retinoscopy mathematical model. Our system alleviates the need for a lens kit and can be performed by an untrained examiner. In a clinical trial with 185 eyes, we achieved a sensitivity of 91.0% and specificity of 74.0% on refractive error diagnosis. Moreover, the mean absolute error of our approach was 0.75$\pm$0.67D on net refractive error estimation compared to subjective refraction measurements. Our results indicate that our approach has the potential to be used as a retinoscopy-based refractive error screening tool in real-world medical settings.