 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVE: Distribution-aware Attribution via ViT Gradient Decomposition
Feb 06, 2026Vision Transformers (ViTs) have become a dominant architecture in computer vision, yet producing stable and high-resolution attribution maps for these models remains challenging. Architectural components such as patch embeddings and attention routing often introduce structured artifacts in pixel-level explanations, causing many existing methods to rely on coarse patch-level attributions. We introduce DAVE \textit{(\underline{D}istribution-aware \underline{A}ttribution via \underline{V}iT Gradient D\underline{E}composition)}, a mathematically grounded attribution method for ViTs based on a structured decomposition of the input gradient. By exploiting architectural properties of ViTs, DAVE isolates locally equivariant and stable components of the effective input--output mapping. It separates these from architecture-induced artifacts and other sources of instability.
Towards Automating Retinoscopy for Refractive Error Diagnosis
Aug 10, 2022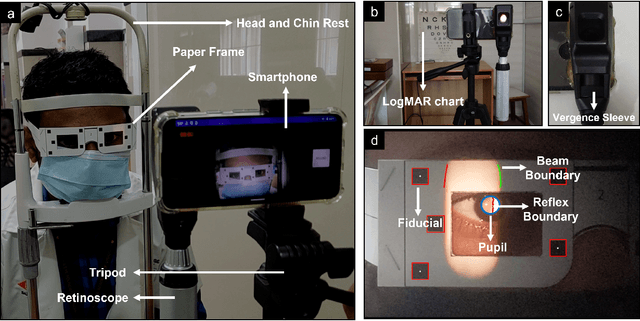
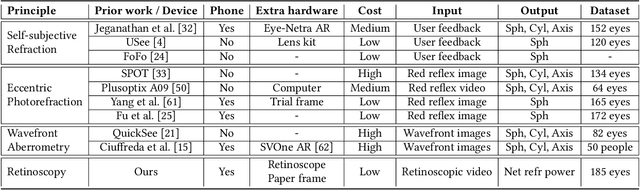
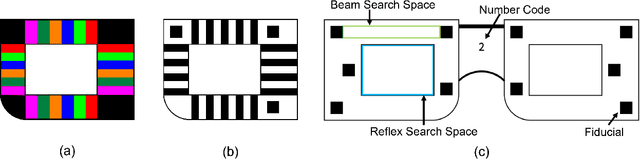

Refractive error is the most common eye disorder and is the key cause behind correctable visual impairment, responsible for nearly 80% of the visual impairment in the US. Refractive error can be diagnosed using multiple methods, including subjective refraction, retinoscopy, and autorefractors. Although subjective refraction is the gold standard, it requires cooperation from the patient and hence is not suitable for infants, young children, and developmentally delayed adults. Retinoscopy is an objective refraction method that does not require any input from the patient. However, retinoscopy requires a lens kit and a trained examiner, which limits its use for mass screening. In this work, we automate retinoscopy by attaching a smartphone to a retinoscope and recording retinoscopic videos with the patient wearing a custom pair of paper frames. We develop a video processing pipeline that takes retinoscopic videos as input and estimates the net refractive error based on our proposed extension of the retinoscopy mathematical model. Our system alleviates the need for a lens kit and can be performed by an untrained examiner. In a clinical trial with 185 eyes, we achieved a sensitivity of 91.0% and specificity of 74.0% on refractive error diagnosis. Moreover, the mean absolute error of our approach was 0.75$\pm$0.67D on net refractive error estimation compared to subjective refraction measurements. Our results indicate that our approach has the potential to be used as a retinoscopy-based refractive error screening tool in real-world medical settings.
Keratoconus Classifier for Smartphone-based Corneal Topographer
May 07, 2022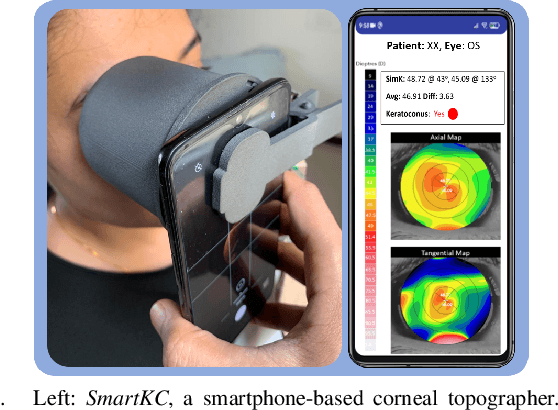
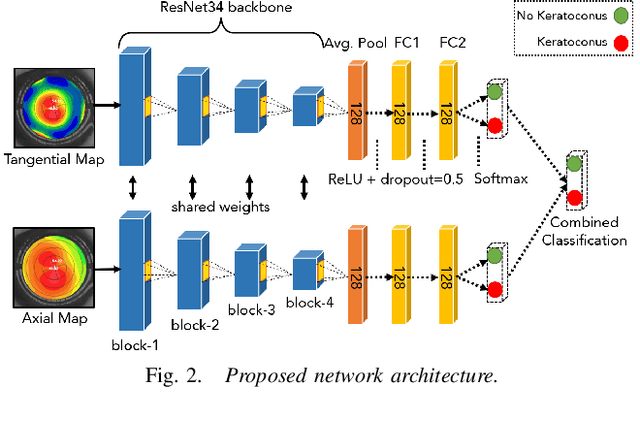
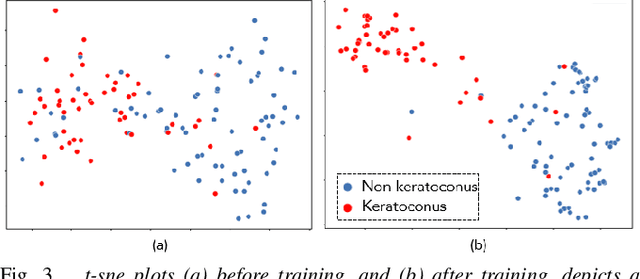
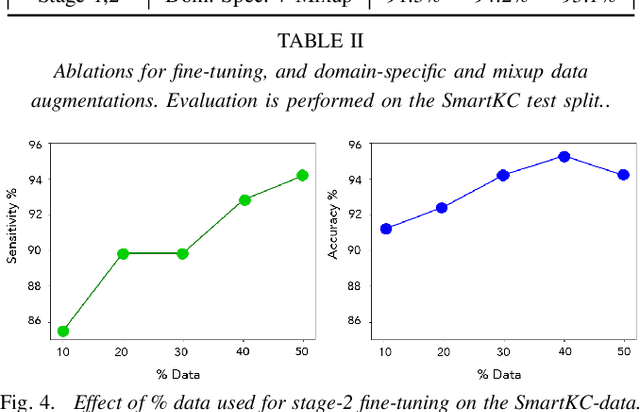
Keratoconus is a severe eye disease that leads to deformation of the cornea. It impacts people aged 10-25 years and is the leading cause of blindness in that demography. Corneal topography is the gold standard for keratoconus diagnosis. It is a non-invasive process performed using expensive and bulky medical devices called corneal topographers. This makes it inaccessible to large populations, especially in the Global South. Low-cost smartphone-based corneal topographers, such as SmartKC, have been proposed to make keratoconus diagnosis accessible. Similar to medical-grade topographers, SmartKC outputs curvature heatmaps and quantitative metrics that need to be evaluated by doctors for keratoconus diagnosis. An automatic scheme for evaluation of these heatmaps and quantitative values can play a crucial role in screening keratoconus in areas where doctors are not available. In this work, we propose a dual-head convolutional neural network (CNN) for classifying keratoconus on the heatmaps generated by SmartKC. Since SmartKC is a new device and only had a small dataset (114 samples), we developed a 2-stage transfer learning strategy -- using historical data collected from a medical-grade topographer and a subset of SmartKC data -- to satisfactorily train our network. This, combined with our domain-specific data augmentations, achieved a sensitivity of 91.3% and a specificity of 94.2%.
RespireNet: A Deep Neural Network for Accurately Detecting Abnormal Lung Sounds in Limited Data Setting
Oct 31, 2020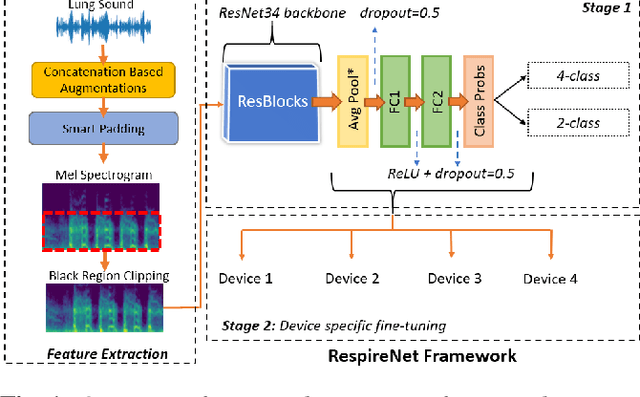
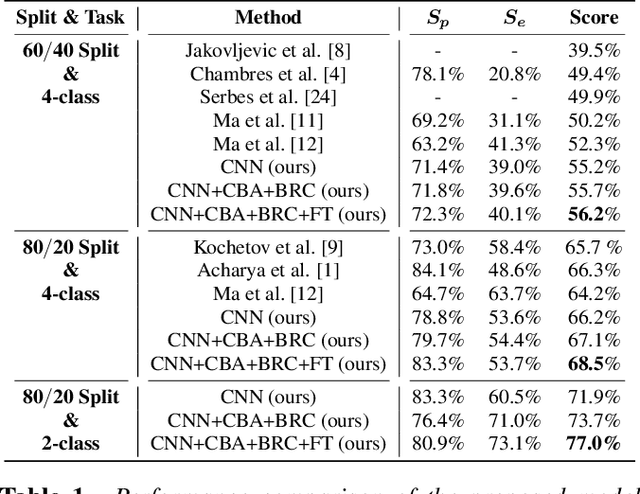


Auscultation of respiratory sounds is the primary tool for screening and diagnosing lung diseases. Automated analysis, coupled with digital stethoscopes, can play a crucial role in enabling tele-screening of fatal lung diseases. Deep neural networks (DNNs) have shown a lot of promise for such problems, and are an obvious choice. However, DNNs are extremely data hungry, and the largest respiratory dataset ICBHI has only 6898 breathing cycles, which is still small for training a satisfactory DNN model. In this work, RespireNet, we propose a simple CNN-based model, along with a suite of novel techniques---device specific fine-tuning, concatenation-based augmentation, blank region clipping, and smart padding---enabling us to efficiently use the small-sized dataset. We perform extensive evaluation on the ICBHI dataset, and improve upon the state-of-the-art results for 4-class classification by 2.2%
SimPropNet: Improved Similarity Propagation for Few-shot Image Segmentation
May 02, 2020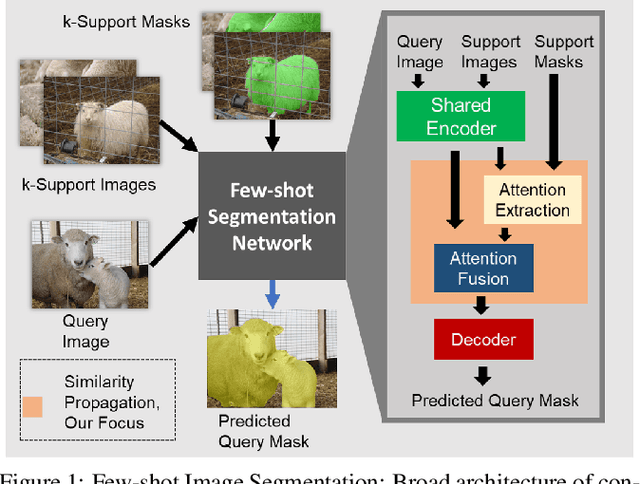

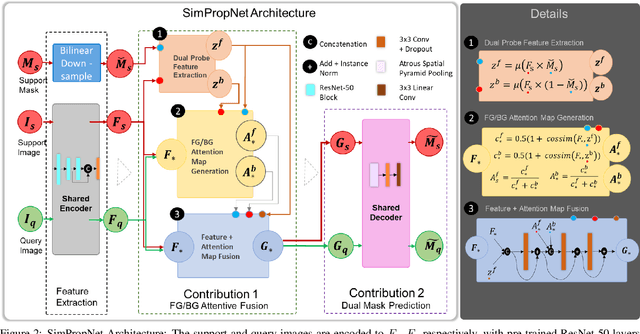
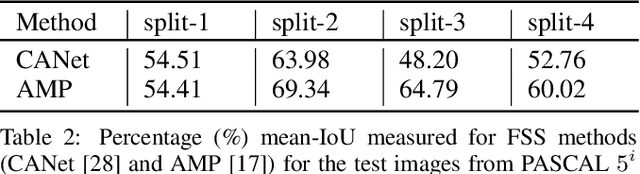
Few-shot segmentation (FSS) methods perform image segmentation for a particular object class in a target (query) image, using a small set of (support) image-mask pairs. Recent deep neural network based FSS methods leverage high-dimensional feature similarity between the foreground features of the support images and the query image features. In this work, we demonstrate gaps in the utilization of this similarity information in existing methods, and present a framework - SimPropNet, to bridge those gaps. We propose to jointly predict the support and query masks to force the support features to share characteristics with the query features. We also propose to utilize similarities in the background regions of the query and support images using a novel foreground-background attentive fusion mechanism. Our method achieves state-of-the-art results for one-shot and five-shot segmentation on the PASCAL-5i dataset. The paper includes detailed analysis and ablation studies for the proposed improvements and quantitative comparisons with contemporary methods.
Identifying Clickbait: A Multi-Strategy Approach Using Neural Networks
Aug 01, 2018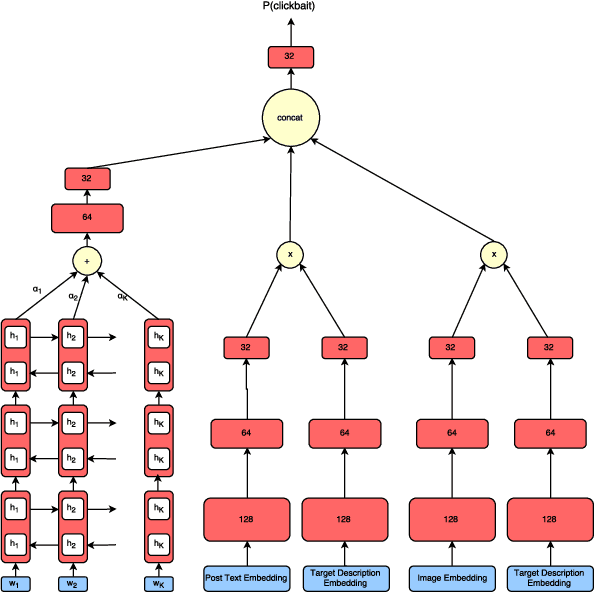
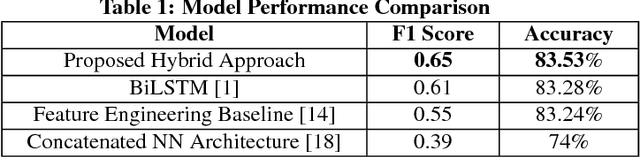
Online media outlets, in a bid to expand their reach and subsequently increase revenue through ad monetisation, have begun adopting clickbait techniques to lure readers to click on articles. The article fails to fulfill the promise made by the headline. Traditional methods for clickbait detection have relied heavily on feature engineering which, in turn, is dependent on the dataset it is built for. The application of neural networks for this task has only been explored partially. We propose a novel approach considering all information found in a social media post. We train a bidirectional LSTM with an attention mechanism to learn the extent to which a word contributes to the post's clickbait score in a differential manner. We also employ a Siamese net to capture the similarity between source and target information. Information gleaned from images has not been considered in previous approaches. We learn image embeddings from large amounts of data using Convolutional Neural Networks to add another layer of complexity to our model. Finally, we concatenate the outputs from the three separate components, serving it as input to a fully connected layer. We conduct experiments over a test corpus of 19538 social media posts, attaining an F1 score of 65.37% on the dataset bettering the previous state-of-the-art, as well as other proposed approaches, feature engineering or otherwise.
* Accepted at SIGIR 2018 as Short Paper