 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommitDistill: A Lightweight Knowledge-Centric Memory Layer for Software Repositories
May 18, 2026Software repositories accumulate large amounts of unstructured knowledge in commit messages, pull-request discussions, and issue threads, but developers and AI coding assistants rarely reuse this history effectively. Recent work on typed-memory architectures for LLM agents (MemGPT, generative agents, and the PlugMem module of Yang et al.) argues that agent memory should be distilled, typed knowledge rather than raw interaction text. We adapt that stance to a software repository's own git history under a constrained regime: deterministic, dependency-free, local-only, no embeddings. We present CommitDistill, an open-source Python prototype that mines a local git history into typed knowledge units (Facts, Skills, Patterns) using deterministic regex and surfaces them through a TF-IDF retriever with a calibrated silence threshold (theta = 2.5) that abstains on out-of-distribution queries. The artefact is a trust-instrumented memory substrate: deterministic, no external service, inspectable plain-JSON store, tunable abstention. A case study on five public repositories spanning Python, JavaScript, C, and Java (25,000 commits, 1,167 extracted units) reports useful-precision 0.525 at Cohen's kappa = 0.633 on 40 dual-annotated Python units. The decisive finding is budget-constrained retrieval: at a 256-character per-query budget, CommitDistill reaches 0.750 hit-rate on a 12-query benchmark against BM25's 0.333 and git log --grep's 0.083. On a four-arm paired LLM-as-judge evaluation (n=200 time-travel bug-fixes, two judges) covering control, CommitDistill, a body-budget-matched CD-Hybrid, and BM25, no condition produces a statistically detectable lift over control on the headline mean and CD-Hybrid is indistinguishable from BM25 head-to-head. Extraction over 10,000 commits completes in under 4 seconds on a laptop. Source, annotations, baselines, and a reproducibility script accompany this paper.
MORPHOGEN: A Multilingual Benchmark for Evaluating Gender-Aware Morphological Generation
Apr 20, 2026While multilingual large language models (LLMs) perform well on high-level tasks like translation and question answering, their ability to handle grammatical gender and morphological agreement remains underexplored. In morphologically rich languages, gender influences verb conjugation, pronouns, and even first-person constructions with explicit and implicit mentions of gender. We introduce MORPHOGEN, a morphologically grounded large-scale benchmark dataset for evaluating gender-aware generation in three typologically diverse grammatically gendered languages: French, Arabic, and Hindi. The core task, GENFORM, requires models to rewrite a first-person sentence in the opposite gender while preserving its meaning and structure. We construct a high-quality synthetic dataset spanning these three languages and benchmark 15 popular multilingual LLMs (2B-70B) on their ability to perform this transformation. Our results reveal significant gaps and interesting insights into how current models handle morphological gender. MORPHOGEN provides a focused diagnostic lens for gender-aware language modeling and lays the groundwork for future research on inclusive and morphology-sensitive NLP.
Household navigation and manipulation for everyday object rearrangement tasks
Dec 11, 2023



We consider the problem of building an assistive robotic system that can help humans in daily household cleanup tasks. Creating such an autonomous system in real-world environments is inherently quite challenging, as a general solution may not suit the preferences of a particular customer. Moreover, such a system consists of multi-objective tasks comprising -- (i) Detection of misplaced objects and prediction of their potentially correct placements, (ii) Fine-grained manipulation for stable object grasping, and (iii) Room-to-room navigation for transferring objects in unseen environments. This work systematically tackles each component and integrates them into a complete object rearrangement pipeline. To validate our proposed system, we conduct multiple experiments on a real robotic platform involving multi-room object transfer, user preference-based placement, and complex pick-and-place tasks. Project page: https://sites.google.com/eng.ucsd.edu/home-robot
Towards Automating Retinoscopy for Refractive Error Diagnosis
Aug 10, 2022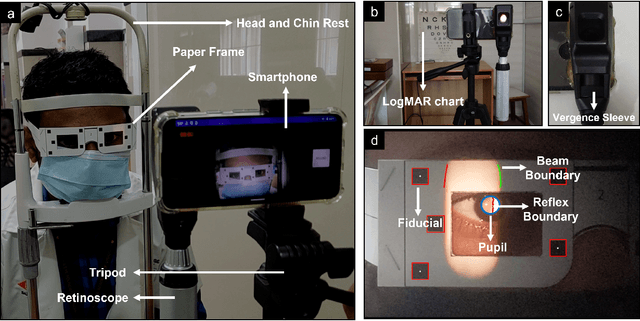
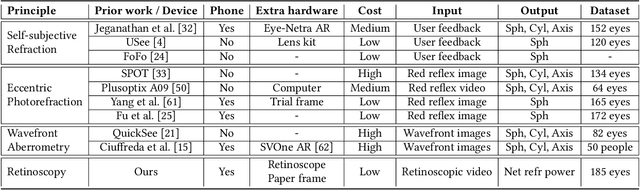
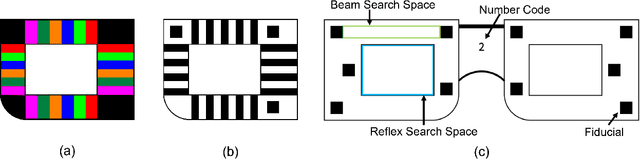

Refractive error is the most common eye disorder and is the key cause behind correctable visual impairment, responsible for nearly 80% of the visual impairment in the US. Refractive error can be diagnosed using multiple methods, including subjective refraction, retinoscopy, and autorefractors. Although subjective refraction is the gold standard, it requires cooperation from the patient and hence is not suitable for infants, young children, and developmentally delayed adults. Retinoscopy is an objective refraction method that does not require any input from the patient. However, retinoscopy requires a lens kit and a trained examiner, which limits its use for mass screening. In this work, we automate retinoscopy by attaching a smartphone to a retinoscope and recording retinoscopic videos with the patient wearing a custom pair of paper frames. We develop a video processing pipeline that takes retinoscopic videos as input and estimates the net refractive error based on our proposed extension of the retinoscopy mathematical model. Our system alleviates the need for a lens kit and can be performed by an untrained examiner. In a clinical trial with 185 eyes, we achieved a sensitivity of 91.0% and specificity of 74.0% on refractive error diagnosis. Moreover, the mean absolute error of our approach was 0.75$\pm$0.67D on net refractive error estimation compared to subjective refraction measurements. Our results indicate that our approach has the potential to be used as a retinoscopy-based refractive error screening tool in real-world medical settings.
Quo Vadis, Skeleton Action Recognition ?
Jul 04, 2020
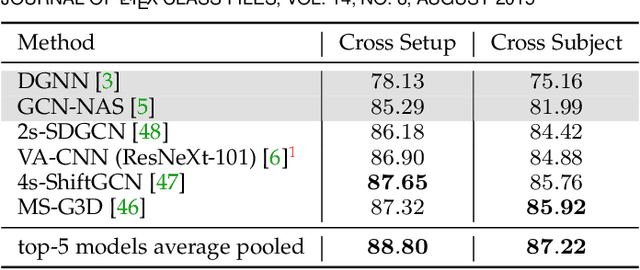
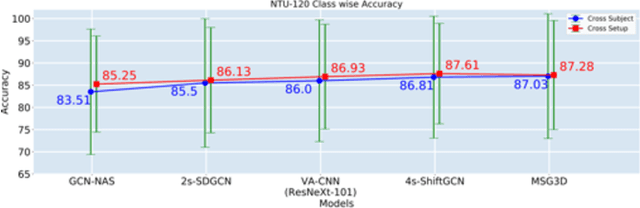
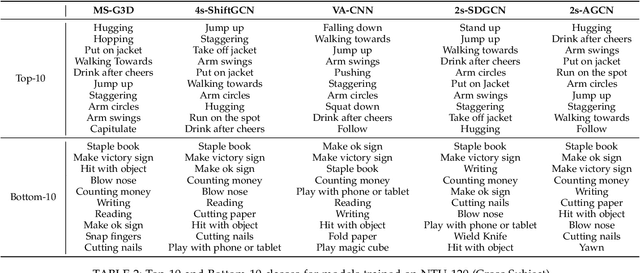
In this paper, we study current and upcoming frontiers across the landscape of skeleton-based human action recognition. To begin with, we benchmark state-of-the-art models on the NTU-120 dataset and provide multi-layered assessment of the results. To examine skeleton action recognition 'in the wild', we introduce Skeletics-152, a curated and 3-D pose-annotated subset of RGB videos sourced from Kinetics-700, a large-scale action dataset. The results from benchmarking the top performers of NTU-120 on Skeletics-152 reveal the challenges and domain gap induced by actions 'in the wild'. We extend our study to include out-of-context actions by introducing Skeleton-Mimetics, a dataset derived from the recently introduced Mimetics dataset. Finally, as a new frontier for action recognition, we introduce Metaphorics, a dataset with caption-style annotated YouTube videos of the popular social game Dumb Charades and interpretative dance performances. Overall, our work characterizes the strengths and limitations of existing approaches and datasets. It also provides an assessment of top-performing approaches across a spectrum of activity settings and via the introduced datasets, proposes new frontiers for human action recognition.
Reconstruct, Rasterize and Backprop: Dense shape and pose estimation from a single image
Apr 25, 2020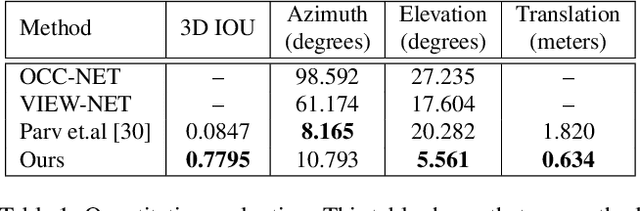

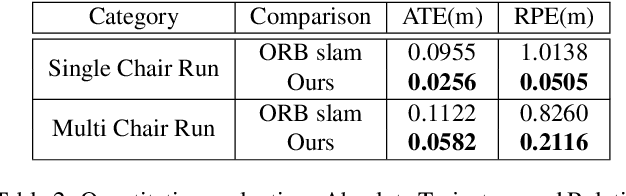

This paper presents a new system to obtain dense object reconstructions along with 6-DoF poses from a single image. Geared towards high fidelity reconstruction, several recent approaches leverage implicit surface representations and deep neural networks to estimate a 3D mesh of an object, given a single image. However, all such approaches recover only the shape of an object; the reconstruction is often in a canonical frame, unsuitable for downstream robotics tasks. To this end, we leverage recent advances in differentiable rendering (in particular, rasterization) to close the loop with 3D reconstruction in camera frame. We demonstrate that our approach---dubbed reconstruct, rasterize and backprop (RRB) achieves significantly lower pose estimation errors compared to prior art, and is able to recover dense object shapes and poses from imagery. We further extend our results to an (offline) setup, where we demonstrate a dense monocular object-centric egomotion estimation system.