 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-step Entity-centric Information Retrieval for Multi-Hop Question Answering
Sep 17, 2019
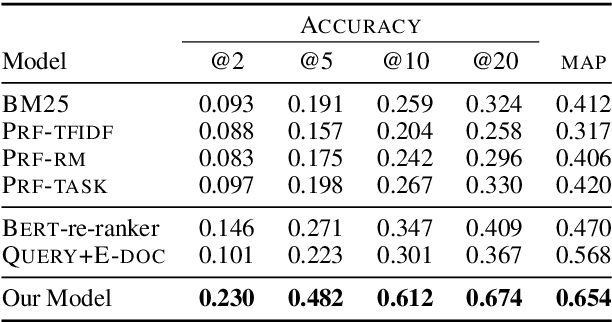
Multi-hop question answering (QA) requires an information retrieval (IR) system that can find \emph{multiple} supporting evidence needed to answer the question, making the retrieval process very challenging. This paper introduces an IR technique that uses information of entities present in the initially retrieved evidence to learn to `\emph{hop}' to other relevant evidence. In a setting, with more than \textbf{5 million} Wikipedia paragraphs, our approach leads to significant boost in retrieval performance. The retrieved evidence also increased the performance of an existing QA model (without any training) on the \hotpot benchmark by \textbf{10.59} F1.
Simple yet Effective Bridge Reasoning for Open-Domain Multi-Hop Question Answering
Sep 17, 2019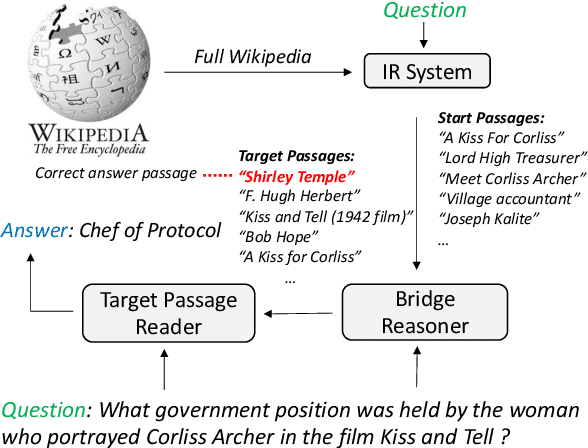

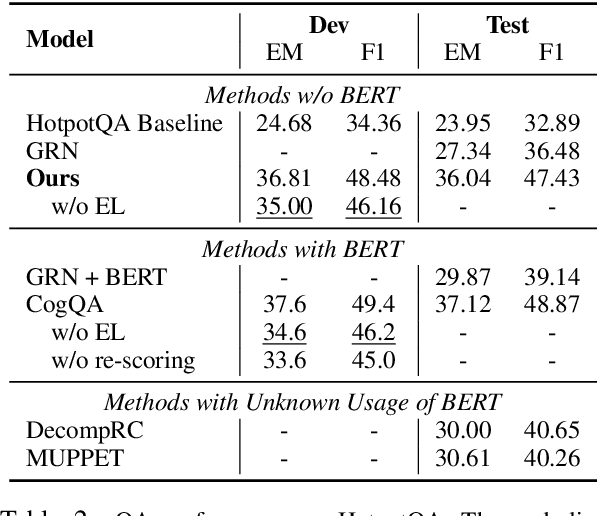
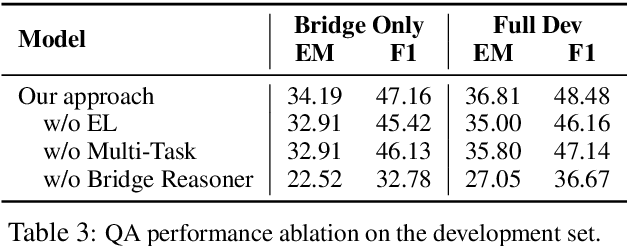
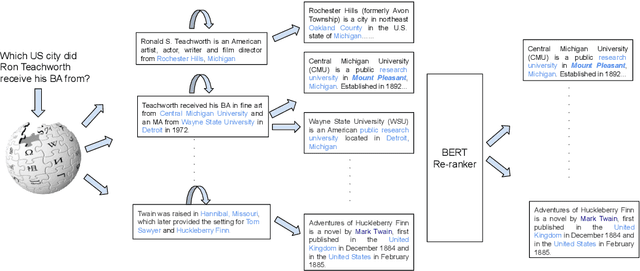
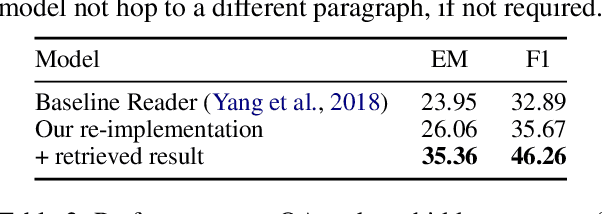
A key challenge of multi-hop question answering (QA) in the open-domain setting is to accurately retrieve the supporting passages from a large corpus. Existing work on open-domain QA typically relies on off-the-shelf information retrieval (IR) techniques to retrieve \textbf{answer passages}, i.e., the passages containing the groundtruth answers. However, IR-based approaches are insufficient for multi-hop questions, as the topic of the second or further hops is not explicitly covered by the question. To resolve this issue, we introduce a new sub-problem of open-domain multi-hop QA, which aims to recognize the bridge (\emph{i.e.}, the anchor that links to the answer passage) from the context of a set of start passages with a reading comprehension model. This model, the \textbf{bridge reasoner}, is trained with a weakly supervised signal and produces the candidate answer passages for the \textbf{passage reader} to extract the answer. On the full-wiki HotpotQA benchmark, we significantly improve the baseline method by 14 point F1. Without using any memory-inefficient contextual embeddings, our result is also competitive with the state-of-the-art that applies BERT in multiple modules.
Towards Open-Domain Named Entity Recognition via Neural Correction Models
Sep 13, 2019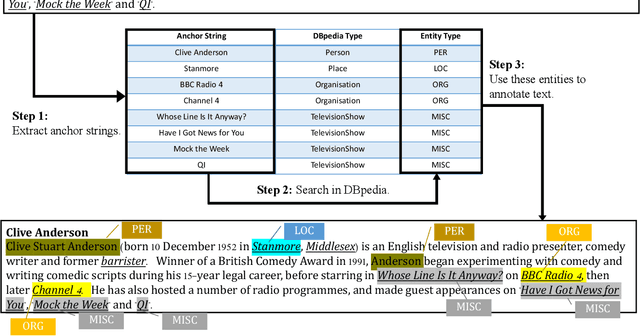
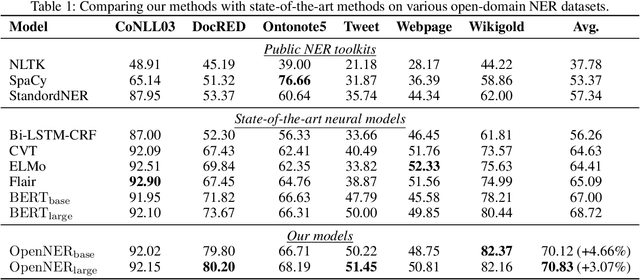
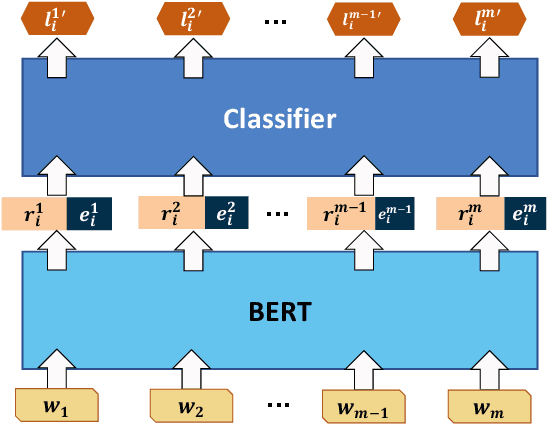
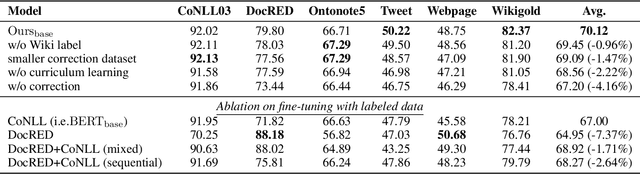
Named Entity Recognition (NER) plays an important role in a wide range of natural language processing tasks, such as relation extraction, question answering, etc. However, previous studies on NER are limited to a particular genre, using small manually-annotated or large but low-quality datasets. In this work, we propose a semi-supervised annotation framework to make full use of abstracts from Wikipedia and obtain a large and high-quality dataset called AnchorNER. We assume anchored strings in abstracts are named entities and annotate them with entity types mentioned in DBpedia. To improve the coverage, we design a neural correction model trained with a human-annotated NER dataset, DocRED, to correct the false-negative entity labels, and then train a BERT model with the corrected dataset. We evaluate our trained model on six NER datasets and our experimental results show that we have obtained state-of-the-art open-domain performances --- on top of the strong baselines BERT-base and BERT-large, we achieve relative improvements of 4.66% and 3.07% respectively.
Out-of-Domain Detection for Low-Resource Text Classification Tasks
Aug 31, 2019
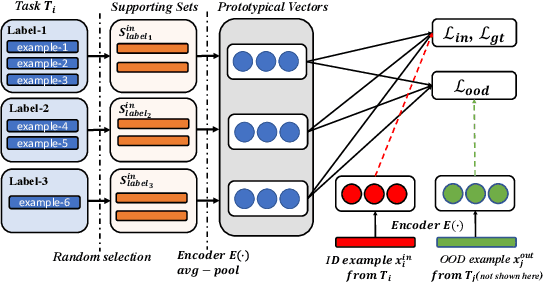
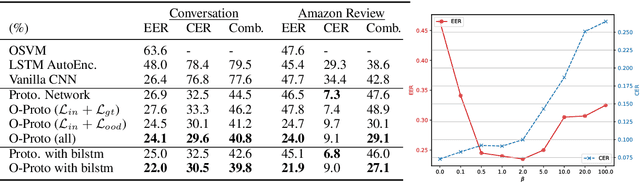
Out-of-domain (OOD) detection for low-resource text classification is a realistic but understudied task. The goal is to detect the OOD cases with limited in-domain (ID) training data, since we observe that training data is often insufficient in machine learning applications. In this work, we propose an OOD-resistant Prototypical Network to tackle this zero-shot OOD detection and few-shot ID classification task. Evaluation on real-world datasets show that the proposed solution outperforms state-of-the-art methods in zero-shot OOD detection task, while maintaining a competitive performance on ID classification task.
Meta Reasoning over Knowledge Graphs
Aug 13, 2019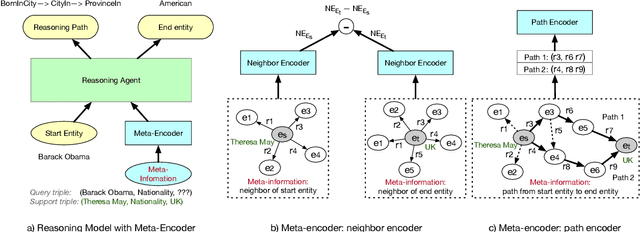
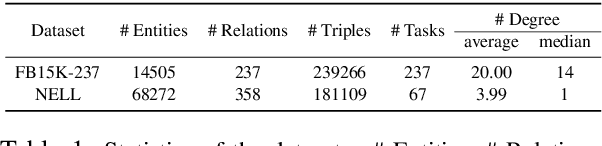
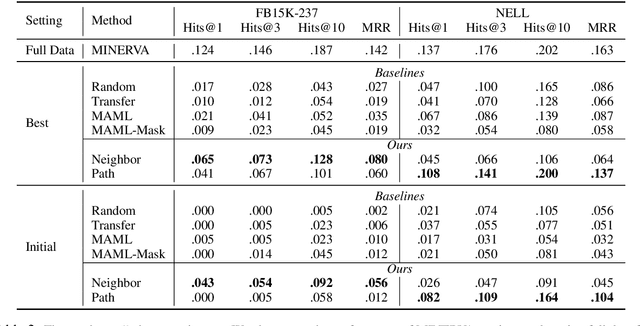
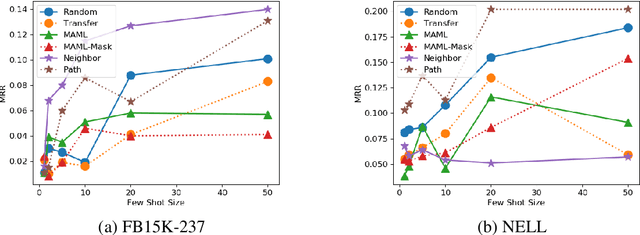
The ability to reason over learned knowledge is an innate ability for humans and humans can easily master new reasoning rules with only a few demonstrations. While most existing studies on knowledge graph (KG) reasoning assume enough training examples, we study the challenging and practical problem of few-shot knowledge graph reasoning under the paradigm of meta-learning. We propose a new meta learning framework that effectively utilizes the task-specific meta information such as local graph neighbors and reasoning paths in KGs. Specifically, we design a meta-encoder that encodes the meta information into task-specific initialization parameters for different tasks. This allows our reasoning module to have diverse starting points when learning to reason over different relations, which is expected to better fit the target task. On two few-shot knowledge base completion benchmarks, we show that the augmented task-specific meta-encoder yields much better initial point than MAML and outperforms several few-shot learning baselines.
Multi-Granular Text Encoding for Self-Explaining Categorization
Jul 19, 2019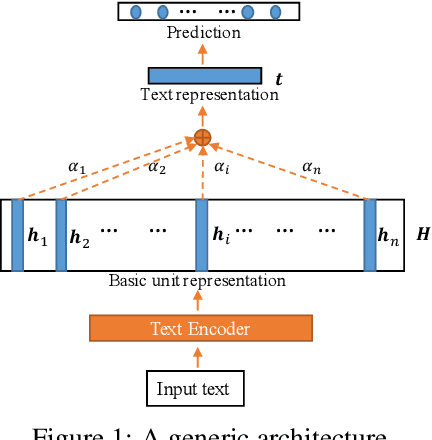
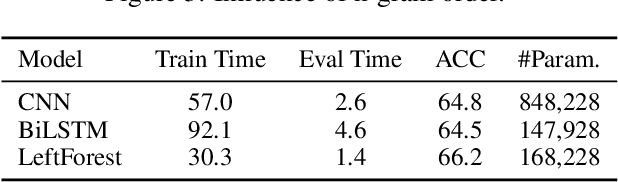
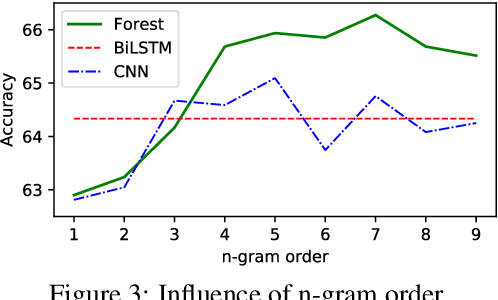
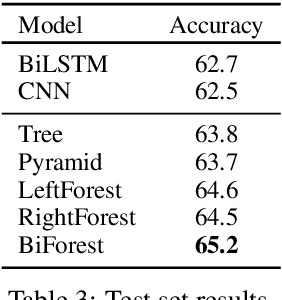
Self-explaining text categorization requires a classifier to make a prediction along with supporting evidence. A popular type of evidence is sub-sequences extracted from the input text which are sufficient for the classifier to make the prediction. In this work, we define multi-granular ngrams as basic units for explanation, and organize all ngrams into a hierarchical structure, so that shorter ngrams can be reused while computing longer ngrams. We leverage a tree-structured LSTM to learn a context-independent representation for each unit via parameter sharing. Experiments on medical disease classification show that our model is more accurate, efficient and compact than BiLSTM and CNN baselines. More importantly, our model can extract intuitive multi-granular evidence to support its predictions.
TWEETQA: A Social Media Focused Question Answering Dataset
Jul 14, 2019
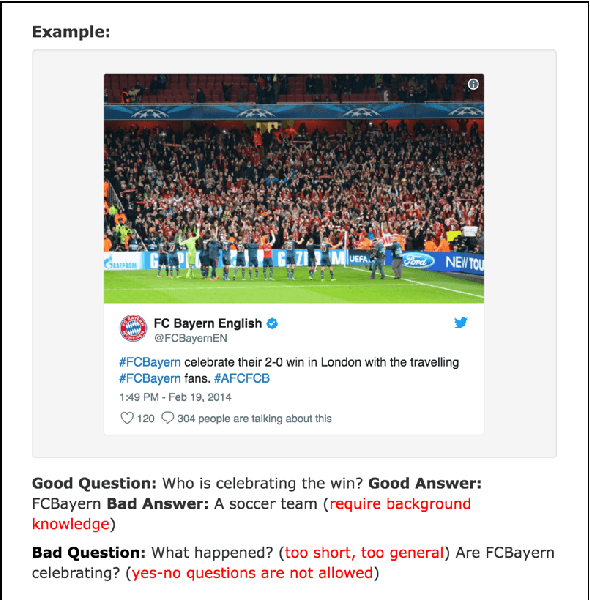
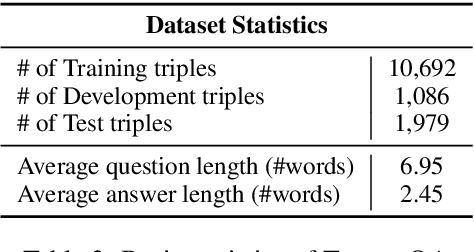

With social media becoming increasingly pop-ular on which lots of news and real-time eventsare reported, developing automated questionanswering systems is critical to the effective-ness of many applications that rely on real-time knowledge. While previous datasets haveconcentrated on question answering (QA) forformal text like news and Wikipedia, wepresent the first large-scale dataset for QA oversocial media data. To ensure that the tweetswe collected are useful, we only gather tweetsused by journalists to write news articles. Wethen ask human annotators to write questionsand answers upon these tweets. Unlike otherQA datasets like SQuAD in which the answersare extractive, we allow the answers to be ab-stractive. We show that two recently proposedneural models that perform well on formaltexts are limited in their performance when ap-plied to our dataset. In addition, even the fine-tuned BERT model is still lagging behind hu-man performance with a large margin. Our re-sults thus point to the need of improved QAsystems targeting social media text.
Self-Supervised Learning for Contextualized Extractive Summarization
Jun 11, 2019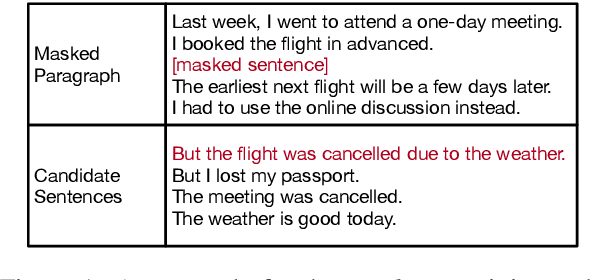
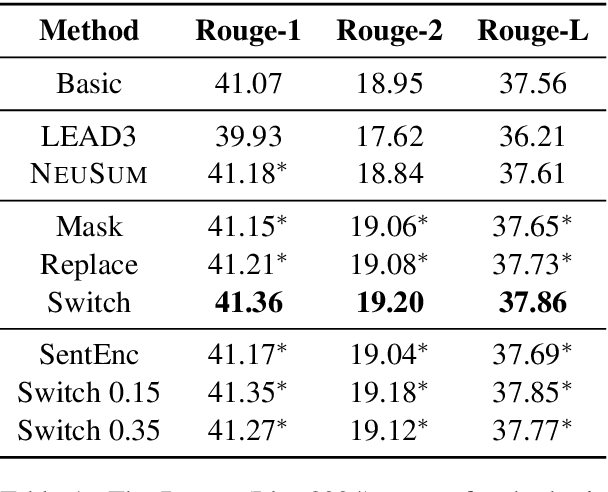
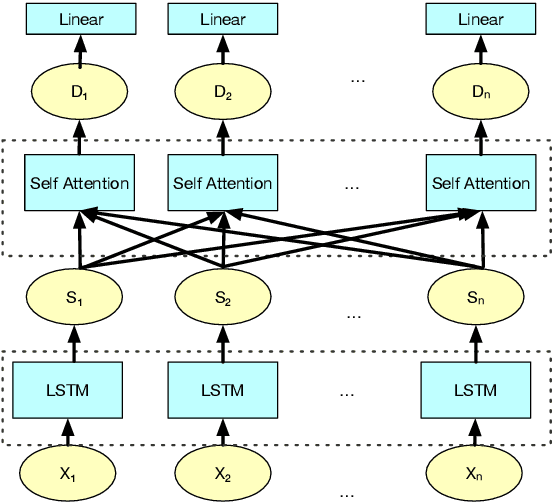
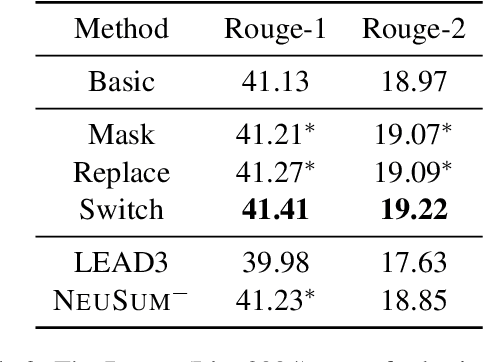
Existing models for extractive summarization are usually trained from scratch with a cross-entropy loss, which does not explicitly capture the global context at the document level. In this paper, we aim to improve this task by introducing three auxiliary pre-training tasks that learn to capture the document-level context in a self-supervised fashion. Experiments on the widely-used CNN/DM dataset validate the effectiveness of the proposed auxiliary tasks. Furthermore, we show that after pre-training, a clean model with simple building blocks is able to outperform previous state-of-the-art that are carefully designed.
Slack Channels Ecology in Enterprises: How Employees Collaborate Through Group Chat
Jun 04, 2019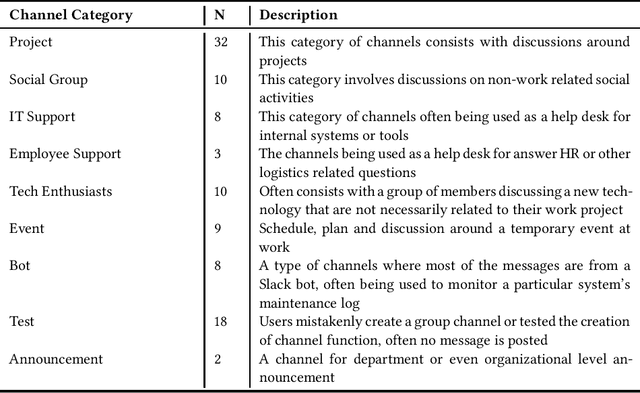
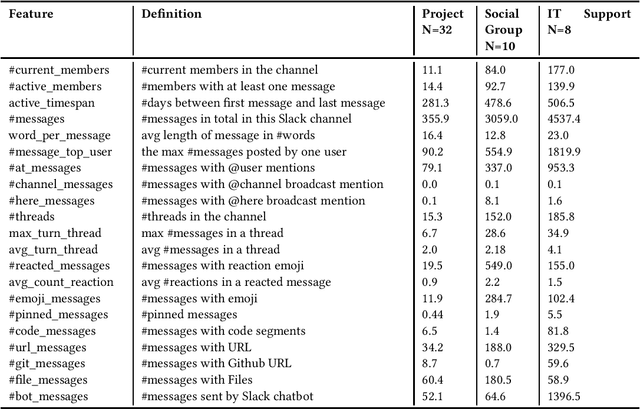
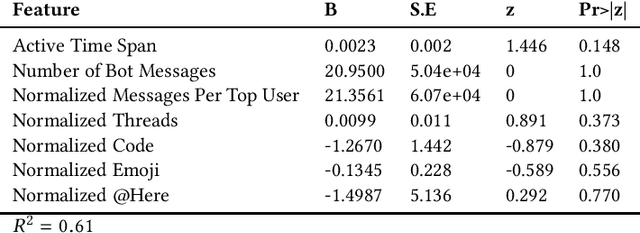
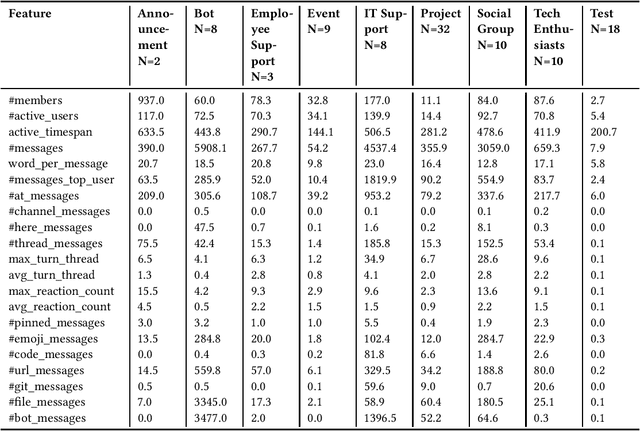
Despite the long history of studying instant messaging usage in organizations, we know very little about how today's people participate in group chat channels and interact with others. In this short note, we aim to update the existing knowledge on how group chat is used in the context of today's organizations. We have the privilege of collecting a total of 4300 publicly available group chat channels in Slack from an R\&D department in a multinational IT company. Through qualitative coding of 100 channels, we identified 9 channel categories such as project based channels and event channels. We further defined a feature metric with 21 features to depict the group communication style for these group chat channels, with which we successfully trained a machine learning model that can automatically classify a given group channel into one of the 9 categories. In addition, we illustrated how these communication metrics could be used for analyzing teams' collaboration activities. We focused on 117 project teams as we have their performance data, and further collected 54 out of the 117 teams' Slack group data and generated the communication style metrics for each of them. With these data, we are able to build a regression model to reveal the relationship between these group communication styles and one indicator of the project team performance.
Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader
May 31, 2019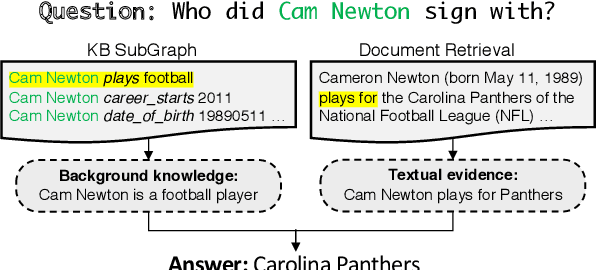
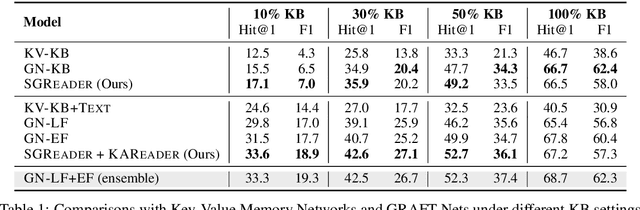
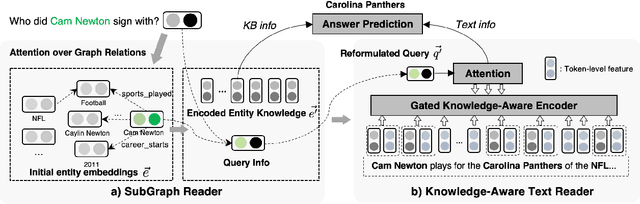

We propose a new end-to-end question answering model, which learns to aggregate answer evidence from an incomplete knowledge base (KB) and a set of retrieved text snippets. Under the assumptions that the structured KB is easier to query and the acquired knowledge can help the understanding of unstructured text, our model first accumulates knowledge of entities from a question-related KB subgraph; then reformulates the question in the latent space and reads the texts with the accumulated entity knowledge at hand. The evidence from KB and texts are finally aggregated to predict answers. On the widely-used KBQA benchmark WebQSP, our model achieves consistent improvements across settings with different extents of KB incompleteness.