 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Digital Forensics and Incident Response Pipeline Ready for Text-Based Threats in LLM Era?
Jul 25, 2024



In the era of generative AI, the widespread adoption of Neural Text Generators (NTGs) presents new cybersecurity challenges, particularly within the realms of Digital Forensics and Incident Response (DFIR). These challenges primarily involve the detection and attribution of sources behind advanced attacks like spearphishing and disinformation campaigns. As NTGs evolve, the task of distinguishing between human and NTG-authored texts becomes critically complex. This paper rigorously evaluates the DFIR pipeline tailored for text-based security systems, specifically focusing on the challenges of detecting and attributing authorship of NTG-authored texts. By introducing a novel human-NTG co-authorship text attack, termed CS-ACT, our study uncovers significant vulnerabilities in traditional DFIR methodologies, highlighting discrepancies between ideal scenarios and real-world conditions. Utilizing 14 diverse datasets and 43 unique NTGs, up to the latest GPT-4, our research identifies substantial vulnerabilities in the forensic profiling phase, particularly in attributing authorship to NTGs. Our comprehensive evaluation points to factors such as model sophistication and the lack of distinctive style within NTGs as significant contributors for these vulnerabilities. Our findings underscore the necessity for more sophisticated and adaptable strategies, such as incorporating adversarial learning, stylizing NTGs, and implementing hierarchical attribution through the mapping of NTG lineages to enhance source attribution. This sets the stage for future research and the development of more resilient text-based security systems.
A Neural Approach to Irony Generation
Sep 16, 2019
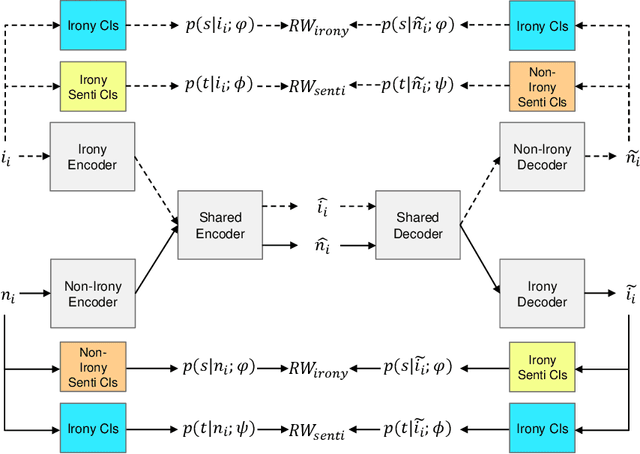
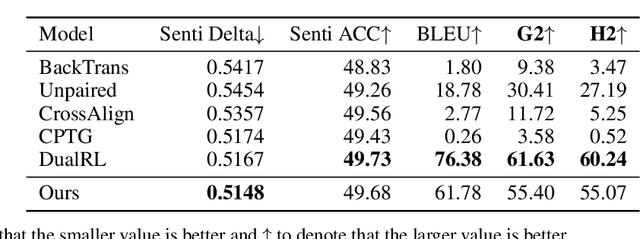
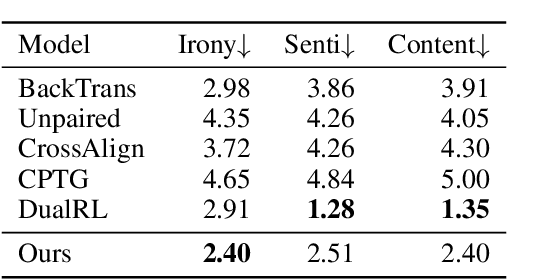
Ironies can not only express stronger emotions but also show a sense of humor. With the development of social media, ironies are widely used in public. Although many prior research studies have been conducted in irony detection, few studies focus on irony generation. The main challenges for irony generation are the lack of large-scale irony dataset and difficulties in modeling the ironic pattern. In this work, we first systematically define irony generation based on style transfer task. To address the lack of data, we make use of twitter and build a large-scale dataset. We also design a combination of rewards for reinforcement learning to control the generation of ironic sentences. Experimental results demonstrate the effectiveness of our model in terms of irony accuracy, sentiment preservation, and content preservation.
Towards Open-Domain Named Entity Recognition via Neural Correction Models
Sep 13, 2019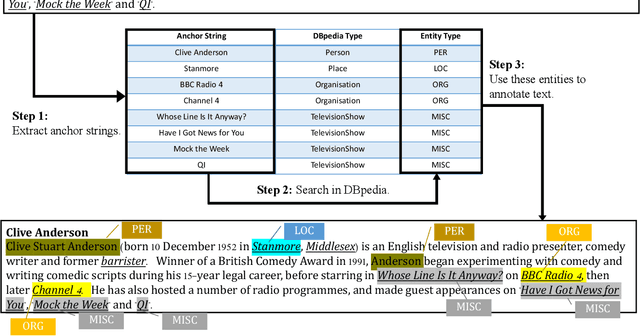
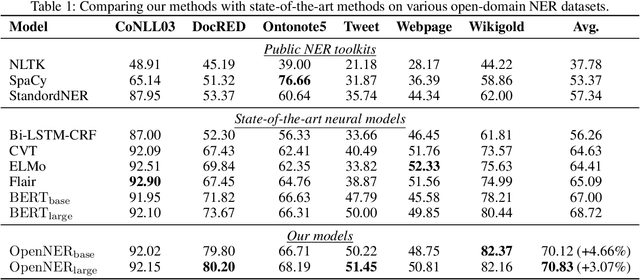
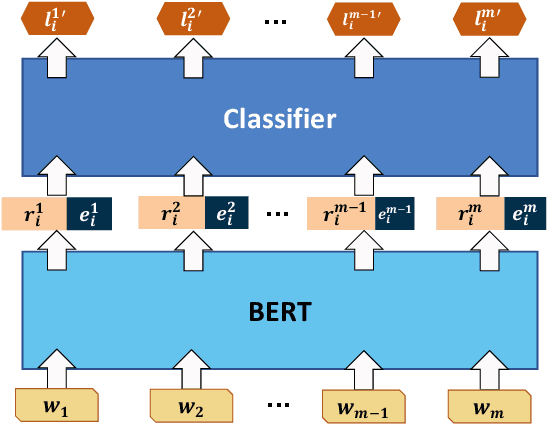
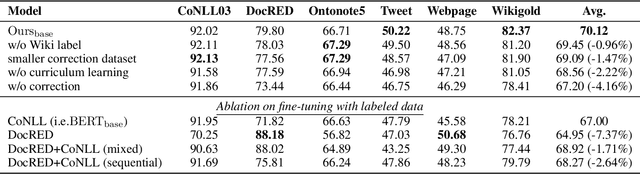
Named Entity Recognition (NER) plays an important role in a wide range of natural language processing tasks, such as relation extraction, question answering, etc. However, previous studies on NER are limited to a particular genre, using small manually-annotated or large but low-quality datasets. In this work, we propose a semi-supervised annotation framework to make full use of abstracts from Wikipedia and obtain a large and high-quality dataset called AnchorNER. We assume anchored strings in abstracts are named entities and annotate them with entity types mentioned in DBpedia. To improve the coverage, we design a neural correction model trained with a human-annotated NER dataset, DocRED, to correct the false-negative entity labels, and then train a BERT model with the corrected dataset. We evaluate our trained model on six NER datasets and our experimental results show that we have obtained state-of-the-art open-domain performances --- on top of the strong baselines BERT-base and BERT-large, we achieve relative improvements of 4.66% and 3.07% respectively.