 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQL-to-Text Generation with Graph-to-Sequence Model
Sep 14, 2018
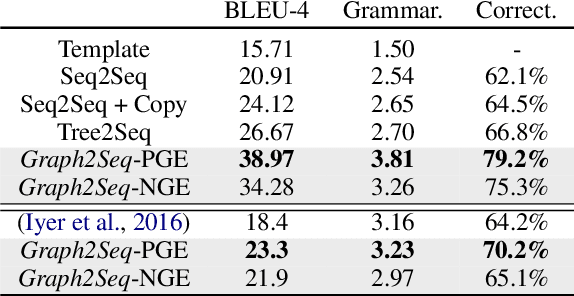
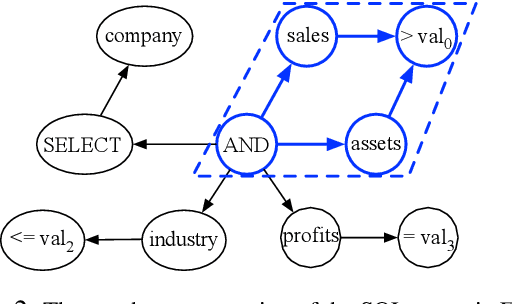

Previous work approaches the SQL-to-text generation task using vanilla Seq2Seq models, which may not fully capture the inherent graph-structured information in SQL query. In this paper, we first introduce a strategy to represent the SQL query as a directed graph and then employ a graph-to-sequence model to encode the global structure information into node embeddings. This model can effectively learn the correlation between the SQL query pattern and its interpretation. Experimental results on the WikiSQL dataset and Stackoverflow dataset show that our model significantly outperforms the Seq2Seq and Tree2Seq baselines, achieving the state-of-the-art performance.
Improving Reinforcement Learning Based Image Captioning with Natural Language Prior
Sep 13, 2018

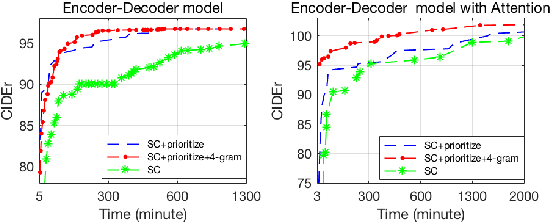
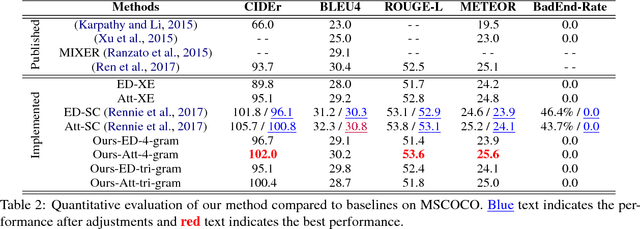
Recently, Reinforcement Learning (RL) approaches have demonstrated advanced performance in image captioning by directly optimizing the metric used for testing. However, this shaped reward introduces learning biases, which reduces the readability of generated text. In addition, the large sample space makes training unstable and slow. To alleviate these issues, we propose a simple coherent solution that constrains the action space using an n-gram language prior. Quantitative and qualitative evaluations on benchmarks show that RL with the simple add-on module performs favorably against its counterpart in terms of both readability and speed of convergence. Human evaluation results show that our model is more human readable and graceful. The implementation will become publicly available upon the acceptance of the paper.
Exploring Graph-structured Passage Representation for Multi-hop Reading Comprehension with Graph Neural Networks
Sep 06, 2018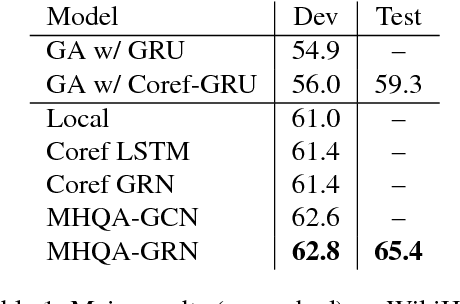
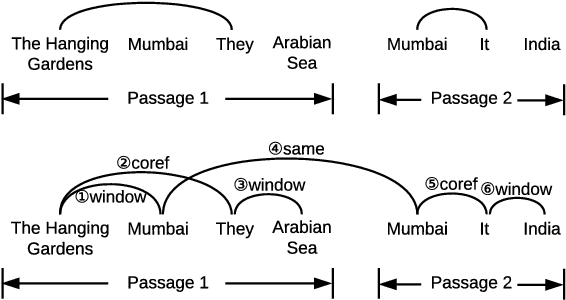
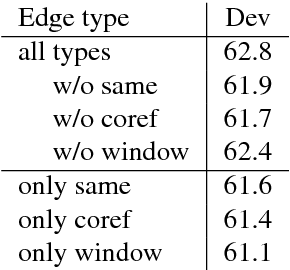
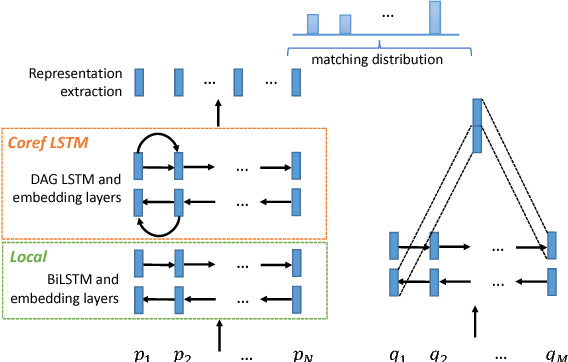
Multi-hop reading comprehension focuses on one type of factoid question, where a system needs to properly integrate multiple pieces of evidence to correctly answer a question. Previous work approximates global evidence with local coreference information, encoding coreference chains with DAG-styled GRU layers within a gated-attention reader. However, coreference is limited in providing information for rich inference. We introduce a new method for better connecting global evidence, which forms more complex graphs compared to DAGs. To perform evidence integration on our graphs, we investigate two recent graph neural networks, namely graph convolutional network (GCN) and graph recurrent network (GRN). Experiments on two standard datasets show that richer global information leads to better answers. Our method performs better than all published results on these datasets.
Deriving Machine Attention from Human Rationales
Aug 28, 2018
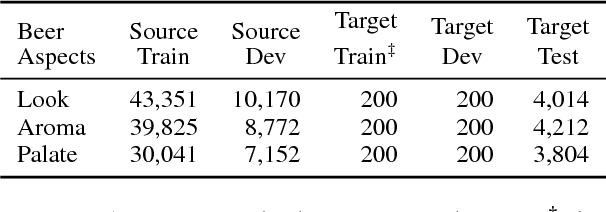
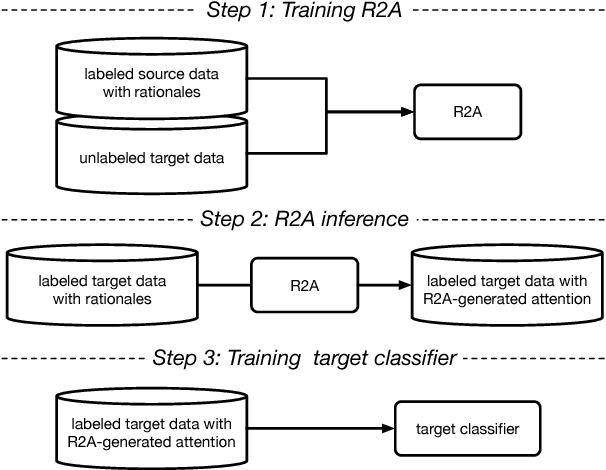
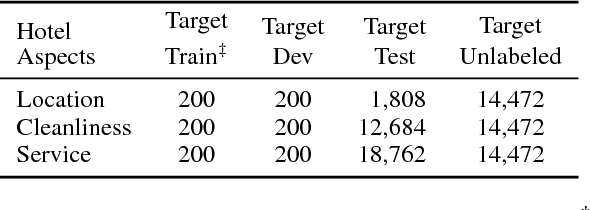
Attention-based models are successful when trained on large amounts of data. In this paper, we demonstrate that even in the low-resource scenario, attention can be learned effectively. To this end, we start with discrete human-annotated rationales and map them into continuous attention. Our central hypothesis is that this mapping is general across domains, and thus can be transferred from resource-rich domains to low-resource ones. Our model jointly learns a domain-invariant representation and induces the desired mapping between rationales and attention. Our empirical results validate this hypothesis and show that our approach delivers significant gains over state-of-the-art baselines, yielding over 15% average error reduction on benchmark datasets.
One-Shot Relational Learning for Knowledge Graphs
Aug 27, 2018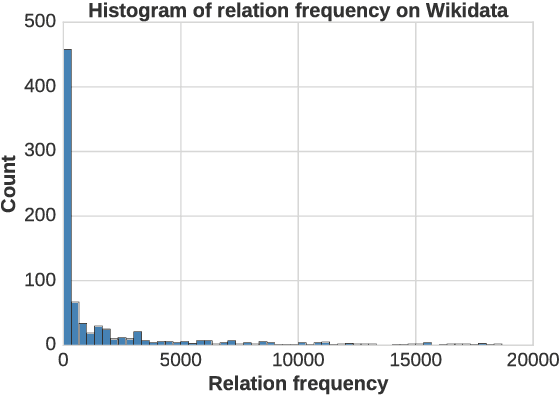
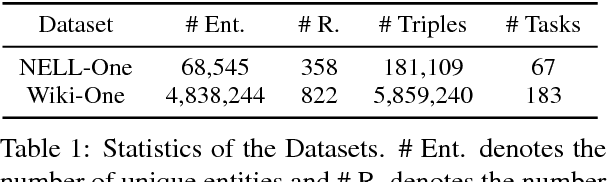
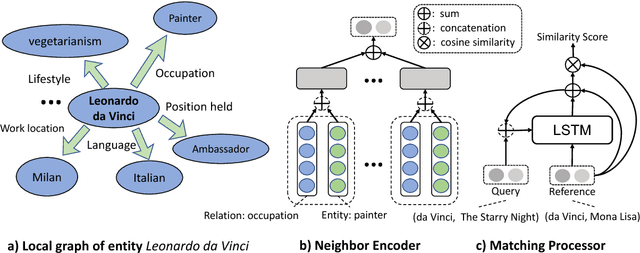
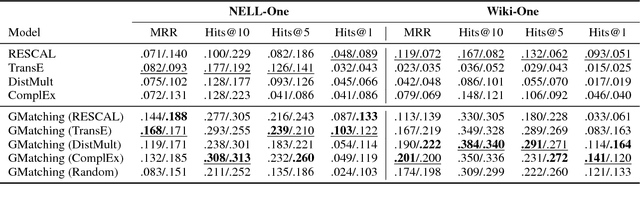
Knowledge graphs (KGs) are the key components of various natural language processing applications. To further expand KGs' coverage, previous studies on knowledge graph completion usually require a large number of training instances for each relation. However, we observe that long-tail relations are actually more common in KGs and those newly added relations often do not have many known triples for training. In this work, we aim at predicting new facts under a challenging setting where only one training instance is available. We propose a one-shot relational learning framework, which utilizes the knowledge extracted by embedding models and learns a matching metric by considering both the learned embeddings and one-hop graph structures. Empirically, our model yields considerable performance improvements over existing embedding models, and also eliminates the need of re-training the embedding models when dealing with newly added relations.
Exploiting Rich Syntactic Information for Semantic Parsing with Graph-to-Sequence Model
Aug 23, 2018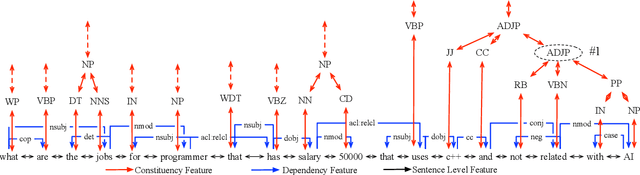
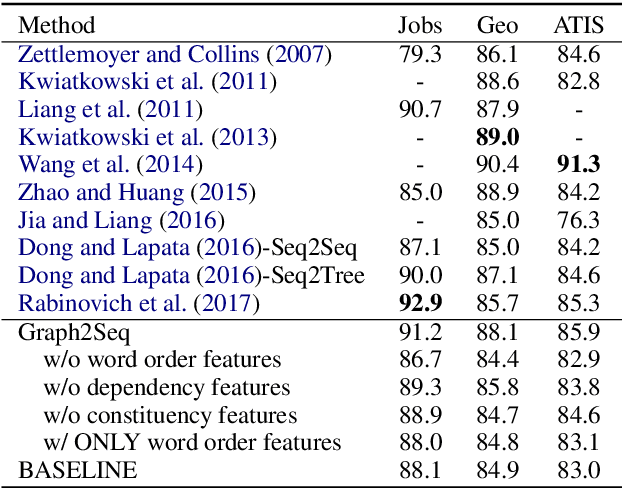

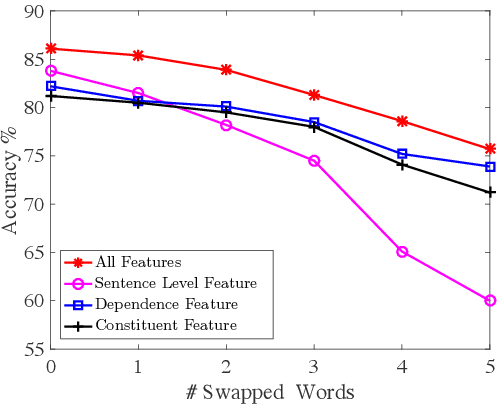
Existing neural semantic parsers mainly utilize a sequence encoder, i.e., a sequential LSTM, to extract word order features while neglecting other valuable syntactic information such as dependency graph or constituent trees. In this paper, we first propose to use the \textit{syntactic graph} to represent three types of syntactic information, i.e., word order, dependency and constituency features. We further employ a graph-to-sequence model to encode the syntactic graph and decode a logical form. Experimental results on benchmark datasets show that our model is comparable to the state-of-the-art on Jobs640, ATIS and Geo880. Experimental results on adversarial examples demonstrate the robustness of the model is also improved by encoding more syntactic information.
Spatial-Temporal Synergic Residual Learning for Video Person Re-Identification
Jul 16, 2018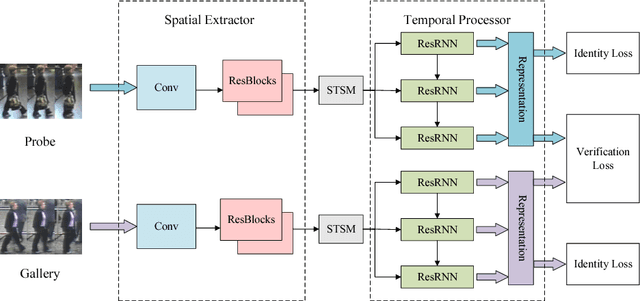
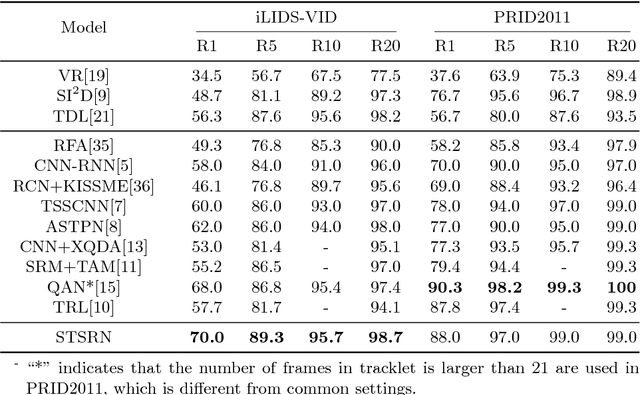
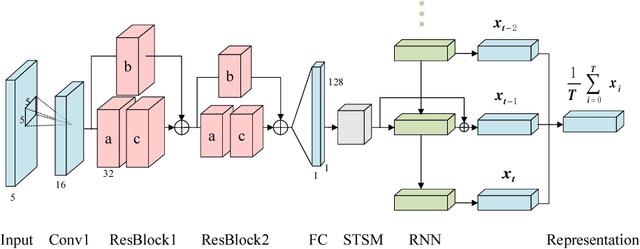
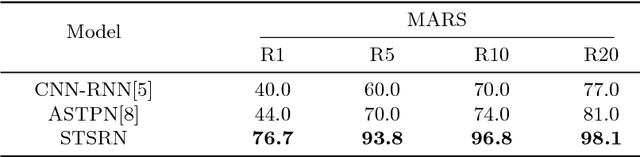
We tackle the problem of person re-identification in video setting in this paper, which has been viewed as a crucial task in many applications. Meanwhile, it is very challenging since the task requires learning effective representations from video sequences with heterogeneous spatial-temporal information. We present a novel method - Spatial-Temporal Synergic Residual Network (STSRN) for this problem. STSRN contains a spatial residual extractor, a temporal residual processor and a spatial-temporal smooth module. The smoother can alleviate sample noises along the spatial-temporal dimensions thus enable STSRN extracts more robust spatial-temporal features of consecutive frames. Extensive experiments are conducted on several challenging datasets including iLIDS-VID, PRID2011 and MARS. The results demonstrate that the proposed method achieves consistently superior performance over most of state-of-the-art methods.
Scheduled Policy Optimization for Natural Language Communication with Intelligent Agents
Jul 07, 2018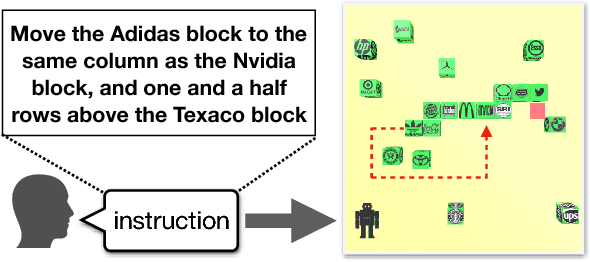
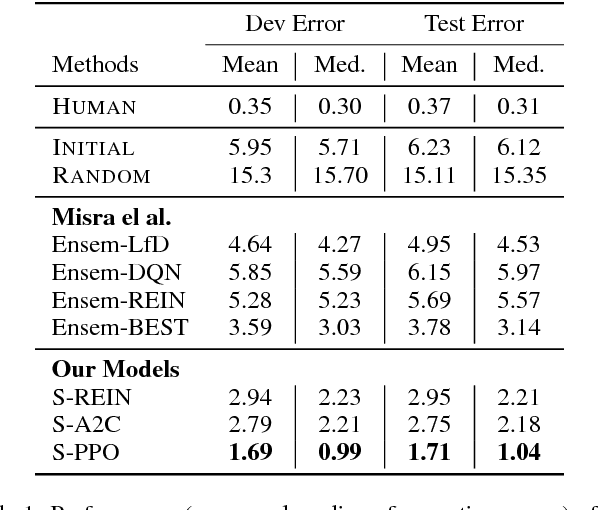
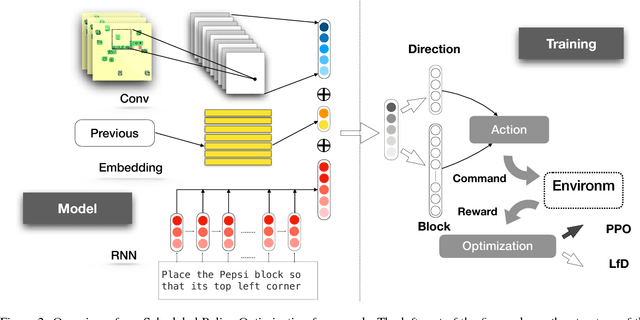
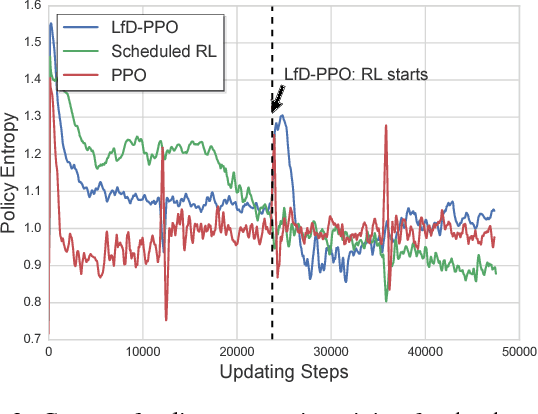
We investigate the task of learning to follow natural language instructions by jointly reasoning with visual observations and language inputs. In contrast to existing methods which start with learning from demonstrations (LfD) and then use reinforcement learning (RL) to fine-tune the model parameters, we propose a novel policy optimization algorithm which dynamically schedules demonstration learning and RL. The proposed training paradigm provides efficient exploration and better generalization beyond existing methods. Comparing to existing ensemble models, the best single model based on our proposed method tremendously decreases the execution error by over 50% on a block-world environment. To further illustrate the exploration strategy of our RL algorithm, We also include systematic studies on the evolution of policy entropy during training.
A Co-Matching Model for Multi-choice Reading Comprehension
Jun 11, 2018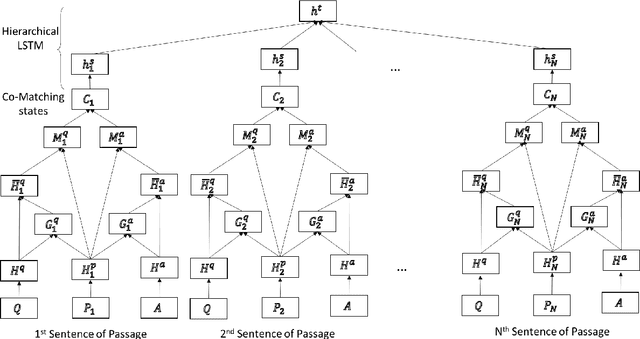
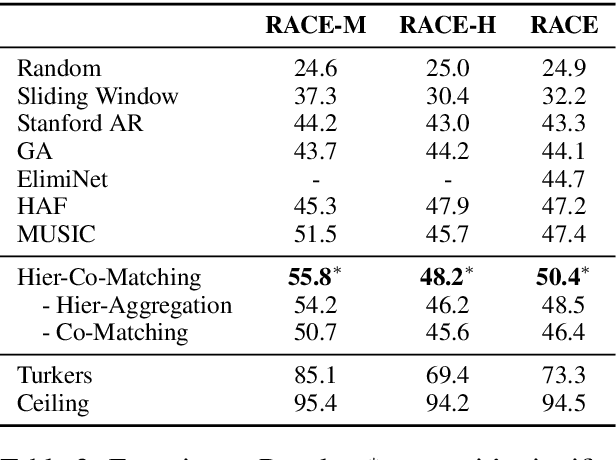
Multi-choice reading comprehension is a challenging task, which involves the matching between a passage and a question-answer pair. This paper proposes a new co-matching approach to this problem, which jointly models whether a passage can match both a question and a candidate answer. Experimental results on the RACE dataset demonstrate that our approach achieves state-of-the-art performance.
Diverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018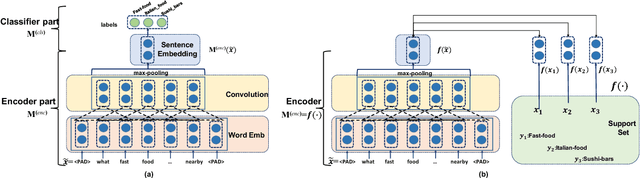
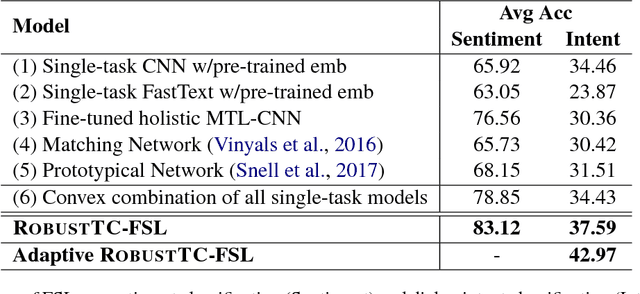
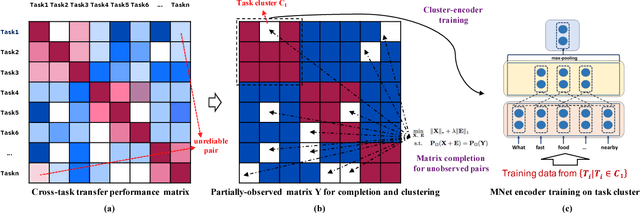
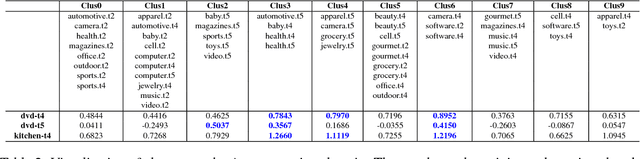
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.