 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanning for Gold: Expanding Domain-Specific Knowledge Graphs with General Knowledge
Jan 15, 2026Domain-specific knowledge graphs (DKGs) often lack coverage compared to general knowledge graphs (GKGs). To address this, we introduce Domain-specific Knowledge Graph Fusion (DKGF), a novel task that enriches DKGs by integrating relevant facts from GKGs. DKGF faces two key challenges: high ambiguity in domain relevance and misalignment in knowledge granularity across graphs. We propose ExeFuse, a simple yet effective Fact-as-Program paradigm. It treats each GKG fact as a latent semantic program, maps abstract relations to granularity-aware operators, and verifies domain relevance via program executability on the target DKG. This unified probabilistic framework jointly resolves relevance and granularity issues. We construct two benchmarks, DKGF(W-I) and DKGF(Y-I), with 21 evaluation configurations. Extensive experiments validate the task's importance and our model's effectiveness, providing the first standardized testbed for DKGF.
NeSTR: A Neuro-Symbolic Abductive Framework for Temporal Reasoning in Large Language Models
Dec 08, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, temporal reasoning, particularly under complex temporal constraints, remains a major challenge. To this end, existing approaches have explored symbolic methods, which encode temporal structure explicitly, and reflective mechanisms, which revise reasoning errors through multi-step inference. Nonetheless, symbolic approaches often underutilize the reasoning capabilities of LLMs, while reflective methods typically lack structured temporal representations, which can result in inconsistent or hallucinated reasoning. As a result, even when the correct temporal context is available, LLMs may still misinterpret or misapply time-related information, leading to incomplete or inaccurate answers. To address these limitations, in this work, we propose Neuro-Symbolic Temporal Reasoning (NeSTR), a novel framework that integrates structured symbolic representations with hybrid reflective reasoning to enhance the temporal sensitivity of LLM inference. NeSTR preserves explicit temporal relations through symbolic encoding, enforces logical consistency via verification, and corrects flawed inferences using abductive reflection. Extensive experiments on diverse temporal question answering benchmarks demonstrate that NeSTR achieves superior zero-shot performance and consistently improves temporal reasoning without any fine-tuning, showcasing the advantage of neuro-symbolic integration in enhancing temporal understanding in large language models.
Each Fake News is Fake in its Own Way: An Attribution Multi-Granularity Benchmark for Multimodal Fake News Detection
Dec 19, 2024



Social platforms, while facilitating access to information, have also become saturated with a plethora of fake news, resulting in negative consequences. Automatic multimodal fake news detection is a worthwhile pursuit. Existing multimodal fake news datasets only provide binary labels of real or fake. However, real news is alike, while each fake news is fake in its own way. These datasets fail to reflect the mixed nature of various types of multimodal fake news. To bridge the gap, we construct an attributing multi-granularity multimodal fake news detection dataset \amg, revealing the inherent fake pattern. Furthermore, we propose a multi-granularity clue alignment model \our to achieve multimodal fake news detection and attribution. Experimental results demonstrate that \amg is a challenging dataset, and its attribution setting opens up new avenues for future research.
Open Knowledge Base Canonicalization with Multi-task Learning
Mar 21, 2024



The construction of large open knowledge bases (OKBs) is integral to many knowledge-driven applications on the world wide web such as web search. However, noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Nevertheless, these works fail to fully exploit the synergy between clustering and KGE learning, and the methods designed for these subtasks are sub-optimal. To this end, we put forward a multi-task learning framework, namely MulCanon, to tackle OKB canonicalization. In addition, diffusion model is used in the soft clustering process to improve the noun phrase representations with neighboring information, which can lead to more accurate representations. MulCanon unifies the learning objectives of these sub-tasks, and adopts a two-stage multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization benchmarks validates that MulCanon can achieve competitive canonicalization results.
Open Knowledge Base Canonicalization with Multi-task Unlearning
Oct 25, 2023



The construction of large open knowledge bases (OKBs) is integral to many applications in the field of mobile computing. Noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. However, in order to meet the requirements of some privacy protection regulations and to ensure the timeliness of the data, the canonicalized OKB often needs to remove some sensitive information or outdated data. The machine unlearning in OKB canonicalization is an excellent solution to the above problem. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Effective schemes are urgently needed to fully synergise machine unlearning with clustering and KGE learning. To this end, we put forward a multi-task unlearning framework, namely MulCanon, to tackle machine unlearning problem in OKB canonicalization. Specifically, the noise characteristics in the diffusion model are utilized to achieve the effect of machine unlearning for data in OKB. MulCanon unifies the learning objectives of diffusion model, KGE and clustering algorithms, and adopts a two-step multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization datasets validates that MulCanon achieves advanced machine unlearning effects.
Multi-modal Entity Alignment in Hyperbolic Space
Jun 07, 2021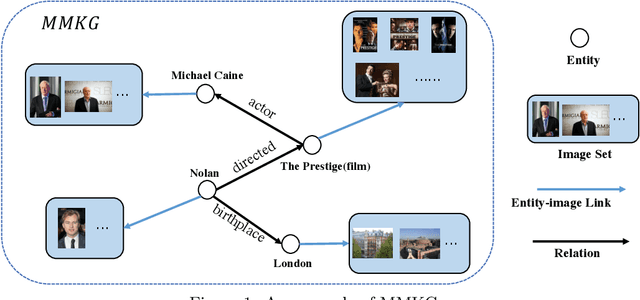
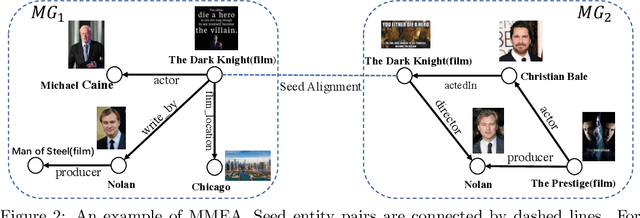
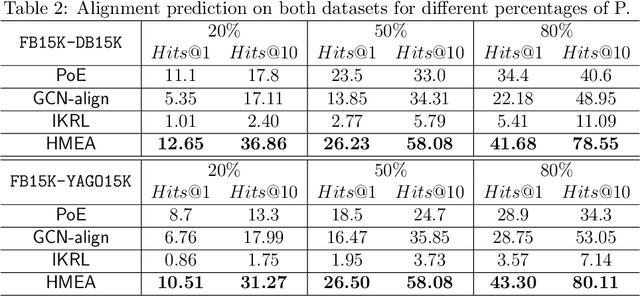
Many AI-related tasks involve the interactions of data in multiple modalities. It has been a new trend to merge multi-modal information into knowledge graph(KG), resulting in multi-modal knowledge graphs (MMKG). However, MMKGs usually suffer from low coverage and incompleteness. To mitigate this problem, a viable approach is to integrate complementary knowledge from other MMKGs. To this end, although existing entity alignment approaches could be adopted, they operate in the Euclidean space, and the resulting Euclidean entity representations can lead to large distortion of KG's hierarchical structure. Besides, the visual information has yet not been well exploited. In response to these issues, in this work, we propose a novel multi-modal entity alignment approach, Hyperbolic multi-modal entity alignment(HMEA), which extends the Euclidean representation to hyperboloid manifold. We first adopt the Hyperbolic Graph Convolutional Networks (HGCNs) to learn structural representations of entities. Regarding the visual information, we generate image embeddings using the densenet model, which are also projected into the hyperbolic space using HGCNs. Finally, we combine the structure and visual representations in the hyperbolic space and use the aggregated embeddings to predict potential alignment results. Extensive experiments and ablation studies demonstrate the effectiveness of our proposed model and its components.
Towards Entity Alignment in the Open World: An Unsupervised Approach
Jan 26, 2021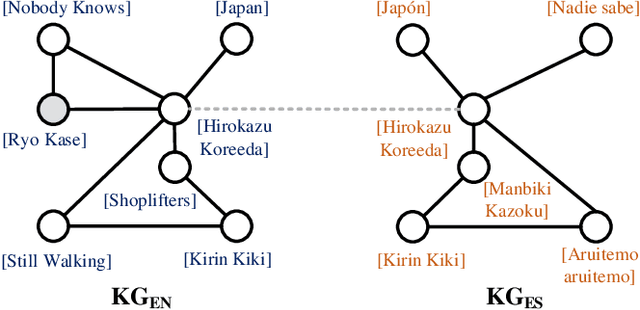
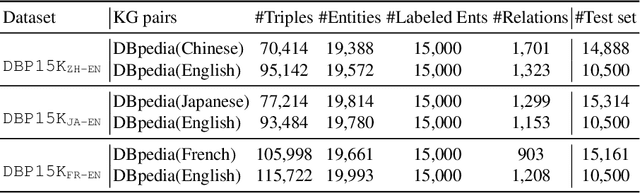
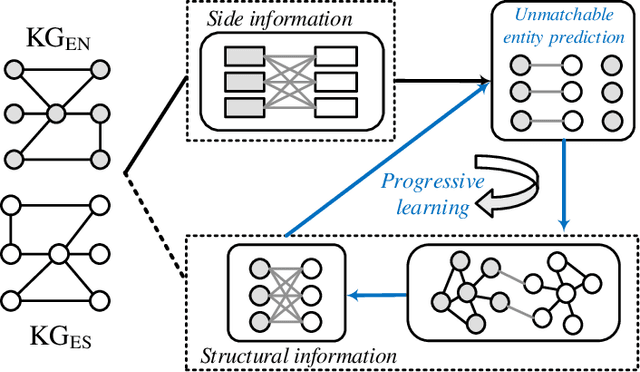
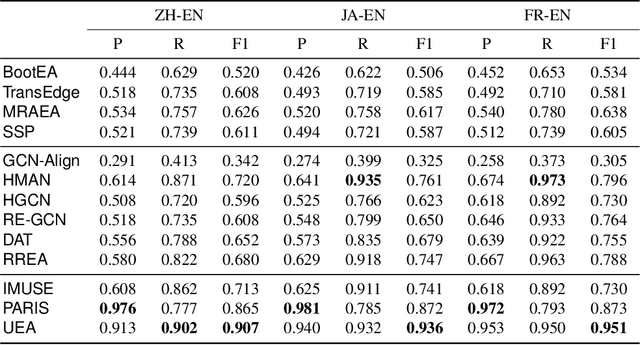
Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs). It is a pivotal step for integrating KGs to increase knowledge coverage and quality. Recent years have witnessed a rapid increase of EA frameworks. However, state-of-the-art solutions tend to rely on labeled data for model training. Additionally, they work under the closed-domain setting and cannot deal with entities that are unmatchable. To address these deficiencies, we offer an unsupervised framework that performs entity alignment in the open world. Specifically, we first mine useful features from the side information of KGs. Then, we devise an unmatchable entity prediction module to filter out unmatchable entities and produce preliminary alignment results. These preliminary results are regarded as the pseudo-labeled data and forwarded to the progressive learning framework to generate structural representations, which are integrated with the side information to provide a more comprehensive view for alignment. Finally, the progressive learning framework gradually improves the quality of structural embeddings and enhances the alignment performance by enriching the pseudo-labeled data with alignment results from the previous round. Our solution does not require labeled data and can effectively filter out unmatchable entities. Comprehensive experimental evaluations validate its superiority.
Reinforcement Learning based Collective Entity Alignment with Adaptive Features
Jan 05, 2021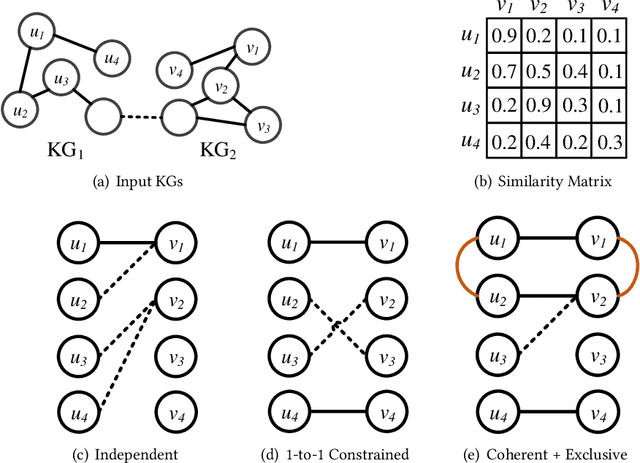
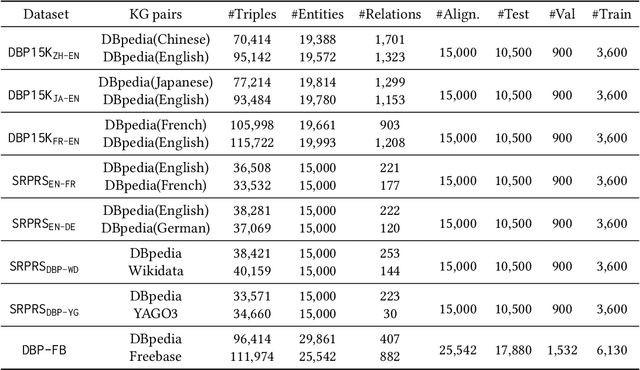
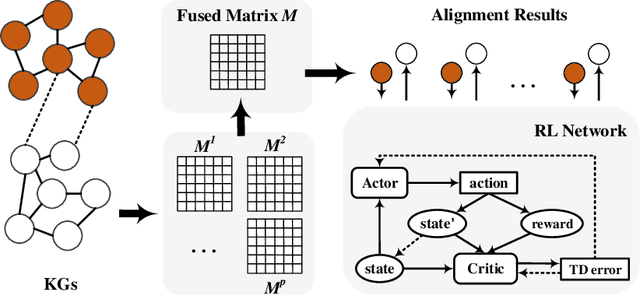
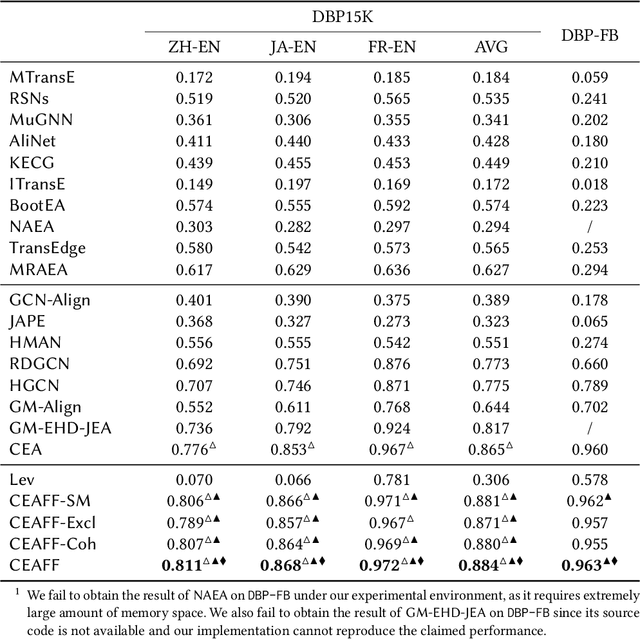
Entity alignment (EA) is the task of identifying the entities that refer to the same real-world object but are located in different knowledge graphs (KGs). For entities to be aligned, existing EA solutions treat them separately and generate alignment results as ranked lists of entities on the other side. Nevertheless, this decision-making paradigm fails to take into account the interdependence among entities. Although some recent efforts mitigate this issue by imposing the 1-to-1 constraint on the alignment process, they still cannot adequately model the underlying interdependence and the results tend to be sub-optimal. To fill in this gap, in this work, we delve into the dynamics of the decision-making process, and offer a reinforcement learning (RL) based model to align entities collectively. Under the RL framework, we devise the coherence and exclusiveness constraints to characterize the interdependence and restrict collective alignment. Additionally, to generate more precise inputs to the RL framework, we employ representative features to capture different aspects of the similarity between entities in heterogeneous KGs, which are integrated by an adaptive feature fusion strategy. Our proposal is evaluated on both cross-lingual and mono-lingual EA benchmarks and compared against state-of-the-art solutions. The empirical results verify its effectiveness and superiority.
Degree-Aware Alignment for Entities in Tail
May 25, 2020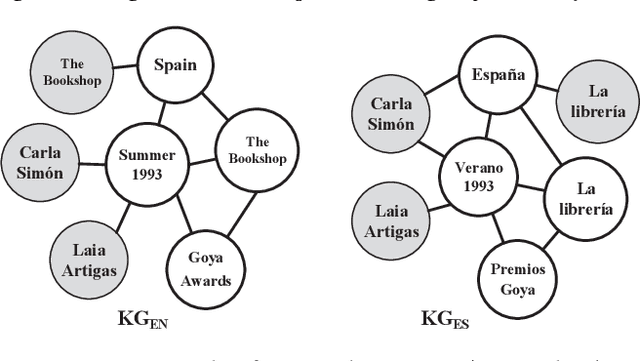
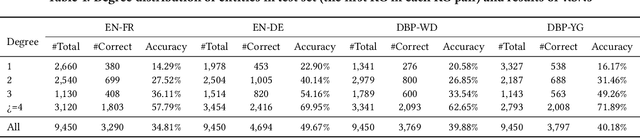
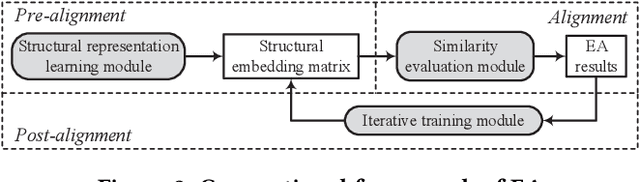
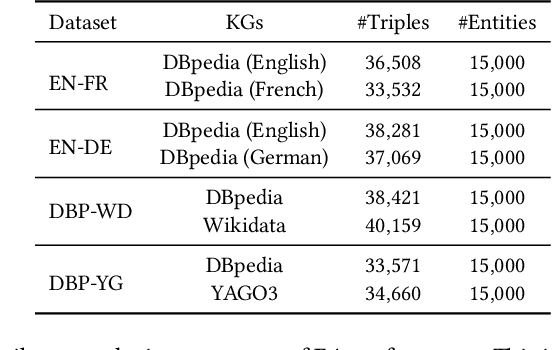
Entity alignment (EA) is to discover equivalent entities in knowledge graphs (KGs), which bridges heterogeneous sources of information and facilitates the integration of knowledge. Existing EA solutions mainly rely on structural information to align entities, typically through KG embedding. Nonetheless, in real-life KGs, only a few entities are densely connected to others, and the rest majority possess rather sparse neighborhood structure. We refer to the latter as long-tail entities, and observe that such phenomenon arguably limits the use of structural information for EA. To mitigate the issue, we revisit and investigate into the conventional EA pipeline in pursuit of elegant performance. For pre-alignment, we propose to amplify long-tail entities, which are of relatively weak structural information, with entity name information that is generally available (but overlooked) in the form of concatenated power mean word embeddings. For alignment, under a novel complementary framework of consolidating structural and name signals, we identify entity's degree as important guidance to effectively fuse two different sources of information. To this end, a degree-aware co-attention network is conceived, which dynamically adjusts the significance of features in a degree-aware manner. For post-alignment, we propose to complement original KGs with facts from their counterparts by using confident EA results as anchors via iterative training. Comprehensive experimental evaluations validate the superiority of our proposed techniques.