 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Aug 25, 2025With the rise of Speech Large Language Models (SpeechLLMs), two dominant approaches have emerged for speech processing: discrete tokens and continuous features. Each approach has demonstrated strong capabilities in audio-related processing tasks. However, the performance gap between these two paradigms has not been thoroughly explored. To address this gap, we present a fair comparison of self-supervised learning (SSL)-based discrete and continuous features under the same experimental settings. We evaluate their performance across six spoken language understanding-related tasks using both small and large-scale LLMs (Qwen1.5-0.5B and Llama3.1-8B). We further conduct in-depth analyses, including efficient comparison, SSL layer analysis, LLM layer analysis, and robustness comparison. Our findings reveal that continuous features generally outperform discrete tokens in various tasks. Each speech processing method exhibits distinct characteristics and patterns in how it learns and processes speech information. We hope our results will provide valuable insights to advance spoken language understanding in SpeechLLMs.
MOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
May 30, 2025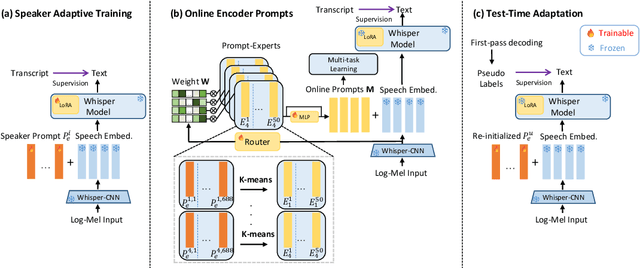
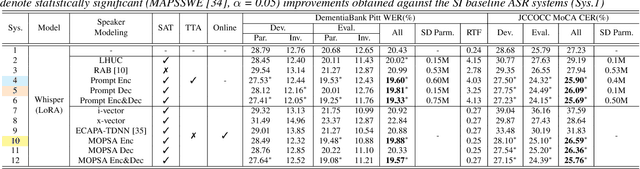
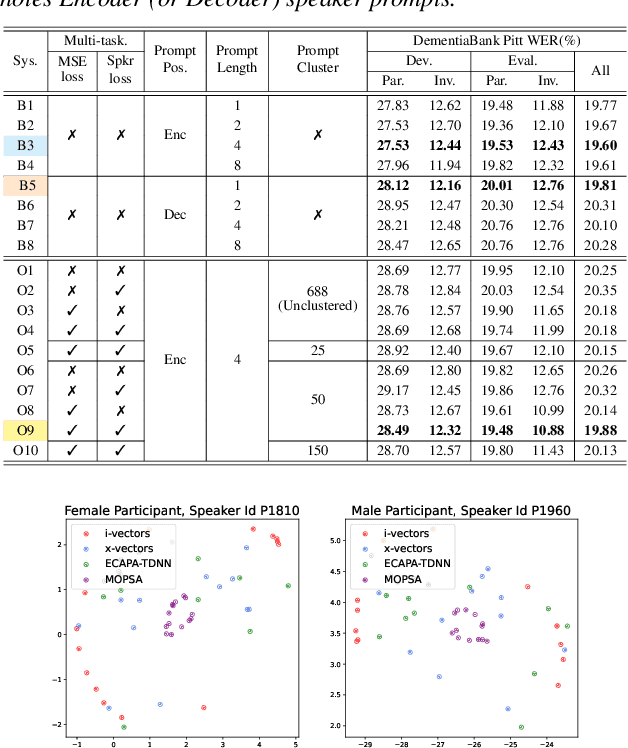
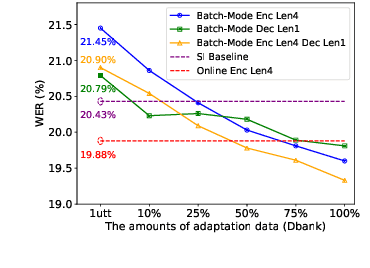
This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.
On-the-fly Routing for Zero-shot MoE Speaker Adaptation of Speech Foundation Models for Dysarthric Speech Recognition
May 28, 2025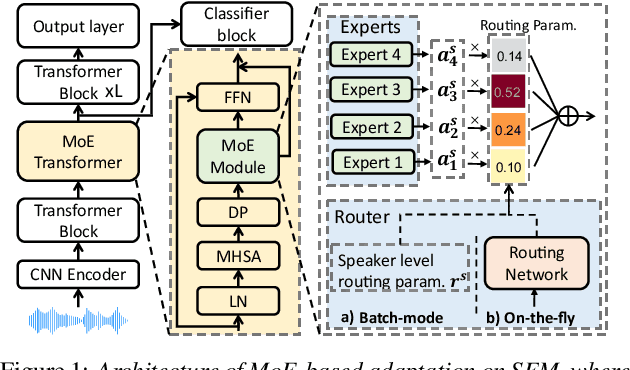
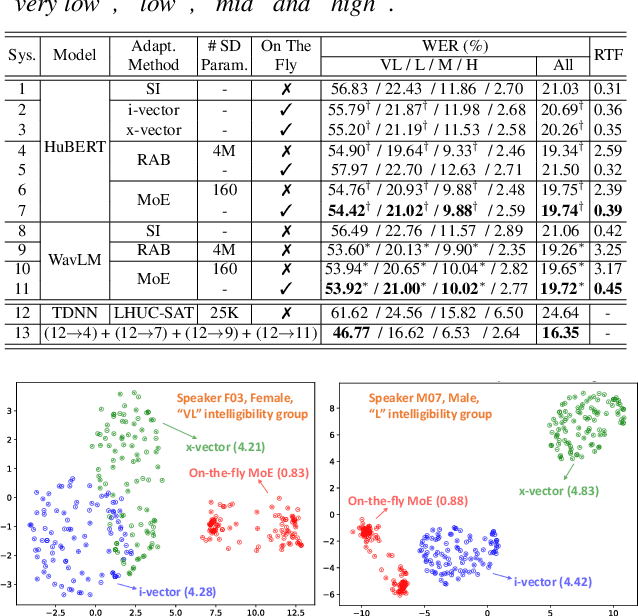
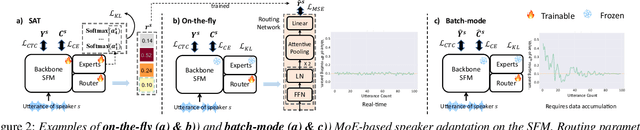

This paper proposes a novel MoE-based speaker adaptation framework for foundation models based dysarthric speech recognition. This approach enables zero-shot adaptation and real-time processing while incorporating domain knowledge. Speech impairment severity and gender conditioned adapter experts are dynamically combined using on-the-fly predicted speaker-dependent routing parameters. KL-divergence is used to further enforce diversity among experts and their generalization to unseen speakers. Experimental results on the UASpeech corpus suggest that on-the-fly MoE-based adaptation produces statistically significant WER reductions of up to 1.34% absolute (6.36% relative) over the unadapted baseline HuBERT/WavLM models. Consistent WER reductions of up to 2.55% absolute (11.44% relative) and RTF speedups of up to 7 times are obtained over batch-mode adaptation across varying speaker-level data quantities. The lowest published WER of 16.35% (46.77% on very low intelligibility) is obtained.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Structured Speaker-Deficiency Adaptation of Foundation Models for Dysarthric and Elderly Speech Recognition
Dec 25, 2024



Data-intensive fine-tuning of speech foundation models (SFMs) to scarce and diverse dysarthric and elderly speech leads to data bias and poor generalization to unseen speakers. This paper proposes novel structured speaker-deficiency adaptation approaches for SSL pre-trained SFMs on such data. Speaker and speech deficiency invariant SFMs were constructed in their supervised adaptive fine-tuning stage to reduce undue bias to training data speakers, and serves as a more neutral and robust starting point for test time unsupervised adaptation. Speech variability attributed to speaker identity and speech impairment severity, or aging induced neurocognitive decline, are modelled using separate adapters that can be combined together to model any seen or unseen speaker. Experiments on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest structured speaker-deficiency adaptation of HuBERT and Wav2vec2-conformer models consistently outperforms baseline SFMs using either: a) no adapters; b) global adapters shared among all speakers; or c) single attribute adapters modelling speaker or deficiency labels alone by statistically significant WER reductions up to 3.01% and 1.50% absolute (10.86% and 6.94% relative) on the two tasks respectively. The lowest published WER of 19.45% (49.34% on very low intelligibility, 33.17% on unseen words) is obtained on the UASpeech test set of 16 dysarthric speakers.
A Comparative Study of Discrete Speech Tokens for Semantic-Related Tasks with Large Language Models
Nov 13, 2024



With the rise of Speech Large Language Models (Speech LLMs), there has been growing interest in discrete speech tokens for their ability to integrate with text-based tokens seamlessly. Compared to most studies that focus on continuous speech features, although discrete-token based LLMs have shown promising results on certain tasks, the performance gap between these two paradigms is rarely explored. In this paper, we present a fair and thorough comparison between discrete and continuous features across a variety of semantic-related tasks using a light-weight LLM (Qwen1.5-0.5B). Our findings reveal that continuous features generally outperform discrete tokens, particularly in tasks requiring fine-grained semantic understanding. Moreover, this study goes beyond surface-level comparison by identifying key factors behind the under-performance of discrete tokens, such as limited token granularity and inefficient information retention. To enhance the performance of discrete tokens, we explore potential aspects based on our analysis. We hope our results can offer new insights into the opportunities for advancing discrete speech tokens in Speech LLMs.
Improving Grapheme-to-Phoneme Conversion through In-Context Knowledge Retrieval with Large Language Models
Nov 12, 2024Grapheme-to-phoneme (G2P) conversion is a crucial step in Text-to-Speech (TTS) systems, responsible for mapping grapheme to corresponding phonetic representations. However, it faces ambiguities problems where the same grapheme can represent multiple phonemes depending on contexts, posing a challenge for G2P conversion. Inspired by the remarkable success of Large Language Models (LLMs) in handling context-aware scenarios, contextual G2P conversion systems with LLMs' in-context knowledge retrieval (ICKR) capabilities are proposed to promote disambiguation capability. The efficacy of incorporating ICKR into G2P conversion systems is demonstrated thoroughly on the Librig2p dataset. In particular, the best contextual G2P conversion system using ICKR outperforms the baseline with weighted average phoneme error rate (PER) reductions of 2.0% absolute (28.9% relative). Using GPT-4 in the ICKR system can increase of 3.5% absolute (3.8% relative) on the Librig2p dataset.
Exploring SSL Discrete Tokens for Multilingual ASR
Sep 13, 2024



With the advancement of Self-supervised Learning (SSL) in speech-related tasks, there has been growing interest in utilizing discrete tokens generated by SSL for automatic speech recognition (ASR), as they offer faster processing techniques. However, previous studies primarily focused on multilingual ASR with Fbank features or English ASR with discrete tokens, leaving a gap in adapting discrete tokens for multilingual ASR scenarios. This study presents a comprehensive comparison of discrete tokens generated by various leading SSL models across multiple language domains. We aim to explore the performance and efficiency of speech discrete tokens across multiple language domains for both monolingual and multilingual ASR scenarios. Experimental results demonstrate that discrete tokens achieve comparable results against systems trained on Fbank features in ASR tasks across seven language domains with an average word error rate (WER) reduction of 0.31% and 1.76% absolute (2.80% and 15.70% relative) on dev and test sets respectively, with particularly WER reduction of 6.82% absolute (41.48% relative) on the Polish test set.
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR
Sep 13, 2024



Self-supervised learning (SSL) based discrete speech representations are highly compact and domain adaptable. In this paper, SSL discrete speech features extracted from WavLM models are used as additional cross-utterance acoustic context features in Zipformer-Transducer ASR systems. The efficacy of replacing Fbank features with discrete token features for modelling either cross-utterance contexts (from preceding and future segments), or current utterance's internal contexts alone, or both at the same time, are demonstrated thoroughly on the Gigaspeech 1000-hr corpus. The best Zipformer-Transducer system using discrete tokens based cross-utterance context features outperforms the baseline using utterance internal context only with statistically significant word error rate (WER) reductions of 0.32% to 0.41% absolute (2.78% to 3.54% relative) on the dev and test data. The lowest published WER of 11.15% and 11.14% were obtained on the dev and test sets. Our work is open-source and publicly available at https://github.com/open-creator/icefall/tree/master/egs/gigaspeech/Context\_ASR.
GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement
Jun 17, 2024The evolution of speech technology has been spurred by the rapid increase in dataset sizes. Traditional speech models generally depend on a large amount of labeled training data, which is scarce for low-resource languages. This paper presents GigaSpeech 2, a large-scale, multi-domain, multilingual speech recognition corpus. It is designed for low-resource languages and does not rely on paired speech and text data. GigaSpeech 2 comprises about 30,000 hours of automatically transcribed speech, including Thai, Indonesian, and Vietnamese, gathered from unlabeled YouTube videos. We also introduce an automated pipeline for data crawling, transcription, and label refinement. Specifically, this pipeline uses Whisper for initial transcription and TorchAudio for forced alignment, combined with multi-dimensional filtering for data quality assurance. A modified Noisy Student Training is developed to further refine flawed pseudo labels iteratively, thus enhancing model performance. Experimental results on our manually transcribed evaluation set and two public test sets from Common Voice and FLEURS confirm our corpus's high quality and broad applicability. Notably, ASR models trained on GigaSpeech 2 can reduce the word error rate for Thai, Indonesian, and Vietnamese on our challenging and realistic YouTube test set by 25% to 40% compared to the Whisper large-v3 model, with merely 10% model parameters. Furthermore, our ASR models trained on Gigaspeech 2 yield superior performance compared to commercial services. We believe that our newly introduced corpus and pipeline will open a new avenue for low-resource speech recognition and significantly facilitate research in this area.