 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRA: Covariate-Aware Adaptation of Time Series Foundation Models
Oct 14, 2025Time Series Foundation Models (TSFMs) have shown significant impact through their model capacity, scalability, and zero-shot generalization. However, due to the heterogeneity of inter-variate dependencies and the backbone scalability on large-scale multivariate datasets, most TSFMs are typically pre-trained on univariate time series. This limitation renders them oblivious to crucial information from diverse covariates in real-world forecasting tasks. To further enhance the performance of TSFMs, we propose a general covariate-aware adaptation (CoRA) framework for TSFMs. It leverages pre-trained backbones of foundation models while effectively incorporating exogenous covariates from various modalities, including time series, language, and images, to improve the quality of predictions. Technically, CoRA maintains the equivalence of initialization and parameter consistency during adaptation. With preserved backbones of foundation models as frozen feature extractors, the outcome embeddings from foundation models are empirically demonstrated more informative than raw data. Further, CoRA employs a novel Granger Causality Embedding (GCE) to automatically evaluate covariates regarding their causal predictability with respect to the target variate. We incorporate these weighted embeddings with a zero-initialized condition-injection mechanism, avoiding catastrophic forgetting of pre-trained foundation models and gradually integrates exogenous information. Extensive experiments show that CoRA of TSFMs surpasses state-of-the-art covariate-aware deep forecasters with full or few-shot training samples, achieving 31.1% MSE reduction on covariate-aware forecasting. Compared to other adaptation methods, CoRA exhibits strong compatibility with various advanced TSFMs and extends the scope of covariates to other modalities, presenting a practical paradigm for the application of TSFMs.
Consistent World Models via Foresight Diffusion
May 22, 2025Diffusion and flow-based models have enabled significant progress in generation tasks across various modalities and have recently found applications in world modeling. However, unlike typical generation tasks that encourage sample diversity, world models entail different sources of uncertainty and require consistent samples aligned with the ground-truth trajectory, which is a limitation we empirically observe in diffusion models. We argue that a key bottleneck in learning consistent diffusion-based world models lies in the suboptimal predictive ability, which we attribute to the entanglement of condition understanding and target denoising within shared architectures and co-training schemes. To address this, we propose Foresight Diffusion (ForeDiff), a diffusion-based world modeling framework that enhances consistency by decoupling condition understanding from target denoising. ForeDiff incorporates a separate deterministic predictive stream to process conditioning inputs independently of the denoising stream, and further leverages a pretrained predictor to extract informative representations that guide generation. Extensive experiments on robot video prediction and scientific spatiotemporal forecasting show that ForeDiff improves both predictive accuracy and sample consistency over strong baselines, offering a promising direction for diffusion-based world models.
Vid2World: Crafting Video Diffusion Models to Interactive World Models
May 20, 2025



World models, which predict transitions based on history observation and action sequences, have shown great promise in improving data efficiency for sequential decision making. However, existing world models often require extensive domain-specific training and still produce low-fidelity, coarse predictions, limiting their applicability in complex environments. In contrast, video diffusion models trained on large, internet-scale datasets have demonstrated impressive capabilities in generating high-quality videos that capture diverse real-world dynamics. In this work, we present Vid2World, a general approach for leveraging and transferring pre-trained video diffusion models into interactive world models. To bridge the gap, Vid2World performs casualization of a pre-trained video diffusion model by crafting its architecture and training objective to enable autoregressive generation. Furthermore, it introduces a causal action guidance mechanism to enhance action controllability in the resulting interactive world model. Extensive experiments in robot manipulation and game simulation domains show that our method offers a scalable and effective approach for repurposing highly capable video diffusion models to interactive world models.
RLVR-World: Training World Models with Reinforcement Learning
May 20, 2025World models predict state transitions in response to actions and are increasingly developed across diverse modalities. However, standard training objectives such as maximum likelihood estimation (MLE) often misalign with task-specific goals of world models, i.e., transition prediction metrics like accuracy or perceptual quality. In this paper, we present RLVR-World, a unified framework that leverages reinforcement learning with verifiable rewards (RLVR) to directly optimize world models for such metrics. Despite formulating world modeling as autoregressive prediction of tokenized sequences, RLVR-World evaluates metrics of decoded predictions as verifiable rewards. We demonstrate substantial performance gains on both language- and video-based world models across domains, including text games, web navigation, and robot manipulation. Our work indicates that, beyond recent advances in reasoning language models, RLVR offers a promising post-training paradigm for enhancing the utility of generative models more broadly.
FlashBias: Fast Computation of Attention with Bias
May 17, 2025Attention mechanism has emerged as a foundation module of modern deep learning models and has also empowered many milestones in various domains. Moreover, FlashAttention with IO-aware speedup resolves the efficiency issue of standard attention, further promoting its practicality. Beyond canonical attention, attention with bias also widely exists, such as relative position bias in vision and language models and pair representation bias in AlphaFold. In these works, prior knowledge is introduced as an additive bias term of attention weights to guide the learning process, which has been proven essential for model performance. Surprisingly, despite the common usage of attention with bias, its targeted efficiency optimization is still absent, which seriously hinders its wide applications in complex tasks. Diving into the computation of FlashAttention, we prove that its optimal efficiency is determined by the rank of the attention weight matrix. Inspired by this theoretical result, this paper presents FlashBias based on the low-rank compressed sensing theory, which can provide fast-exact computation for many widely used attention biases and a fast-accurate approximation for biases in general formalization. FlashBias can fully take advantage of the extremely optimized matrix multiplication operation in modern GPUs, achieving 1.5$\times$ speedup for AlphaFold, and over 2$\times$ speedup for attention with bias in vision and language models without loss of accuracy.
Domain Guidance: A Simple Transfer Approach for a Pre-trained Diffusion Model
Apr 02, 2025Recent advancements in diffusion models have revolutionized generative modeling. However, the impressive and vivid outputs they produce often come at the cost of significant model scaling and increased computational demands. Consequently, building personalized diffusion models based on off-the-shelf models has emerged as an appealing alternative. In this paper, we introduce a novel perspective on conditional generation for transferring a pre-trained model. From this viewpoint, we propose *Domain Guidance*, a straightforward transfer approach that leverages pre-trained knowledge to guide the sampling process toward the target domain. Domain Guidance shares a formulation similar to advanced classifier-free guidance, facilitating better domain alignment and higher-quality generations. We provide both empirical and theoretical analyses of the mechanisms behind Domain Guidance. Our experimental results demonstrate its substantial effectiveness across various transfer benchmarks, achieving over a 19.6% improvement in FID and a 23.4% improvement in FD$_\text{DINOv2}$ compared to standard fine-tuning. Notably, existing fine-tuned models can seamlessly integrate Domain Guidance to leverage these benefits, without additional training.
Dynamical Diffusion: Learning Temporal Dynamics with Diffusion Models
Mar 02, 2025Diffusion models have emerged as powerful generative frameworks by progressively adding noise to data through a forward process and then reversing this process to generate realistic samples. While these models have achieved strong performance across various tasks and modalities, their application to temporal predictive learning remains underexplored. Existing approaches treat predictive learning as a conditional generation problem, but often fail to fully exploit the temporal dynamics inherent in the data, leading to challenges in generating temporally coherent sequences. To address this, we introduce Dynamical Diffusion (DyDiff), a theoretically sound framework that incorporates temporally aware forward and reverse processes. Dynamical Diffusion explicitly models temporal transitions at each diffusion step, establishing dependencies on preceding states to better capture temporal dynamics. Through the reparameterization trick, Dynamical Diffusion achieves efficient training and inference similar to any standard diffusion model. Extensive experiments across scientific spatiotemporal forecasting, video prediction, and time series forecasting demonstrate that Dynamical Diffusion consistently improves performance in temporal predictive tasks, filling a crucial gap in existing methodologies. Code is available at this repository: https://github.com/thuml/dynamical-diffusion.
TimesBERT: A BERT-Style Foundation Model for Time Series Understanding
Feb 28, 2025



Time series analysis is crucial in diverse scenarios. Beyond forecasting, considerable real-world tasks are categorized into classification, imputation, and anomaly detection, underscoring different capabilities termed time series understanding in this paper. While GPT-style models have been positioned as foundation models for time series forecasting, the BERT-style architecture, which has made significant advances in natural language understanding, has not been fully unlocked for time series understanding, possibly attributed to the undesirable dropout of essential elements of BERT. In this paper, inspired by the shared multi-granularity structure between multivariate time series and multisentence documents, we design TimesBERT to learn generic representations of time series including temporal patterns and variate-centric characteristics. In addition to a natural adaptation of masked modeling, we propose a parallel task of functional token prediction to embody vital multi-granularity structures. Our model is pre-trained on 260 billion time points across diverse domains. Leveraging multi-granularity representations, TimesBERT achieves state-of-the-art performance across four typical downstream understanding tasks, outperforming task-specific models and language pre-trained backbones, positioning it as a versatile foundation model for time series understanding.
Transolver++: An Accurate Neural Solver for PDEs on Million-Scale Geometries
Feb 04, 2025Although deep models have been widely explored in solving partial differential equations (PDEs), previous works are primarily limited to data only with up to tens of thousands of mesh points, far from the million-point scale required by industrial simulations that involve complex geometries. In the spirit of advancing neural PDE solvers to real industrial applications, we present Transolver++, a highly parallel and efficient neural solver that can accurately solve PDEs on million-scale geometries. Building upon previous advancements in solving PDEs by learning physical states via Transolver, Transolver++ is further equipped with an extremely optimized parallelism framework and a local adaptive mechanism to efficiently capture eidetic physical states from massive mesh points, successfully tackling the thorny challenges in computation and physics learning when scaling up input mesh size. Transolver++ increases the single-GPU input capacity to million-scale points for the first time and is capable of continuously scaling input size in linear complexity by increasing GPUs. Experimentally, Transolver++ yields 13% relative promotion across six standard PDE benchmarks and achieves over 20% performance gain in million-scale high-fidelity industrial simulations, whose sizes are 100$\times$ larger than previous benchmarks, covering car and 3D aircraft designs.
Trajectory World Models for Heterogeneous Environments
Feb 03, 2025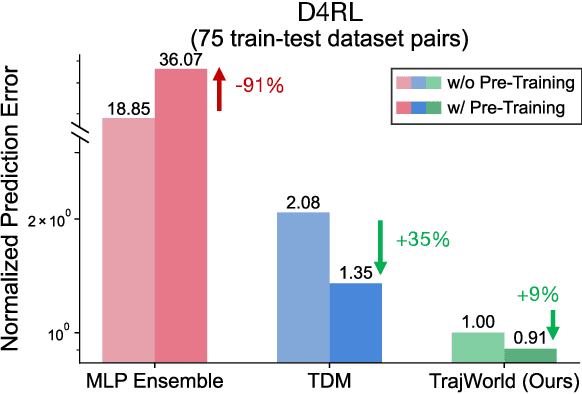
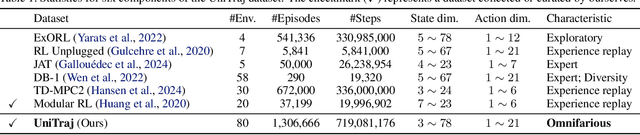
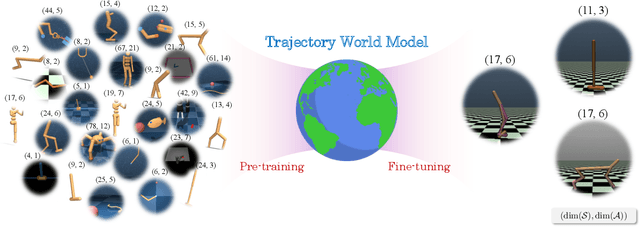
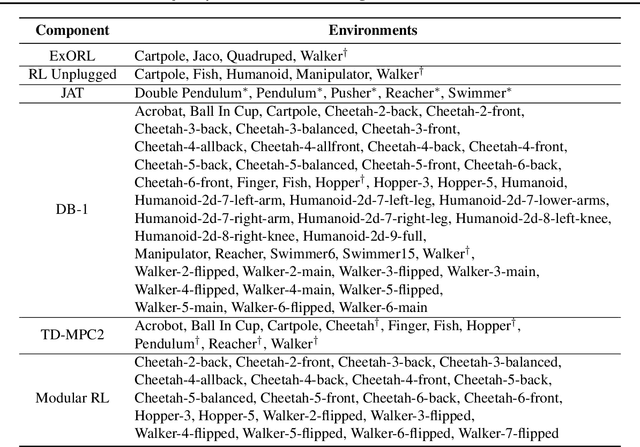
Heterogeneity in sensors and actuators across environments poses a significant challenge to building large-scale pre-trained world models on top of this low-dimensional sensor information. In this work, we explore pre-training world models for heterogeneous environments by addressing key transfer barriers in both data diversity and model flexibility. We introduce UniTraj, a unified dataset comprising over one million trajectories from 80 environments, designed to scale data while preserving critical diversity. Additionally, we propose TrajWorld, a novel architecture capable of flexibly handling varying sensor and actuator information and capturing environment dynamics in-context. Pre-training TrajWorld on UniTraj demonstrates significant improvements in transition prediction and achieves a new state-of-the-art for off-policy evaluation. To the best of our knowledge, this work, for the first time, demonstrates the transfer benefits of world models across heterogeneous and complex control environments.