 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Generation with Covariate Time Series
Mar 05, 2026While RAG has greatly enhanced LLMs, extending this paradigm to Time-Series Foundation Models (TSFMs) remains a challenge. This is exemplified in the Predictive Maintenance of the Pressure Regulating and Shut-Off Valve (PRSOV), a high-stakes industrial scenario characterized by (1) data scarcity, (2) short transient sequences, and (3) covariate coupled dynamics. Unfortunately, existing time-series RAG approaches predominantly rely on generated static vector embeddings and learnable context augmenters, which may fail to distinguish similar regimes in such scarce, transient, and covariate coupled scenarios. To address these limitations, we propose RAG4CTS, a regime-aware, training-free RAG framework for Covariate Time-Series. Specifically, we construct a hierarchal time-series native knowledge base to enable lossless storage and physics-informed retrieval of raw historical regimes. We design a two-stage bi-weighted retrieval mechanism that aligns historical trends through point-wise and multivariate similarities. For context augmentation, we introduce an agent-driven strategy to dynamically optimize context in a self-supervised manner. Extensive experiments on PRSOV demonstrate that our framework significantly outperforms state-of-the-art baselines in prediction accuracy. The proposed system is deployed in Apache IoTDB within China Southern Airlines. Since deployment, our method has successfully identified one PRSOV fault in two months with zero false alarm.
Aura: Universal Multi-dimensional Exogenous Integration for Aviation Time Series
Mar 05, 2026Time series forecasting has witnessed an increasing demand across diverse industrial applications, where accurate predictions are pivotal for informed decision-making. Beyond numerical time series data, reliable forecasting in practical scenarios requires integrating diverse exogenous factors. Such exogenous information is often multi-dimensional or even multimodal, introducing heterogeneous interactions that unimodal time series models struggle to capture. In this paper, we delve into an aviation maintenance scenario and identify three distinct types of exogenous factors that influence temporal dynamics through distinct interaction modes. Based on this empirical insight, we propose Aura, a universal framework that explicitly organizes and encodes heterogeneous external information according to its interaction mode with the target time series. Specifically, Aura utilizes a tailored tripartite encoding mechanism to embed heterogeneous features into well-established time series models, ensuring seamless integration of non-sequential context. Extensive experiments on a large-scale, three-year industrial dataset from China Southern Airlines, covering the Boeing 777 and Airbus A320 fleets, demonstrate that Aura consistently achieves state-of-the-art performance across all baselines and exhibits superior adaptability. Our findings highlight Aura's potential as a general-purpose enhancement for aviation safety and reliability.
Boosting AI Reliability with an FSM-Driven Streaming Inference Pipeline: An Industrial Case
Mar 02, 2026The widespread adoption of AI in industry is often hampered by its limited robustness when faced with scenarios absent from training data, leading to prediction bias and vulnerabilities. To address this, we propose a novel streaming inference pipeline that enhances data-driven models by explicitly incorporating prior knowledge. This paper presents the work on an industrial AI application that automatically counts excavator workloads from surveillance videos. Our approach integrates an object detection model with a Finite State Machine (FSM), which encodes knowledge of operational scenarios to guide and correct the AI's predictions on streaming data. In experiments on a real-world dataset of over 7,000 images from 12 site videos, encompassing more than 300 excavator workloads, our method demonstrates superior performance and greater robustness compared to the original solution based on manual heuristic rules. We will release the code at https://github.com/thulab/video-streamling-inference-pipeline.
Thoth: Mid-Training Bridges LLMs to Time Series Understanding
Mar 01, 2026Large Language Models (LLMs) have demonstrated remarkable success in general-purpose reasoning. However, they still struggle to understand and reason about time series data, which limits their effectiveness in decision-making scenarios that depend on temporal dynamics. In this paper, we propose Thoth, the first family of mid-trained LLMs with general-purpose time series understanding capabilities. As a pivotal intermediate stage, mid-training achieves task- and domain-agnostic alignment between time series and natural language, for which we construct Book-of-Thoth, a high-quality, time-series-centric mid-training corpus. Book-of-Thoth enables both time-series-to-text and text-to-time-series generation, equipping LLMs with a foundational grasp of temporal patterns. To better evaluate advanced reasoning capabilities, we further present KnoTS, a novel benchmark of knowledge-intensive time series understanding, designed for joint reasoning over temporal patterns and domain knowledge. Extensive experiments demonstrate that mid-training with Book-of-Thoth enables Thoth to significantly outperform its base model and advanced LLMs across a range of time series question answering benchmarks. Moreover, Thoth exhibits superior capabilities when fine-tuned under data scarcity, underscoring the effectiveness of mid-training for time series understanding. Code is available at: https://github.com/thuml/Thoth.
Adapt Data to Model: Adaptive Transformation Optimization for Domain-shared Time Series Foundation Models
Feb 28, 2026Large time series models (LTMs) have emerged as powerful tools for universal forecasting, yet they often struggle with the inherent diversity and nonstationarity of real-world time series data, leading to an unsatisfactory trade-off between forecasting accuracy and generalization. Rather than continually finetuning new LTM instances for each domain, we propose a data-centric framework, time-series adaptive transformation optimization (TATO), that enables a single frozen pre-trained LTM to adapt to diverse downstream domains through an optimally configured transformation pipeline. Specifically, TATO constructs three representative types of transformations, including context slicing, scale normalization, and outlier correction, to help LTMs better align with target domain characteristics. To ensure robustness, we incorporate carefully selected time series augmentations and a two-stage ranking mechanism that filters out pipelines underperforming on specific metrics. Extensive experiments on state-of-the-art LTMs and widely used datasets demonstrate that TATO consistently and significantly improves domain-adaptive forecasting performance, achieving a maximum reduction in MSE of 65.4\% and an average reduction of 13.6\%. Moreover, TATO is highly efficient, typically completing optimization in under 2 minutes, making it practical for real-world deployment. The source code is available at https://github.com/thulab/TATO.
BTTackler: A Diagnosis-based Framework for Efficient Deep Learning Hyperparameter Optimization
Feb 27, 2026Hyperparameter optimization (HPO) is known to be costly in deep learning, especially when leveraging automated approaches. Most of the existing automated HPO methods are accuracy-based, i.e., accuracy metrics are used to guide the trials of different hyperparameter configurations amongst a specific search space. However, many trials may encounter severe training problems, such as vanishing gradients and insufficient convergence, which can hardly be reflected by accuracy metrics in the early stages of the training and often result in poor performance. This leads to an inefficient optimization trajectory because the bad trials occupy considerable computation resources and reduce the probability of finding excellent hyperparameter configurations within a time limitation. In this paper, we propose \textbf{Bad Trial Tackler (BTTackler)}, a novel HPO framework that introduces training diagnosis to identify training problems automatically and hence tackles bad trials. BTTackler diagnoses each trial by calculating a set of carefully designed quantified indicators and triggers early termination if any training problems are detected. Evaluations are performed on representative HPO tasks consisting of three classical deep neural networks (DNN) and four widely used HPO methods. To better quantify the effectiveness of an automated HPO method, we propose two new measurements based on accuracy and time consumption. Results show the advantage of BTTackler on two-fold: (1) it reduces 40.33\% of time consumption to achieve the same accuracy comparable to baseline methods on average and (2) it conducts 44.5\% more top-10 trials than baseline methods on average within a given time budget. We also released an open-source Python library that allows users to easily apply BTTackler to automated HPO processes with minimal code changes.
TiMi: Empower Time Series Transformers with Multimodal Mixture of Experts
Feb 25, 2026Multimodal time series forecasting has garnered significant attention for its potential to provide more accurate predictions than traditional single-modality models by leveraging rich information inherent in other modalities. However, due to fundamental challenges in modality alignment, existing methods often struggle to effectively incorporate multimodal data into predictions, particularly textual information that has a causal influence on time series fluctuations, such as emergency reports and policy announcements. In this paper, we reflect on the role of textual information in numerical forecasting and propose Time series transformers with Multimodal Mixture-of-Experts, TiMi, to unleash the causal reasoning capabilities of LLMs. Concretely, TiMi utilizes LLMs to generate inferences on future developments, which serve as guidance for time series forecasting. To seamlessly integrate both exogenous factors and time series into predictions, we introduce a Multimodal Mixture-of-Experts (MMoE) module as a lightweight plug-in to empower Transformer-based time series models for multimodal forecasting, eliminating the need for explicit representation-level alignment. Experimentally, our proposed TiMi demonstrates consistent state-of-the-art performance on sixteen real-world multimodal forecasting benchmarks, outperforming advanced baselines while offering both strong adaptability and interpretability.
DualWeaver: Synergistic Feature Weaving Surrogates for Multivariate Forecasting with Univariate Time Series Foundation Models
Feb 25, 2026Time-series foundation models (TSFMs) have achieved strong univariate forecasting through large-scale pre-training, yet effectively extending this success to multivariate forecasting remains challenging. To address this, we propose DualWeaver, a novel framework that adapts univariate TSFMs (Uni-TSFMs) for multivariate forecasting by using a pair of learnable, structurally symmetric surrogate series. Generated by a shared auxiliary feature-fusion module that captures cross-variable dependencies, these surrogates are mapped to TSFM-compatible series via the forecasting objective. The symmetric structure enables parameter-free reconstruction of final predictions directly from the surrogates, without additional parametric decoding. A theoretically grounded regularization term is further introduced to enhance robustness against adaptation collapse. Extensive experiments on diverse real-world datasets show that DualWeaver outperforms state-of-the-art multivariate forecasters in both accuracy and stability. We release the code at https://github.com/li-jinpeng/DualWeaver.
TimesBERT: A BERT-Style Foundation Model for Time Series Understanding
Feb 28, 2025



Time series analysis is crucial in diverse scenarios. Beyond forecasting, considerable real-world tasks are categorized into classification, imputation, and anomaly detection, underscoring different capabilities termed time series understanding in this paper. While GPT-style models have been positioned as foundation models for time series forecasting, the BERT-style architecture, which has made significant advances in natural language understanding, has not been fully unlocked for time series understanding, possibly attributed to the undesirable dropout of essential elements of BERT. In this paper, inspired by the shared multi-granularity structure between multivariate time series and multisentence documents, we design TimesBERT to learn generic representations of time series including temporal patterns and variate-centric characteristics. In addition to a natural adaptation of masked modeling, we propose a parallel task of functional token prediction to embody vital multi-granularity structures. Our model is pre-trained on 260 billion time points across diverse domains. Leveraging multi-granularity representations, TimesBERT achieves state-of-the-art performance across four typical downstream understanding tasks, outperforming task-specific models and language pre-trained backbones, positioning it as a versatile foundation model for time series understanding.
Requirements Engineering for Machine Learning: A Review and Reflection
Oct 03, 2022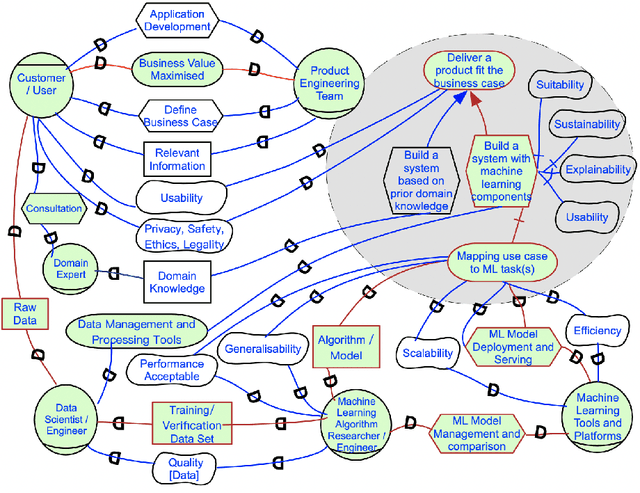
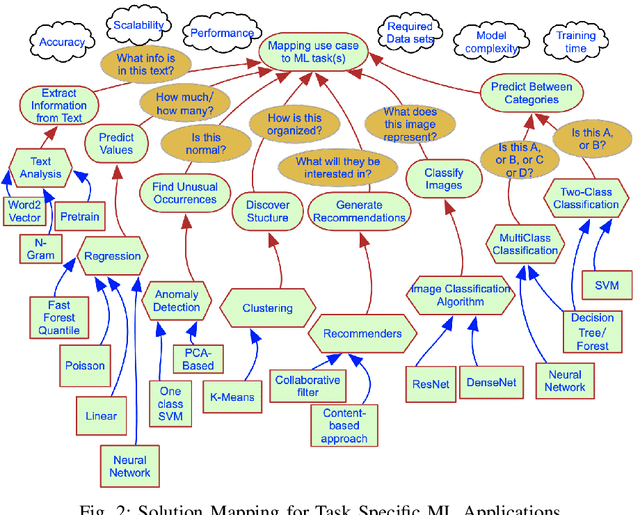
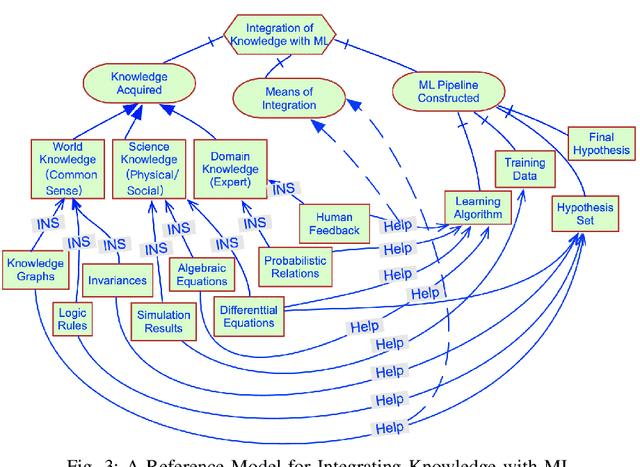
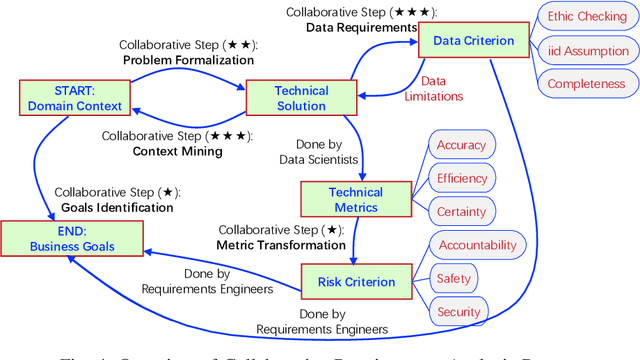
Today, many industrial processes are undergoing digital transformation, which often requires the integration of well-understood domain models and state-of-the-art machine learning technology in business processes. However, requirements elicitation and design decision making about when, where and how to embed various domain models and end-to-end machine learning techniques properly into a given business workflow requires further exploration. This paper aims to provide an overview of the requirements engineering process for machine learning applications in terms of cross domain collaborations. We first review the literature on requirements engineering for machine learning, and then go through the collaborative requirements analysis process step-by-step. An example case of industrial data-driven intelligence applications is also discussed in relation to the aforementioned steps.