 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Jan 11, 2024



The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.
Eva-KELLM: A New Benchmark for Evaluating Knowledge Editing of LLMs
Aug 19, 2023Large language models (LLMs) possess a wealth of knowledge encoded in their parameters. However, this knowledge may become outdated or unsuitable over time. As a result, there has been a growing interest in knowledge editing for LLMs and evaluating its effectiveness. Existing studies primarily focus on knowledge editing using factual triplets, which not only incur high costs for collection but also struggle to express complex facts. Furthermore, these studies are often limited in their evaluation perspectives. In this paper, we propose Eva-KELLM, a new benchmark for evaluating knowledge editing of LLMs. This benchmark includes an evaluation framework and a corresponding dataset. Under our framework, we first ask the LLM to perform knowledge editing using raw documents, which provides a more convenient and universal approach compared to using factual triplets. We then evaluate the updated LLM from multiple perspectives. In addition to assessing the effectiveness of knowledge editing and the retention of unrelated knowledge from conventional studies, we further test the LLM's ability in two aspects: 1) Reasoning with the altered knowledge, aiming for the LLM to genuinely learn the altered knowledge instead of simply memorizing it. 2) Cross-lingual knowledge transfer, where the LLM updated with raw documents in one language should be capable of handling queries from another language. To facilitate further research, we construct and release the corresponding dataset. Using this benchmark, we investigate the effectiveness of several commonly-used knowledge editing methods. Experimental results indicate that the current methods for knowledge editing using raw documents are not effective in yielding satisfactory results, particularly when it comes to reasoning with altered knowledge and cross-lingual knowledge transfer.
S3IM: Stochastic Structural SIMilarity and Its Unreasonable Effectiveness for Neural Fields
Aug 14, 2023



Recently, Neural Radiance Field (NeRF) has shown great success in rendering novel-view images of a given scene by learning an implicit representation with only posed RGB images. NeRF and relevant neural field methods (e.g., neural surface representation) typically optimize a point-wise loss and make point-wise predictions, where one data point corresponds to one pixel. Unfortunately, this line of research failed to use the collective supervision of distant pixels, although it is known that pixels in an image or scene can provide rich structural information. To the best of our knowledge, we are the first to design a nonlocal multiplex training paradigm for NeRF and relevant neural field methods via a novel Stochastic Structural SIMilarity (S3IM) loss that processes multiple data points as a whole set instead of process multiple inputs independently. Our extensive experiments demonstrate the unreasonable effectiveness of S3IM in improving NeRF and neural surface representation for nearly free. The improvements of quality metrics can be particularly significant for those relatively difficult tasks: e.g., the test MSE loss unexpectedly drops by more than 90% for TensoRF and DVGO over eight novel view synthesis tasks; a 198% F-score gain and a 64% Chamfer $L_{1}$ distance reduction for NeuS over eight surface reconstruction tasks. Moreover, S3IM is consistently robust even with sparse inputs, corrupted images, and dynamic scenes.
A Semi-Autoregressive Graph Generative Model for Dependency Graph Parsing
Jun 21, 2023



Recent years have witnessed the impressive progress in Neural Dependency Parsing. According to the different factorization approaches to the graph joint probabilities, existing parsers can be roughly divided into autoregressive and non-autoregressive patterns. The former means that the graph should be factorized into multiple sequentially dependent components, then it can be built up component by component. And the latter assumes these components to be independent so that they can be outputted in a one-shot manner. However, when treating the directed edge as an explicit dependency relationship, we discover that there is a mixture of independent and interdependent components in the dependency graph, signifying that both aforementioned models fail to precisely capture the explicit dependencies among nodes and edges. Based on this property, we design a Semi-Autoregressive Dependency Parser to generate dependency graphs via adding node groups and edge groups autoregressively while pouring out all group elements in parallel. The model gains a trade-off between non-autoregression and autoregression, which respectively suffer from the lack of target inter-dependencies and the uncertainty of graph generation orders. The experiments show the proposed parser outperforms strong baselines on Enhanced Universal Dependencies of multiple languages, especially achieving $4\%$ average promotion at graph-level accuracy. Also, the performances of model variations show the importance of specific parts.
RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction
Jun 08, 2023Semantic matching is a mainstream paradigm of zero-shot relation extraction, which matches a given input with a corresponding label description. The entities in the input should exactly match their hypernyms in the description, while the irrelevant contexts should be ignored when matching. However, general matching methods lack explicit modeling of the above matching pattern. In this work, we propose a fine-grained semantic matching method tailored for zero-shot relation extraction. Following the above matching pattern, we decompose the sentence-level similarity score into entity and context matching scores. Due to the lack of explicit annotations of the redundant components, we design a feature distillation module to adaptively identify the relation-irrelevant features and reduce their negative impact on context matching. Experimental results show that our method achieves higher matching $F_1$ score and has an inference speed 10 times faster, when compared with the state-of-the-art methods.
Actively Supervised Clustering for Open Relation Extraction
Jun 08, 2023Current clustering-based Open Relation Extraction (OpenRE) methods usually adopt a two-stage pipeline. The first stage simultaneously learns relation representations and assignments. The second stage manually labels several instances and thus names the relation for each cluster. However, unsupervised objectives struggle to optimize the model to derive accurate clustering assignments, and the number of clusters has to be supplied in advance. In this paper, we present a novel setting, named actively supervised clustering for OpenRE. Our insight lies in that clustering learning and relation labeling can be alternately performed, providing the necessary guidance for clustering without a significant increase in human effort. The key to the setting is selecting which instances to label. Instead of using classical active labeling strategies designed for fixed known classes, we propose a new strategy, which is applicable to dynamically discover clusters of unknown relations. Experimental results show that our method is able to discover almost all relational clusters in the data and improve the SOTA methods by 10.3\% and 5.2\%, on two datasets respectively.
A Graph-Guided Reasoning Approach for Open-ended Commonsense Question Answering
Mar 18, 2023Recently, end-to-end trained models for multiple-choice commonsense question answering (QA) have delivered promising results. However, such question-answering systems cannot be directly applied in real-world scenarios where answer candidates are not provided. Hence, a new benchmark challenge set for open-ended commonsense reasoning (OpenCSR) has been recently released, which contains natural science questions without any predefined choices. On the OpenCSR challenge set, many questions require implicit multi-hop reasoning and have a large decision space, reflecting the difficult nature of this task. Existing work on OpenCSR sorely focuses on improving the retrieval process, which extracts relevant factual sentences from a textual knowledge base, leaving the important and non-trivial reasoning task outside the scope. In this work, we extend the scope to include a reasoner that constructs a question-dependent open knowledge graph based on retrieved supporting facts and employs a sequential subgraph reasoning process to predict the answer. The subgraph can be seen as a concise and compact graphical explanation of the prediction. Experiments on two OpenCSR datasets show that the proposed model achieves great performance on benchmark OpenCSR datasets.
Rethinking the Structure of Stochastic Gradients: Empirical and Statistical Evidence
Dec 05, 2022



Stochastic gradients closely relate to both optimization and generalization of deep neural networks (DNNs). Some works attempted to explain the success of stochastic optimization for deep learning by the arguably heavy-tail properties of gradient noise, while other works presented theoretical and empirical evidence against the heavy-tail hypothesis on gradient noise. Unfortunately, formal statistical tests for analyzing the structure and heavy tails of stochastic gradients in deep learning are still under-explored. In this paper, we mainly make two contributions. First, we conduct formal statistical tests on the distribution of stochastic gradients and gradient noise across both parameters and iterations. Our statistical tests reveal that dimension-wise gradients usually exhibit power-law heavy tails, while iteration-wise gradients and stochastic gradient noise caused by minibatch training usually do not exhibit power-law heavy tails. Second, we further discover that the covariance spectra of stochastic gradients have the power-law structures in deep learning. While previous papers believed that the anisotropic structure of stochastic gradients matters to deep learning, they did not expect the gradient covariance can have such an elegant mathematical structure. Our work challenges the existing belief and provides novel insights on the structure of stochastic gradients in deep learning.
NL2GDPR: Automatically Develop GDPR Compliant Android Application Features from Natural Language
Aug 29, 2022
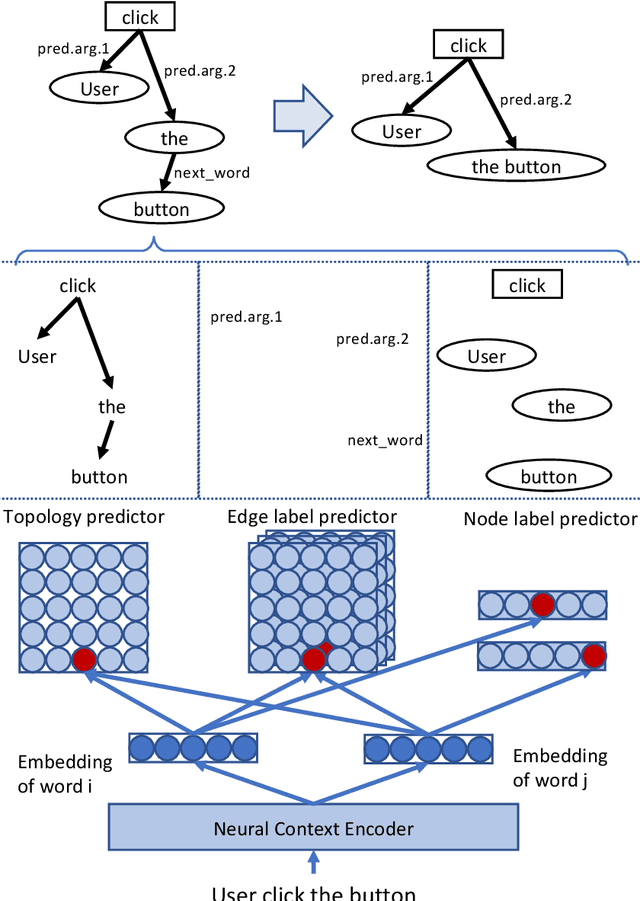

The recent privacy leakage incidences and the more strict policy regulations demand a much higher standard of compliance for companies and mobile apps. However, such obligations also impose significant challenges on app developers for complying with these regulations that contain various perspectives, activities, and roles, especially for small companies and developers who are less experienced in this matter or with limited resources. To address these hurdles, we develop an automatic tool, NL2GDPR, which can generate policies from natural language descriptions from the developer while also ensuring the app's functionalities are compliant with General Data Protection Regulation (GDPR). NL2GDPR is developed by leveraging an information extraction tool, OIA (Open Information Annotation), developed by Baidu Cognitive Computing Lab. At the core, NL2GDPR is a privacy-centric information extraction model, appended with a GDPR policy finder and a policy generator. We perform a comprehensive study to grasp the challenges in extracting privacy-centric information and generating privacy policies, while exploiting optimizations for this specific task. With NL2GDPR, we can achieve 92.9%, 95.2%, and 98.4% accuracy in correctly identifying GDPR policies related to personal data storage, process, and share types, respectively. To the best of our knowledge, NL2GDPR is the first tool that allows a developer to automatically generate GDPR compliant policies, with only the need of entering the natural language for describing the app features. Note that other non-GDPR-related features might be integrated with the generated features to build a complex app.
CGAR: Critic Guided Action Redistribution in Reinforcement Leaning
Jun 23, 2022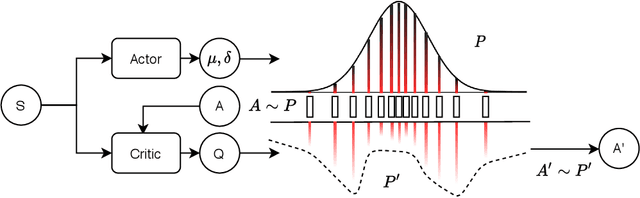
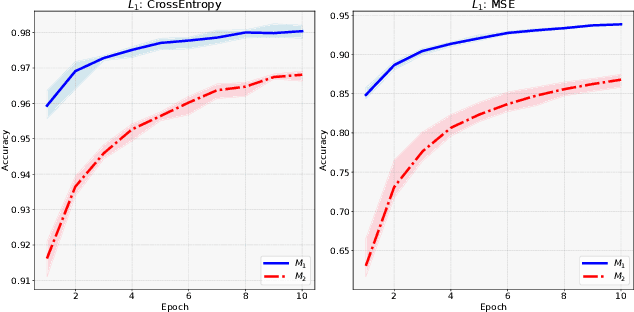
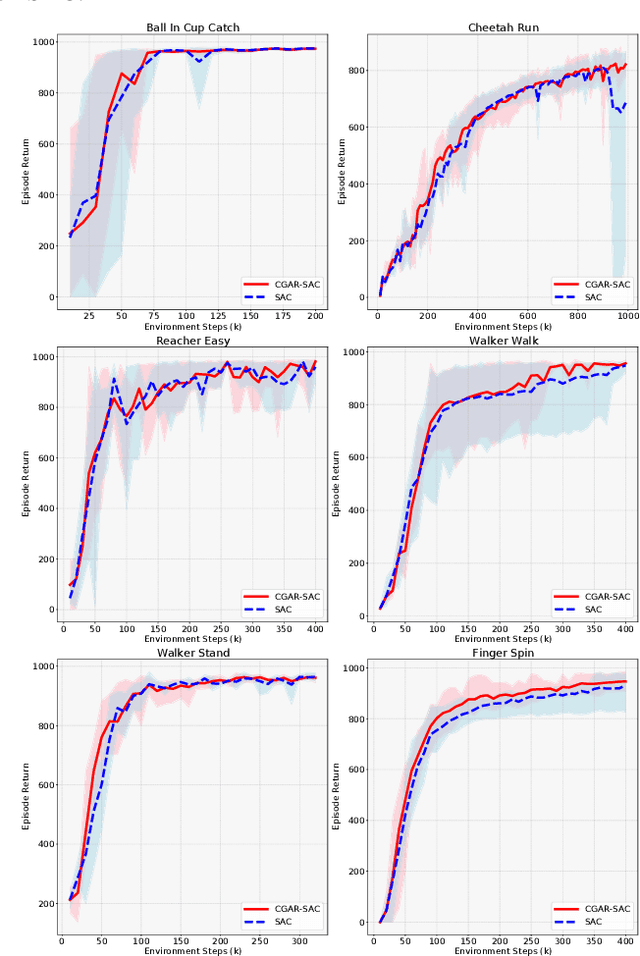

Training a game-playing reinforcement learning agent requires multiple interactions with the environment. Ignorant random exploration may cause a waste of time and resources. It's essential to alleviate such waste. As discussed in this paper, under the settings of the off-policy actor critic algorithms, we demonstrate that the critic can bring more expected discounted rewards than or at least equal to the actor. Thus, the Q value predicted by the critic is a better signal to redistribute the action originally sampled from the policy distribution predicted by the actor. This paper introduces the novel Critic Guided Action Redistribution (CGAR) algorithm and tests it on the OpenAI MuJoCo tasks. The experimental results demonstrate that our method improves the sample efficiency and achieves state-of-the-art performance. Our code can be found at https://github.com/tairanhuang/CGAR.