 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Subspace Evoking for Efficient Neural Architecture Search
Oct 31, 2022



Neural Architecture Search (NAS) aims to automatically find effective architectures from a predefined search space. However, the search space is often extremely large. As a result, directly searching in such a large search space is non-trivial and also very time-consuming. To address the above issues, in each search step, we seek to limit the search space to a small but effective subspace to boost both the search performance and search efficiency. To this end, we propose a novel Neural Architecture Search method via Automatic Subspace Evoking (ASE-NAS) that finds promising architectures in automatically evoked subspaces. Specifically, we first perform a global search, i.e., automatic subspace evoking, to evoke/find a good subspace from a set of candidates. Then, we perform a local search within the evoked subspace to find an effective architecture. More critically, we further boost search performance by taking well-designed/searched architectures as the initial candidate subspaces. Extensive experiments show that our ASE-NAS not only greatly reduces the search cost but also finds better architectures than state-of-the-art methods in various benchmark search spaces.
Weakly-Supervised Multi-Granularity Map Learning for Vision-and-Language Navigation
Oct 14, 2022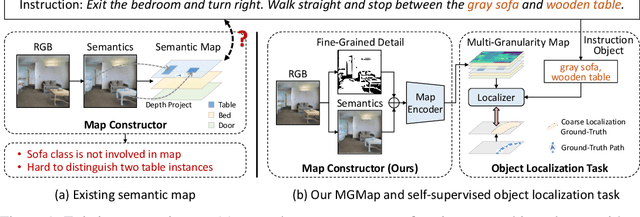
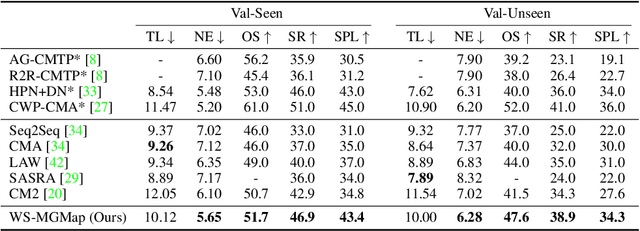
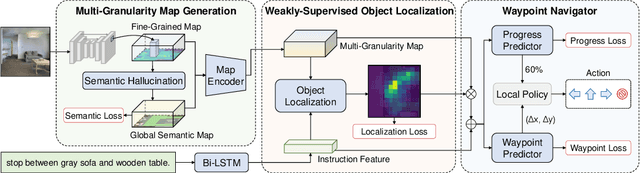
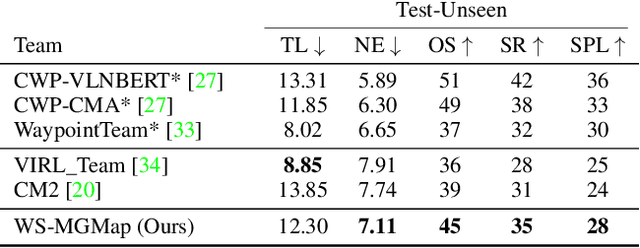
We address a practical yet challenging problem of training robot agents to navigate in an environment following a path described by some language instructions. The instructions often contain descriptions of objects in the environment. To achieve accurate and efficient navigation, it is critical to build a map that accurately represents both spatial location and the semantic information of the environment objects. However, enabling a robot to build a map that well represents the environment is extremely challenging as the environment often involves diverse objects with various attributes. In this paper, we propose a multi-granularity map, which contains both object fine-grained details (e.g., color, texture) and semantic classes, to represent objects more comprehensively. Moreover, we propose a weakly-supervised auxiliary task, which requires the agent to localize instruction-relevant objects on the map. Through this task, the agent not only learns to localize the instruction-relevant objects for navigation but also is encouraged to learn a better map representation that reveals object information. We then feed the learned map and instruction to a waypoint predictor to determine the next navigation goal. Experimental results show our method outperforms the state-of-the-art by 4.0% and 4.6% w.r.t. success rate both in seen and unseen environments, respectively on VLN-CE dataset. Code is available at https://github.com/PeihaoChen/WS-MGMap.
Pareto-aware Neural Architecture Generation for Diverse Computational Budgets
Oct 14, 2022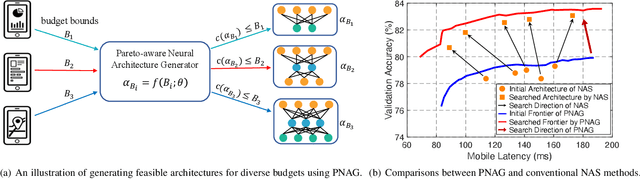
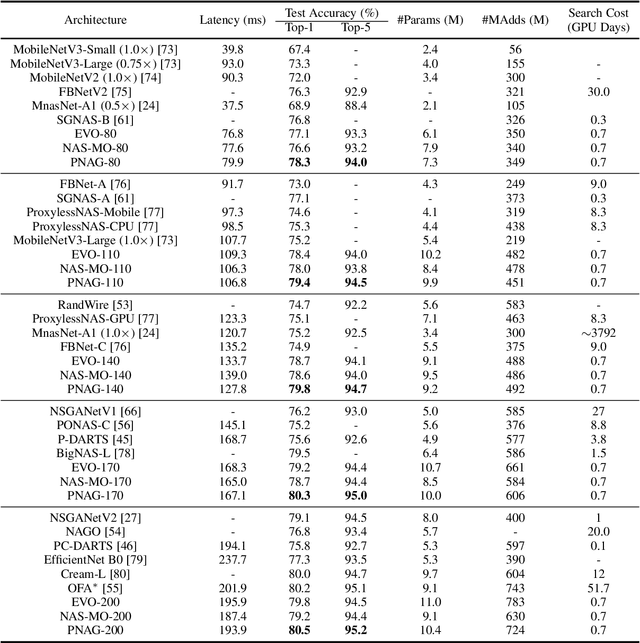
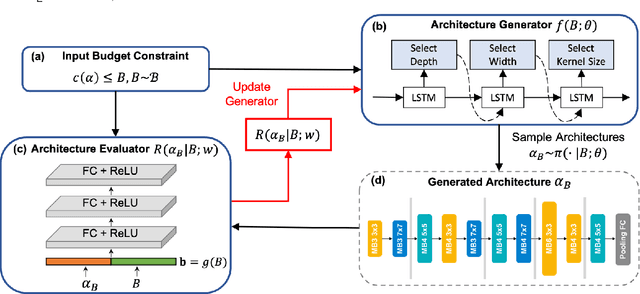
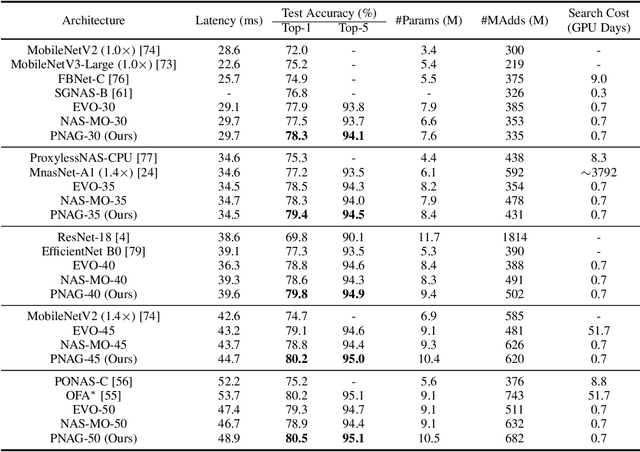
Designing feasible and effective architectures under diverse computational budgets, incurred by different applications/devices, is essential for deploying deep models in real-world applications. To achieve this goal, existing methods often perform an independent architecture search process for each target budget, which is very inefficient yet unnecessary. More critically, these independent search processes cannot share their learned knowledge (i.e., the distribution of good architectures) with each other and thus often result in limited search results. To address these issues, we propose a Pareto-aware Neural Architecture Generator (PNAG) which only needs to be trained once and dynamically produces the Pareto optimal architecture for any given budget via inference. To train our PNAG, we learn the whole Pareto frontier by jointly finding multiple Pareto optimal architectures under diverse budgets. Such a joint search algorithm not only greatly reduces the overall search cost but also improves the search results. Extensive experiments on three hardware platforms (i.e., mobile device, CPU, and GPU) show the superiority of our method over existing methods.
Learning Active Camera for Multi-Object Navigation
Oct 14, 2022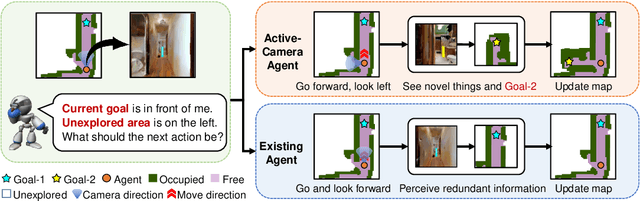
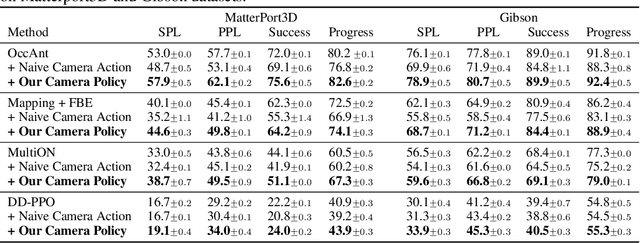
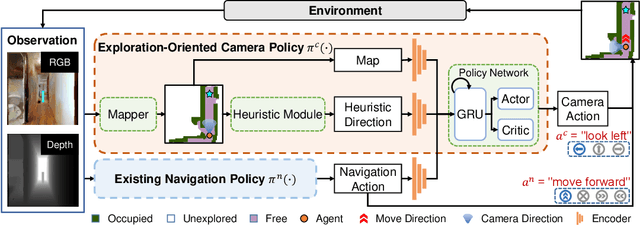
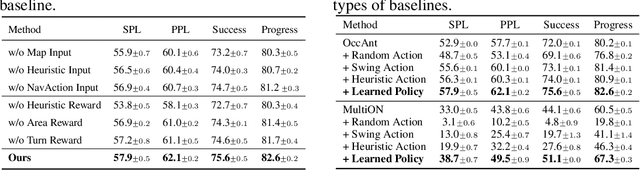
Getting robots to navigate to multiple objects autonomously is essential yet difficult in robot applications. One of the key challenges is how to explore environments efficiently with camera sensors only. Existing navigation methods mainly focus on fixed cameras and few attempts have been made to navigate with active cameras. As a result, the agent may take a very long time to perceive the environment due to limited camera scope. In contrast, humans typically gain a larger field of view by looking around for a better perception of the environment. How to make robots perceive the environment as efficiently as humans is a fundamental problem in robotics. In this paper, we consider navigating to multiple objects more efficiently with active cameras. Specifically, we cast moving camera to a Markov Decision Process and reformulate the active camera problem as a reinforcement learning problem. However, we have to address two new challenges: 1) how to learn a good camera policy in complex environments and 2) how to coordinate it with the navigation policy. To address these, we carefully design a reward function to encourage the agent to explore more areas by moving camera actively. Moreover, we exploit human experience to infer a rule-based camera action to guide the learning process. Last, to better coordinate two kinds of policies, the camera policy takes navigation actions into account when making camera moving decisions. Experimental results show our camera policy consistently improves the performance of multi-object navigation over four baselines on two datasets.
M$^3$Video: Masked Motion Modeling for Self-Supervised Video Representation Learning
Oct 12, 2022
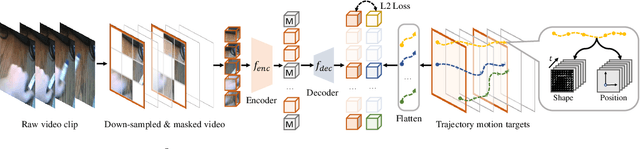

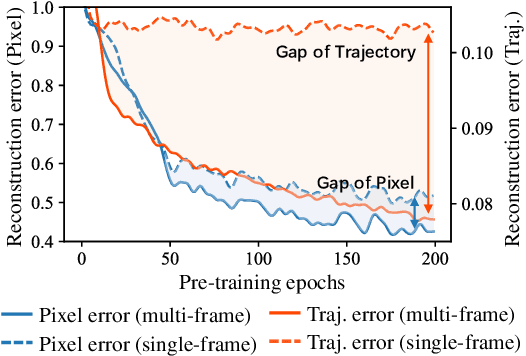
We study self-supervised video representation learning that seeks to learn video features from unlabeled videos, which is widely used for video analysis as labeling videos is labor-intensive. Current methods often mask some video regions and then train a model to reconstruct spatial information in these regions (e.g., original pixels). However, the model is easy to reconstruct this information by considering content in a single frame. As a result, it may neglect to learn the interactions between frames, which are critical for video analysis. In this paper, we present a new self-supervised learning task, called Masked Motion Modeling (M$^3$Video), for learning representation by enforcing the model to predict the motion of moving objects in the masked regions. To generate motion targets for this task, we track the objects using optical flow. The motion targets consist of position transitions and shape changes of the tracked objects, thus the model has to consider multiple frames comprehensively. Besides, to help the model capture fine-grained motion details, we enforce the model to predict trajectory motion targets in high temporal resolution based on a video in low temporal resolution. After pre-training using our M$^3$Video task, the model is able to anticipate fine-grained motion details even taking a sparsely sampled video as input. We conduct extensive experiments on four benchmark datasets. Remarkably, when doing pre-training with 400 epochs, we improve the accuracy from 67.6\% to 69.2\% and from 78.8\% to 79.7\% on Something-Something V2 and Kinetics-400 datasets, respectively.
Multi-Scale Multi-Target Domain Adaptation for Angle Closure Classification
Aug 25, 2022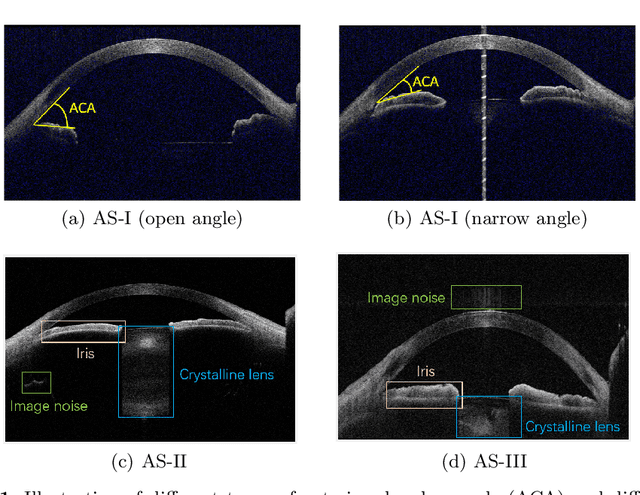
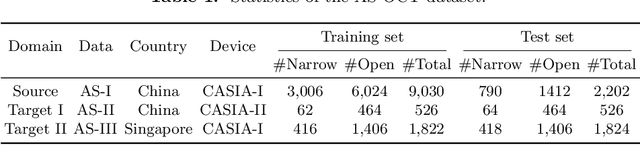
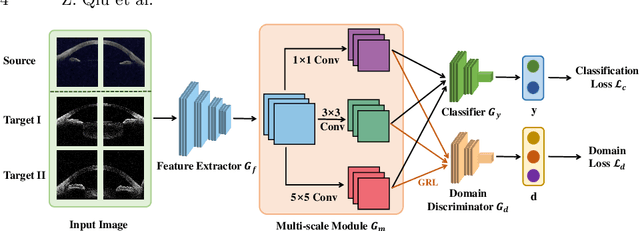
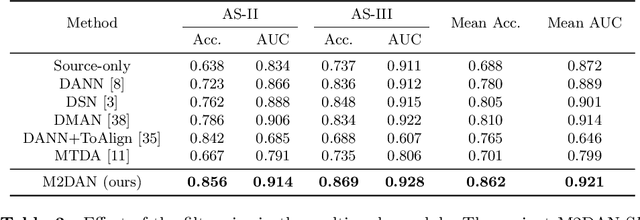
Deep learning (DL) has made significant progress in angle closure classification with anterior segment optical coherence tomography (AS-OCT) images. These AS-OCT images are often acquired by different imaging devices/conditions, which results in a vast change of underlying data distributions (called "data domains"). Moreover, due to practical labeling difficulties, some domains (e.g., devices) may not have any data labels. As a result, deep models trained on one specific domain (e.g., a specific device) are difficult to adapt to and thus may perform poorly on other domains (e.g., other devices). To address this issue, we present a multi-target domain adaptation paradigm to transfer a model trained on one labeled source domain to multiple unlabeled target domains. Specifically, we propose a novel Multi-scale Multi-target Domain Adversarial Network (M2DAN) for angle closure classification. M2DAN conducts multi-domain adversarial learning for extracting domain-invariant features and develops a multi-scale module for capturing local and global information of AS-OCT images. Based on these domain-invariant features at different scales, the deep model trained on the source domain is able to classify angle closure on multiple target domains even without any annotations in these domains. Extensive experiments on a real-world AS-OCT dataset demonstrate the effectiveness of the proposed method.
Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Aug 05, 2022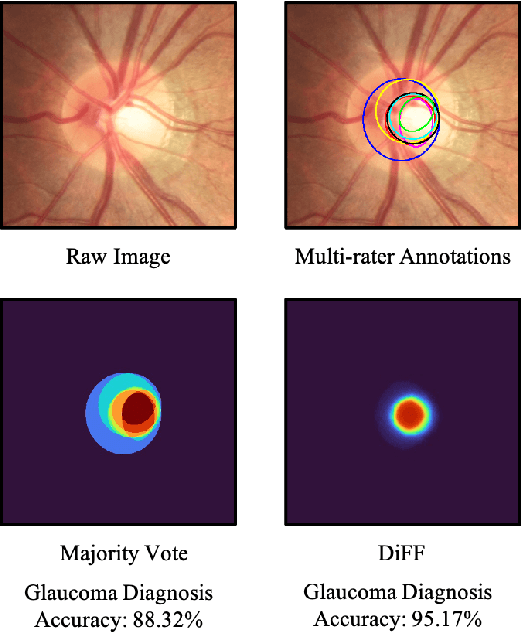
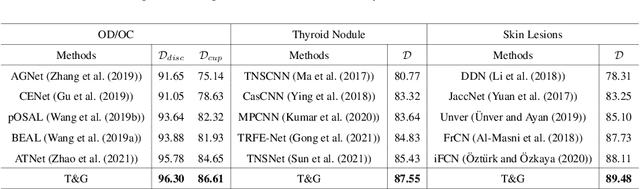
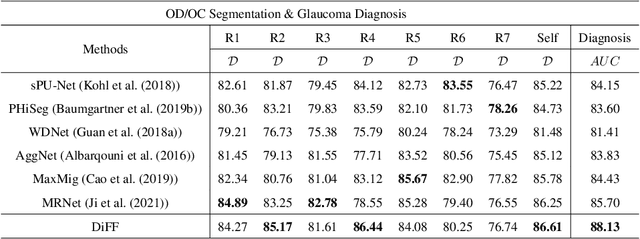
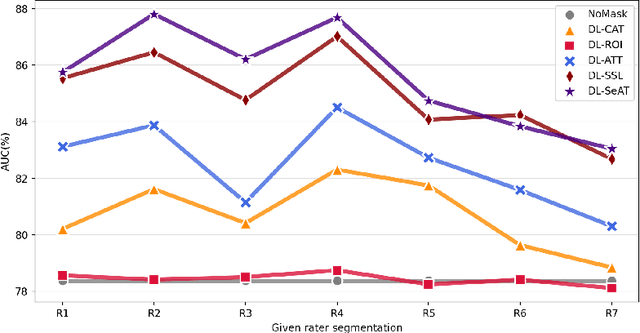
On the medical images, many of the tissues/lesions may be ambiguous. That is why the medical segmentation is typically annotated by a group of clinical experts to mitigate the personal bias. However, this clinical routine also brings new challenges to the application of machine learning algorithms. Without a definite ground-truth, it will be difficult to train and evaluate the deep learning models. When the annotations are collected from different graders, a common choice is majority vote. However such a strategy ignores the difference between the grader expertness. In this paper, we consider the task of predicting the segmentation with the calibrated inter-observer uncertainty. We note that in clinical practice, the medical image segmentation is usually used to assist the disease diagnosis. Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty. Following this idea, a framework named Diagnosis First segmentation Framework (DiFF) is proposed to estimate diagnosis-first segmentation from the raw images.Specifically, DiFF will first learn to fuse the multi-rater segmentation labels to a single ground-truth which could maximize the disease diagnosis performance. We dubbed the fused ground-truth as Diagnosis First Ground-truth (DF-GT).Then, we further propose Take and Give Modelto segment DF-GT from the raw image. We verify the effectiveness of DiFF on three different medical segmentation tasks: OD/OC segmentation on fundus images, thyroid nodule segmentation on ultrasound images, and skin lesion segmentation on dermoscopic images. Experimental results show that the proposed DiFF is able to significantly facilitate the corresponding disease diagnosis, which outperforms previous state-of-the-art multi-rater learning methods.
DAS: Densely-Anchored Sampling for Deep Metric Learning
Jul 30, 2022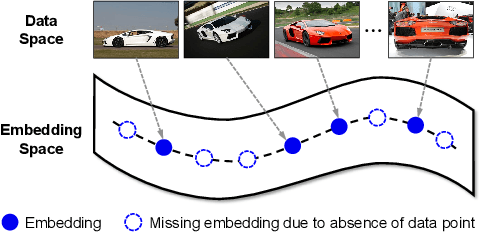
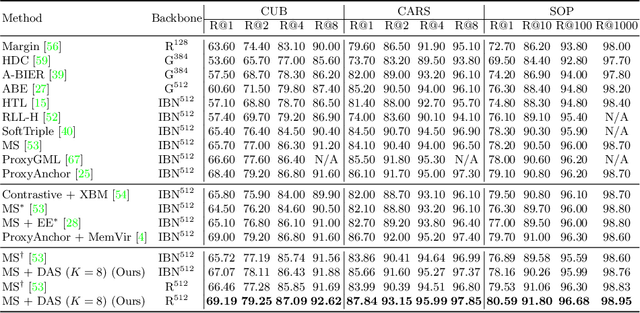
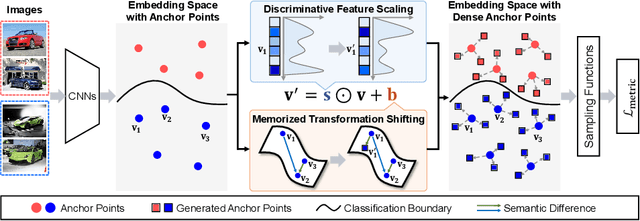
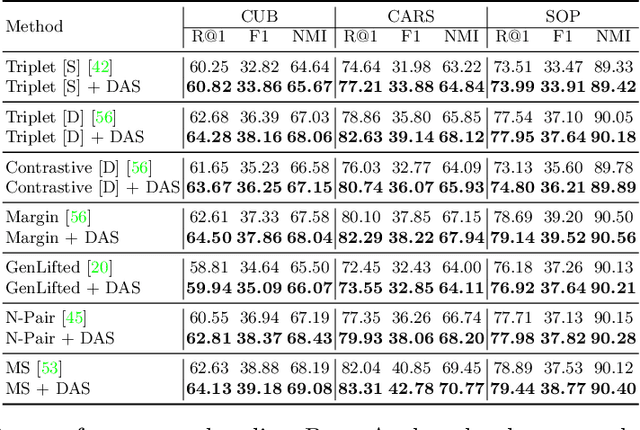
Deep Metric Learning (DML) serves to learn an embedding function to project semantically similar data into nearby embedding space and plays a vital role in many applications, such as image retrieval and face recognition. However, the performance of DML methods often highly depends on sampling methods to choose effective data from the embedding space in the training. In practice, the embeddings in the embedding space are obtained by some deep models, where the embedding space is often with barren area due to the absence of training points, resulting in so called "missing embedding" issue. This issue may impair the sample quality, which leads to degenerated DML performance. In this work, we investigate how to alleviate the "missing embedding" issue to improve the sampling quality and achieve effective DML. To this end, we propose a Densely-Anchored Sampling (DAS) scheme that considers the embedding with corresponding data point as "anchor" and exploits the anchor's nearby embedding space to densely produce embeddings without data points. Specifically, we propose to exploit the embedding space around single anchor with Discriminative Feature Scaling (DFS) and multiple anchors with Memorized Transformation Shifting (MTS). In this way, by combing the embeddings with and without data points, we are able to provide more embeddings to facilitate the sampling process thus boosting the performance of DML. Our method is effortlessly integrated into existing DML frameworks and improves them without bells and whistles. Extensive experiments on three benchmark datasets demonstrate the superiority of our method.
Prototype-Guided Continual Adaptation for Class-Incremental Unsupervised Domain Adaptation
Jul 29, 2022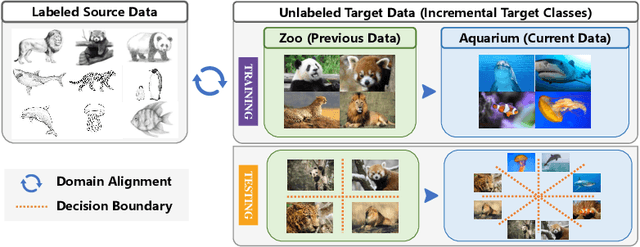

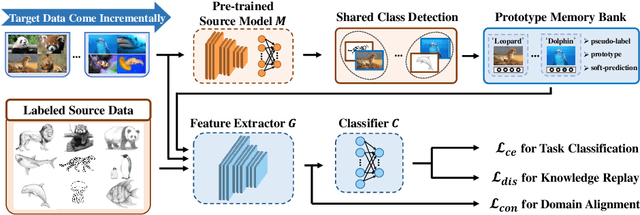

This paper studies a new, practical but challenging problem, called Class-Incremental Unsupervised Domain Adaptation (CI-UDA), where the labeled source domain contains all classes, but the classes in the unlabeled target domain increase sequentially. This problem is challenging due to two difficulties. First, source and target label sets are inconsistent at each time step, which makes it difficult to conduct accurate domain alignment. Second, previous target classes are unavailable in the current step, resulting in the forgetting of previous knowledge. To address this problem, we propose a novel Prototype-guided Continual Adaptation (ProCA) method, consisting of two solution strategies. 1) Label prototype identification: we identify target label prototypes by detecting shared classes with cumulative prediction probabilities of target samples. 2) Prototype-based alignment and replay: based on the identified label prototypes, we align both domains and enforce the model to retain previous knowledge. With these two strategies, ProCA is able to adapt the source model to a class-incremental unlabeled target domain effectively. Extensive experiments demonstrate the effectiveness and superiority of ProCA in resolving CI-UDA. The source code is available at https://github.com/Hongbin98/ProCA.git
Towards Lightweight Super-Resolution with Dual Regression Learning
Jul 21, 2022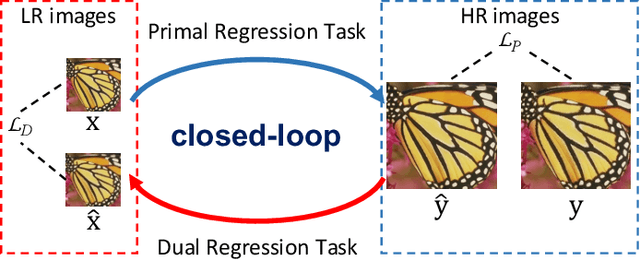
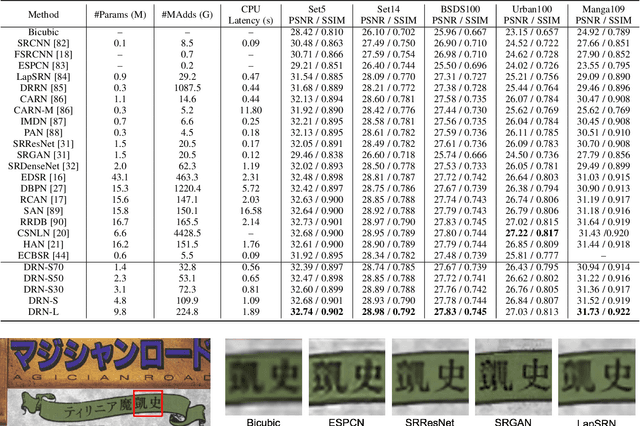
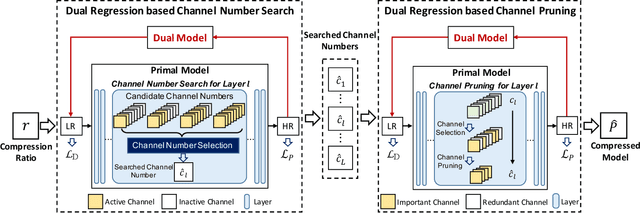
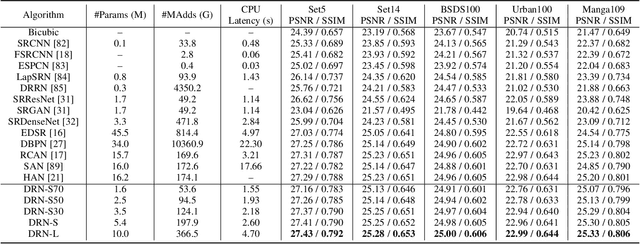
Deep neural networks have exhibited remarkable performance in image super-resolution (SR) tasks by learning a mapping from low-resolution (LR) images to high-resolution (HR) images. However, the SR problem is typically an ill-posed problem and existing methods would come with several limitations. First, the possible mapping space of SR can be extremely large since there may exist many different HR images that can be downsampled to the same LR image. As a result, it is hard to directly learn a promising SR mapping from such a large space. Second, it is often inevitable to develop very large models with extremely high computational cost to yield promising SR performance. In practice, one can use model compression techniques to obtain compact models by reducing model redundancy. Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space. To alleviate the first challenge, we propose a dual regression learning scheme to reduce the space of possible SR mappings. Specifically, in addition to the mapping from LR to HR images, we learn an additional dual regression mapping to estimate the downsampling kernel and reconstruct LR images. In this way, the dual mapping acts as a constraint to reduce the space of possible mappings. To address the second challenge, we propose a lightweight dual regression compression method to reduce model redundancy in both layer-level and channel-level based on channel pruning. Specifically, we first develop a channel number search method that minimizes the dual regression loss to determine the redundancy of each layer. Given the searched channel numbers, we further exploit the dual regression manner to evaluate the importance of channels and prune the redundant ones. Extensive experiments show the effectiveness of our method in obtaining accurate and efficient SR models.