 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022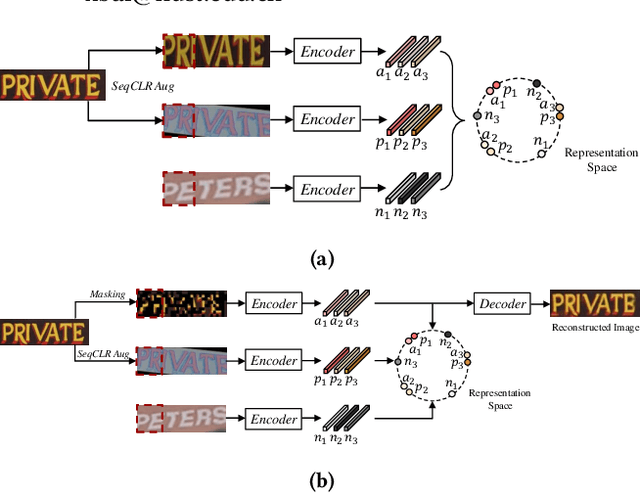
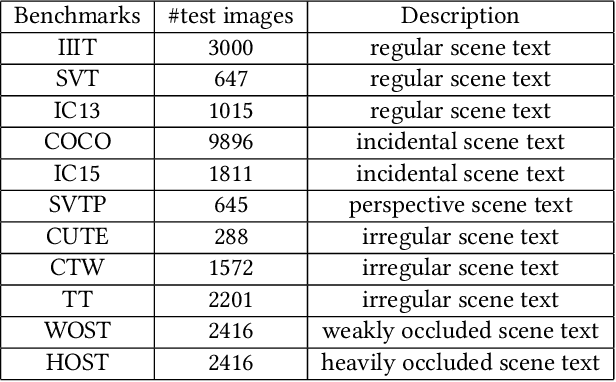
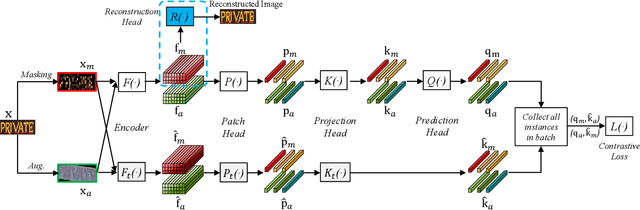
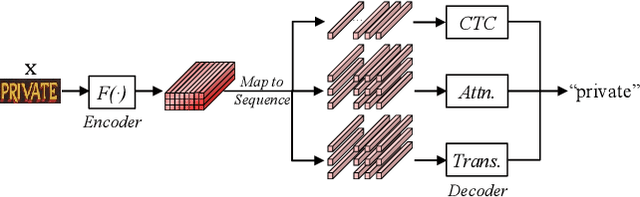
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.
Comprehensive Benchmark Datasets for Amharic Scene Text Detection and Recognition
Mar 23, 2022
Ethiopic/Amharic script is one of the oldest African writing systems, which serves at least 23 languages (e.g., Amharic, Tigrinya) in East Africa for more than 120 million people. The Amharic writing system, Abugida, has 282 syllables, 15 punctuation marks, and 20 numerals. The Amharic syllabic matrix is derived from 34 base graphemes/consonants by adding up to 12 appropriate diacritics or vocalic markers to the characters. The syllables with a common consonant or vocalic markers are likely to be visually similar and challenge text recognition tasks. In this work, we presented the first comprehensive public datasets named HUST-ART, HUST-AST, ABE, and Tana for Amharic script detection and recognition in the natural scene. We have also conducted extensive experiments to evaluate the performance of the state of art methods in detecting and recognizing Amharic scene text on our datasets. The evaluation results demonstrate the robustness of our datasets for benchmarking and its potential of promoting the development of robust Amharic script detection and recognition algorithms. Consequently, the outcome will benefit people in East Africa, including diplomats from several countries and international communities.
Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
Feb 21, 2022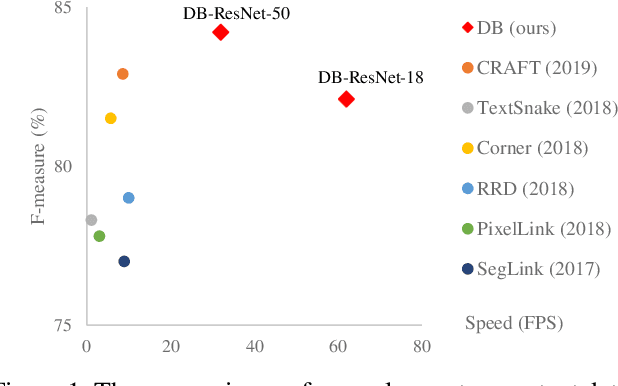
Recently, segmentation-based scene text detection methods have drawn extensive attention in the scene text detection field, because of their superiority in detecting the text instances of arbitrary shapes and extreme aspect ratios, profiting from the pixel-level descriptions. However, the vast majority of the existing segmentation-based approaches are limited to their complex post-processing algorithms and the scale robustness of their segmentation models, where the post-processing algorithms are not only isolated to the model optimization but also time-consuming and the scale robustness is usually strengthened by fusing multi-scale feature maps directly. In this paper, we propose a Differentiable Binarization (DB) module that integrates the binarization process, one of the most important steps in the post-processing procedure, into a segmentation network. Optimized along with the proposed DB module, the segmentation network can produce more accurate results, which enhances the accuracy of text detection with a simple pipeline. Furthermore, an efficient Adaptive Scale Fusion (ASF) module is proposed to improve the scale robustness by fusing features of different scales adaptively. By incorporating the proposed DB and ASF with the segmentation network, our proposed scene text detector consistently achieves state-of-the-art results, in terms of both detection accuracy and speed, on five standard benchmarks.
SGEN: Single-cell Sequencing Graph Self-supervised Embedding Network
Oct 15, 2021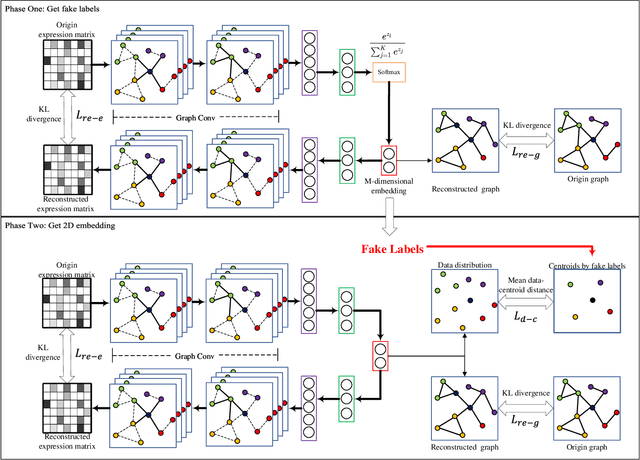
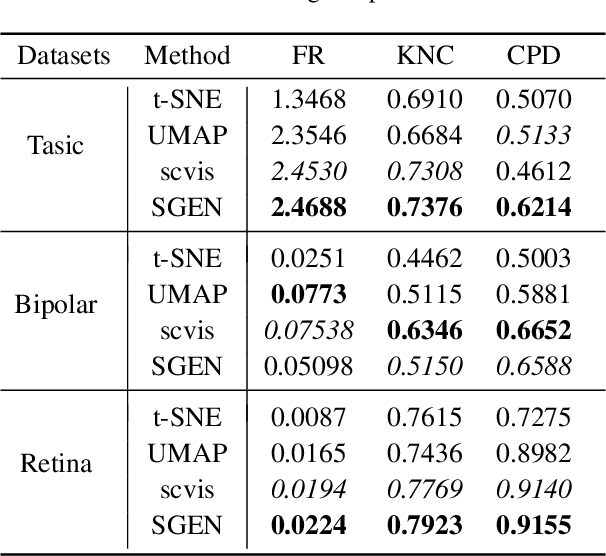
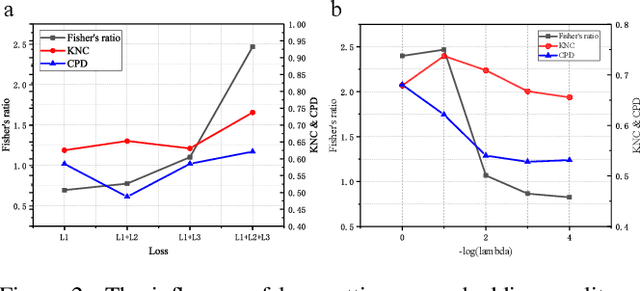
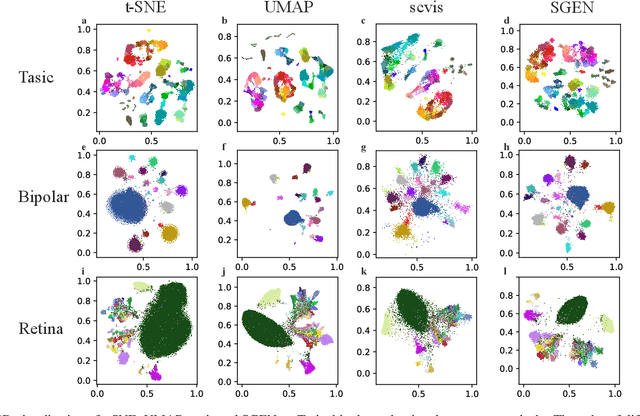
Single-cell sequencing has a significant role to explore biological processes such as embryonic development, cancer evolution, and cell differentiation. These biological properties can be presented by a two-dimensional scatter plot. However, single-cell sequencing data generally has very high dimensionality. Therefore, dimensionality reduction should be used to process the high dimensional sequencing data for 2D visualization and subsequent biological analysis. The traditional dimensionality reduction methods, which do not consider the structure characteristics of single-cell sequencing data, are difficult to reveal the data structure in the 2D representation. In this paper, we develop a 2D feature representation method based on graph convolutional networks (GCN) for the visualization of single-cell data, termed single-cell sequencing graph embedding networks (SGEN). This method constructs the graph by the similarity relationship between cells and adopts GCN to analyze the neighbor embedding information of samples, which makes the similar cell closer to each other on the 2D scatter plot. The results show SGEN achieves obvious 2D distribution and preserves the high-dimensional relationship of different cells. Meanwhile, similar cell clusters have spatial continuity rather than relying heavily on random initialization, which can reflect the trajectory of cell development in this scatter plot.
MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
Apr 05, 2021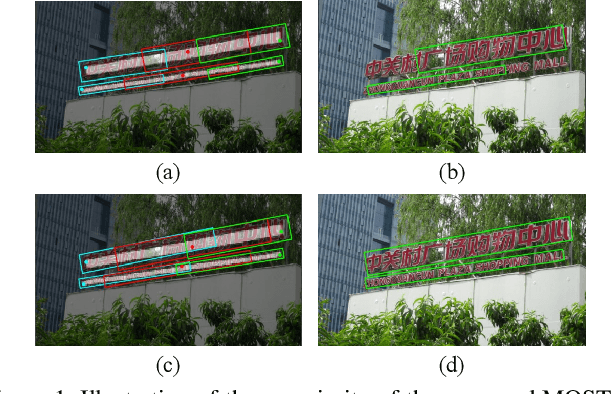
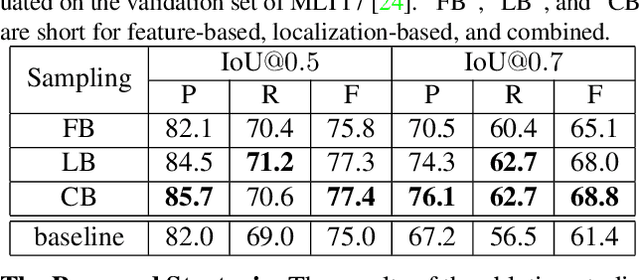
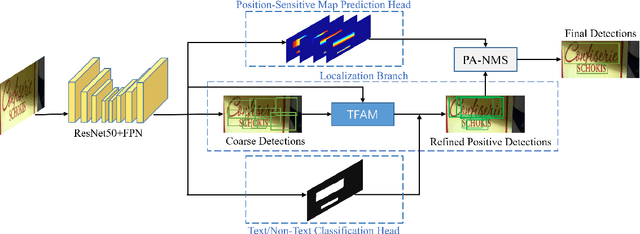
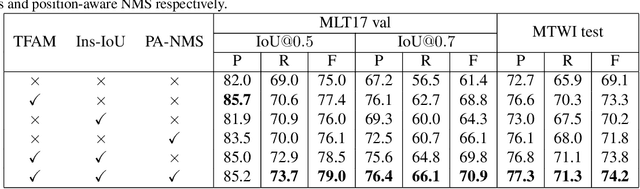
Over the past few years, the field of scene text detection has progressed rapidly that modern text detectors are able to hunt text in various challenging scenarios. However, they might still fall short when handling text instances of extreme aspect ratios and varying scales. To tackle such difficulties, we propose in this paper a new algorithm for scene text detection, which puts forward a set of strategies to significantly improve the quality of text localization. Specifically, a Text Feature Alignment Module (TFAM) is proposed to dynamically adjust the receptive fields of features based on initial raw detections; a Position-Aware Non-Maximum Suppression (PA-NMS) module is devised to selectively concentrate on reliable raw detections and exclude unreliable ones; besides, we propose an Instance-wise IoU loss for balanced training to deal with text instances of different scales. An extensive ablation study demonstrates the effectiveness and superiority of the proposed strategies. The resulting text detection system, which integrates the proposed strategies with a leading scene text detector EAST, achieves state-of-the-art or competitive performance on various standard benchmarks for text detection while keeping a fast running speed.
Scene Text Detection with Scribble Lines
Dec 10, 2020
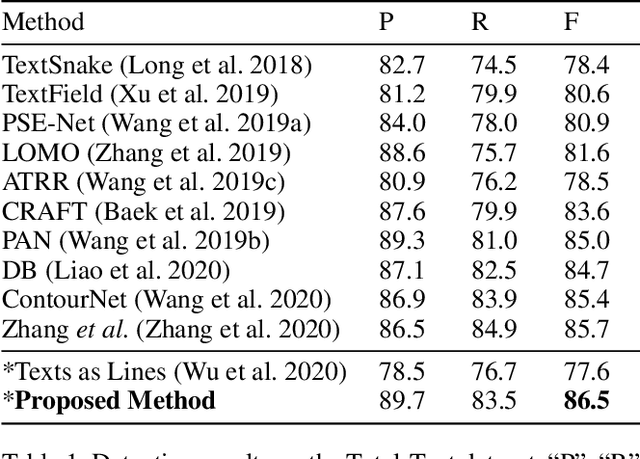
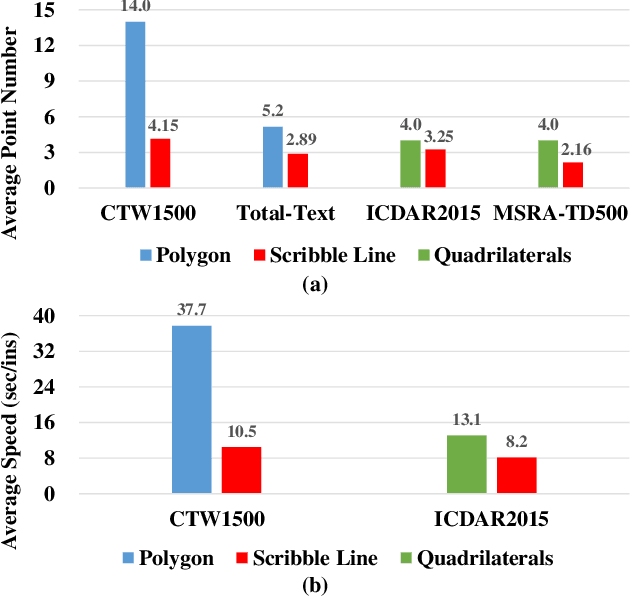
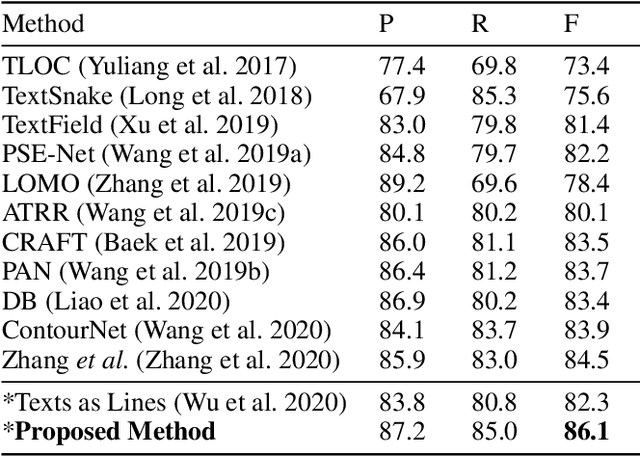
Scene text detection, which is one of the most popular topics in both academia and industry, can achieve remarkable performance with sufficient training data. However, the annotation costs of scene text detection are huge with traditional labeling methods due to the various shapes of texts. Thus, it is practical and insightful to study simpler labeling methods without harming the detection performance. In this paper, we propose to annotate the texts by scribble lines instead of polygons for text detection. It is a general labeling method for texts with various shapes and requires low labeling costs. Furthermore, a weakly-supervised scene text detection framework is proposed to use the scribble lines for text detection. The experiments on several benchmarks show that the proposed method bridges the performance gap between the weakly labeling method and the original polygon-based labeling methods, with even better performance. We will release the weak annotations of the benchmarks in our experiments and hope it will benefit the field of scene text detection to achieve better performance with simpler annotations.
Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting
Jul 18, 2020
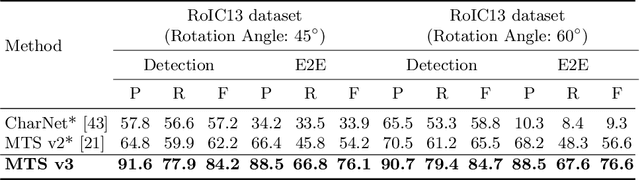

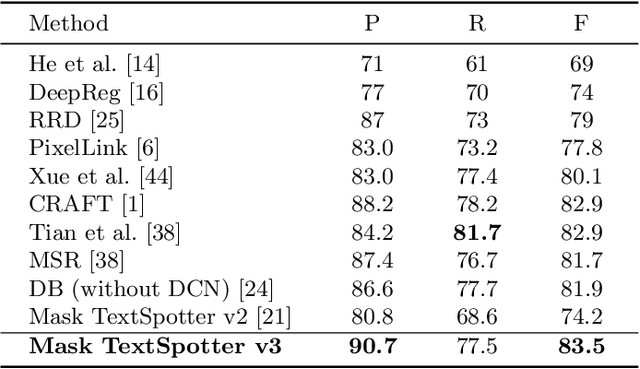
Recent end-to-end trainable methods for scene text spotting, integrating detection and recognition, showed much progress. However, most of the current arbitrary-shape scene text spotters use region proposal networks (RPN) to produce proposals. RPN relies heavily on manually designed anchors and its proposals are represented with axis-aligned rectangles. The former presents difficulties in handling text instances of extreme aspect ratios or irregular shapes, and the latter often includes multiple neighboring instances into a single proposal, in cases of densely oriented text. To tackle these problems, we propose Mask TextSpotter v3, an end-to-end trainable scene text spotter that adopts a Segmentation Proposal Network (SPN) instead of an RPN. Our SPN is anchor-free and gives accurate representations of arbitrary-shape proposals. It is therefore superior to RPN in detecting text instances of extreme aspect ratios or irregular shapes. Furthermore, the accurate proposals produced by SPN allow masked RoI features to be used for decoupling neighboring text instances. As a result, our Mask TextSpotter v3 can handle text instances of extreme aspect ratios or irregular shapes, and its recognition accuracy won't be affected by nearby text or background noise. Specifically, we outperform state-of-the-art methods by 21.9 percent on the Rotated ICDAR 2013 dataset (rotation robustness), 5.9 percent on the Total-Text dataset (shape robustness), and achieve state-of-the-art performance on the MSRA-TD500 dataset (aspect ratio robustness). Code is available at: https://github.com/MhLiao/MaskTextSpotterV3
ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard
Dec 20, 2019


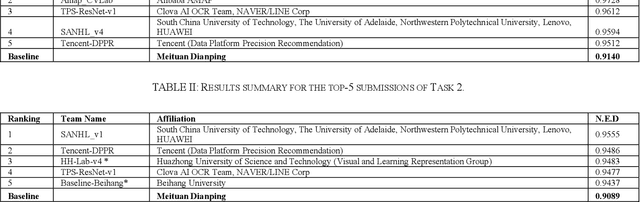
Chinese scene text reading is one of the most challenging problems in computer vision and has attracted great interest. Different from English text, Chinese has more than 6000 commonly used characters and Chinesecharacters can be arranged in various layouts with numerous fonts. The Chinese signboards in street view are a good choice for Chinese scene text images since they have different backgrounds, fonts and layouts. We organized a competition called ICDAR2019-ReCTS, which mainly focuses on reading Chinese text on signboard. This report presents the final results of the competition. A large-scale dataset of 25,000 annotated signboard images, in which all the text lines and characters are annotated with locations and transcriptions, were released. Four tasks, namely character recognition, text line recognition, text line detection and end-to-end recognition were set up. Besides, considering the Chinese text ambiguity issue, we proposed a multi ground truth (multi-GT) evaluation method to make evaluation fairer. The competition started on March 1, 2019 and ended on April 30, 2019. 262 submissions from 46 teams are received. Most of the participants come from universities, research institutes, and tech companies in China. There are also some participants from the United States, Australia, Singapore, and Korea. 21 teams submit results for Task 1, 23 teams submit results for Task 2, 24 teams submit results for Task 3, and 13 teams submit results for Task 4. The official website for the competition is http://rrc.cvc.uab.es/?ch=12.
Real-time Scene Text Detection with Differentiable Binarization
Dec 03, 2019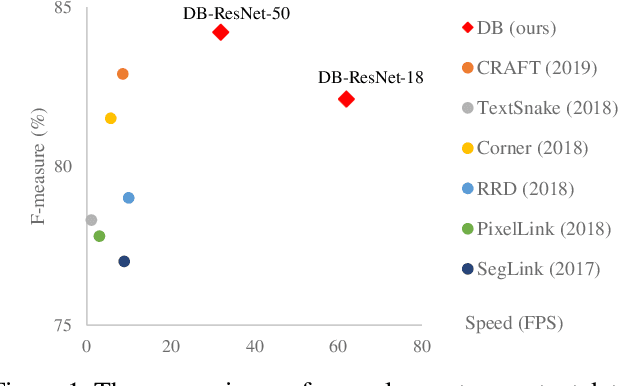
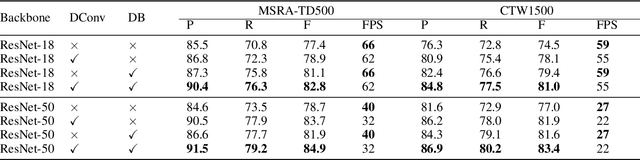
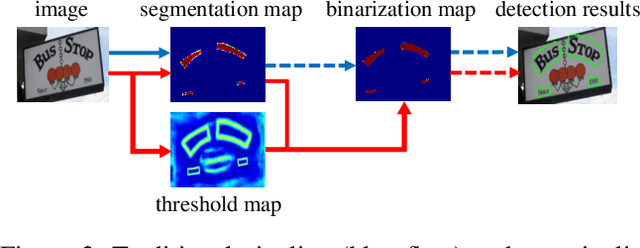
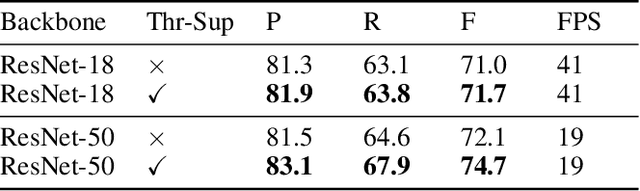
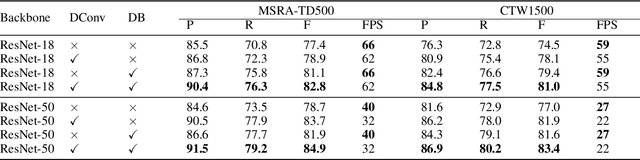
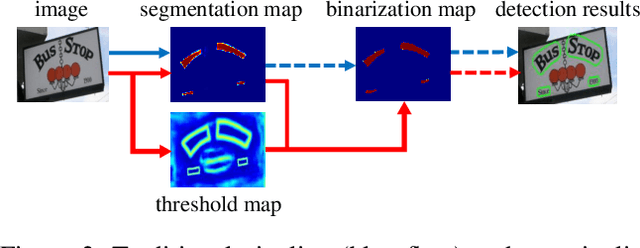
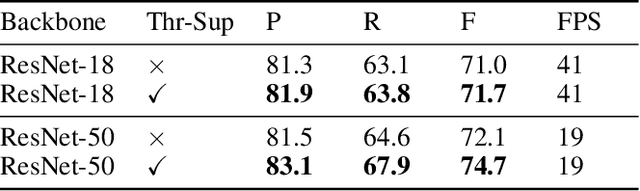
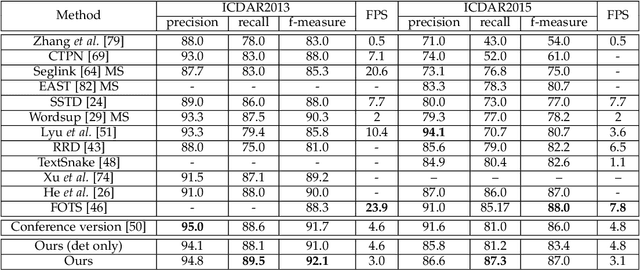
Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. In this paper, we propose a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, we validate the performance improvements of DB on five benchmark datasets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. In particular, with a light-weight backbone, the performance improvements by DB are significant so that we can look for an ideal tradeoff between detection accuracy and efficiency. Specifically, with a backbone of ResNet-18, our detector achieves an F-measure of 82.8, running at 62 FPS, on the MSRA-TD500 dataset. Code is available at: https://github.com/MhLiao/DB
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
Aug 22, 2019
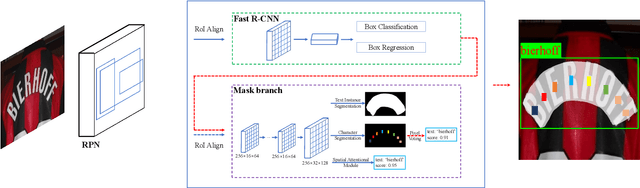
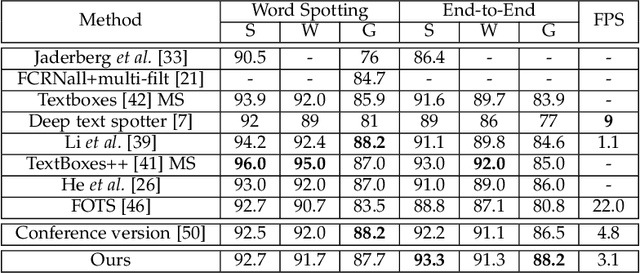
Unifying text detection and text recognition in an end-to-end training fashion has become a new trend for reading text in the wild, as these two tasks are highly relevant and complementary. In this paper, we investigate the problem of scene text spotting, which aims at simultaneous text detection and recognition in natural images. An end-to-end trainable neural network named as Mask TextSpotter is presented. Different from the previous text spotters that follow the pipeline consisting of a proposal generation network and a sequence-to-sequence recognition network, Mask TextSpotter enjoys a simple and smooth end-to-end learning procedure, in which both detection and recognition can be achieved directly from two-dimensional space via semantic segmentation. Further, a spatial attention module is proposed to enhance the performance and universality. Benefiting from the proposed two-dimensional representation on both detection and recognition, it easily handles text instances of irregular shapes, for instance, curved text. We evaluate it on four English datasets and one multi-language dataset, achieving consistently superior performance over state-of-the-art methods in both detection and end-to-end text recognition tasks. Moreover, we further investigate the recognition module of our method separately, which significantly outperforms state-of-the-art methods on both regular and irregular text datasets for scene text recognition.