 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
SAVVY: Spatial Awareness via Audio-Visual LLMs through Seeing and Hearing
Jun 04, 20253D spatial reasoning in dynamic, audio-visual environments is a cornerstone of human cognition yet remains largely unexplored by existing Audio-Visual Large Language Models (AV-LLMs) and benchmarks, which predominantly focus on static or 2D scenes. We introduce SAVVY-Bench, the first benchmark for 3D spatial reasoning in dynamic scenes with synchronized spatial audio. SAVVY-Bench is comprised of thousands of relationships involving static and moving objects, and requires fine-grained temporal grounding, consistent 3D localization, and multi-modal annotation. To tackle this challenge, we propose SAVVY, a novel training-free reasoning pipeline that consists of two stages: (i) Egocentric Spatial Tracks Estimation, which leverages AV-LLMs as well as other audio-visual methods to track the trajectories of key objects related to the query using both visual and spatial audio cues, and (ii) Dynamic Global Map Construction, which aggregates multi-modal queried object trajectories and converts them into a unified global dynamic map. Using the constructed map, a final QA answer is obtained through a coordinate transformation that aligns the global map with the queried viewpoint. Empirical evaluation demonstrates that SAVVY substantially enhances performance of state-of-the-art AV-LLMs, setting a new standard and stage for approaching dynamic 3D spatial reasoning in AV-LLMs.
SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding
Apr 08, 2025We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
Brain-to-Text Benchmark '24: Lessons Learned
Dec 23, 2024

Speech brain-computer interfaces aim to decipher what a person is trying to say from neural activity alone, restoring communication to people with paralysis who have lost the ability to speak intelligibly. The Brain-to-Text Benchmark '24 and associated competition was created to foster the advancement of decoding algorithms that convert neural activity to text. Here, we summarize the lessons learned from the competition ending on June 1, 2024 (the top 4 entrants also presented their experiences in a recorded webinar). The largest improvements in accuracy were achieved using an ensembling approach, where the output of multiple independent decoders was merged using a fine-tuned large language model (an approach used by all 3 top entrants). Performance gains were also found by improving how the baseline recurrent neural network (RNN) model was trained, including by optimizing learning rate scheduling and by using a diphone training objective. Improving upon the model architecture itself proved more difficult, however, with attempts to use deep state space models or transformers not yet appearing to offer a benefit over the RNN baseline. The benchmark will remain open indefinitely to support further work towards increasing the accuracy of brain-to-text algorithms.
Brain-to-Text Decoding with Context-Aware Neural Representations and Large Language Models
Nov 16, 2024



Decoding attempted speech from neural activity offers a promising avenue for restoring communication abilities in individuals with speech impairments. Previous studies have focused on mapping neural activity to text using phonemes as the intermediate target. While successful, decoding neural activity directly to phonemes ignores the context dependent nature of the neural activity-to-phoneme mapping in the brain, leading to suboptimal decoding performance. In this work, we propose the use of diphone - an acoustic representation that captures the transitions between two phonemes - as the context-aware modeling target. We integrate diphones into existing phoneme decoding frameworks through a novel divide-and-conquer strategy in which we model the phoneme distribution by marginalizing over the diphone distribution. Our approach effectively leverages the enhanced context-aware representation of diphones while preserving the manageable class size of phonemes, a key factor in simplifying the subsequent phoneme-to-text conversion task. We demonstrate the effectiveness of our approach on the Brain-to-Text 2024 benchmark, where it achieves state-of-the-art Phoneme Error Rate (PER) of 15.34% compared to 16.62% PER of monophone-based decoding. When coupled with finetuned Large Language Models (LLMs), our method yields a Word Error Rate (WER) of 5.77%, significantly outperforming the 8.93% WER of the leading method in the benchmark.
TR-MOT: Multi-Object Tracking by Reference
Mar 30, 2022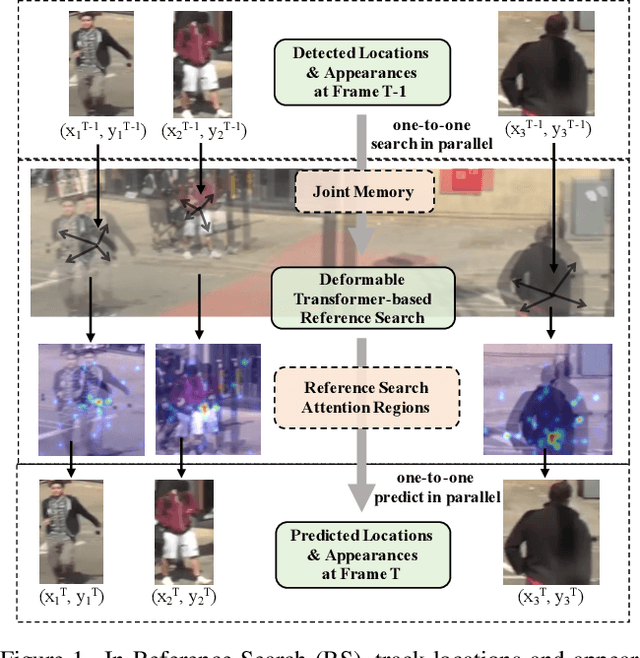
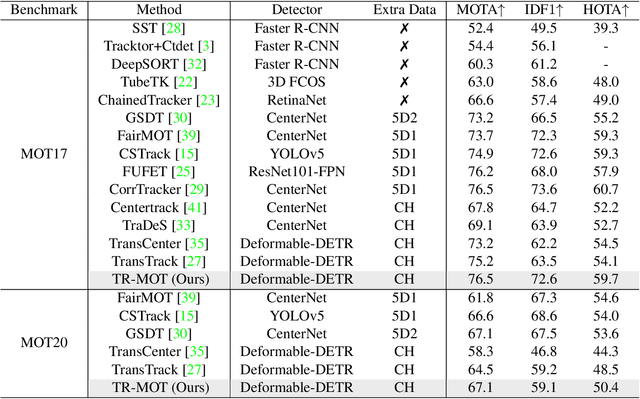
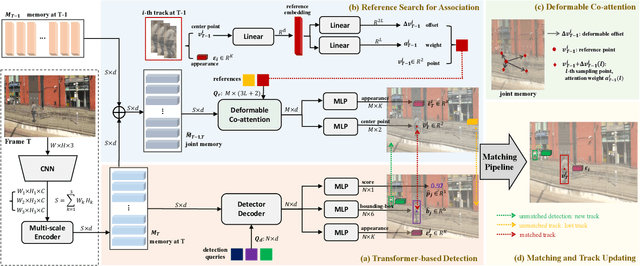
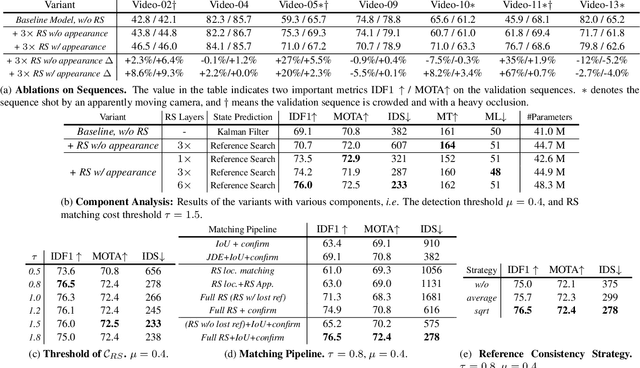
Multi-object Tracking (MOT) generally can be split into two sub-tasks, i.e., detection and association. Many previous methods follow the tracking by detection paradigm, which first obtain detections at each frame and then associate them between adjacent frames. Though with an impressive performance by utilizing a strong detector, it will degrade their detection and association performance under scenes with many occlusions and large motion if not using temporal information. In this paper, we propose a novel Reference Search (RS) module to provide a more reliable association based on the deformable transformer structure, which is natural to learn the feature alignment for each object among frames. RS takes previous detected results as references to aggregate the corresponding features from the combined features of the adjacent frames and makes a one-to-one track state prediction for each reference in parallel. Therefore, RS can attain a reliable association coping with unexpected motions by leveraging visual temporal features while maintaining the strong detection performance by decoupling from the detector. Our RS module can also be compatible with the structure of the other tracking by detection frameworks. Furthermore, we propose a joint training strategy and an effective matching pipeline for our online MOT framework with the RS module. Our method achieves competitive results on MOT17 and MOT20 datasets.
Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering
Dec 08, 2021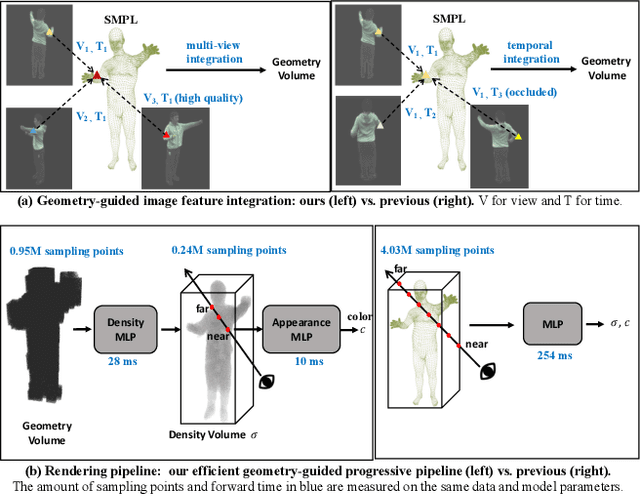
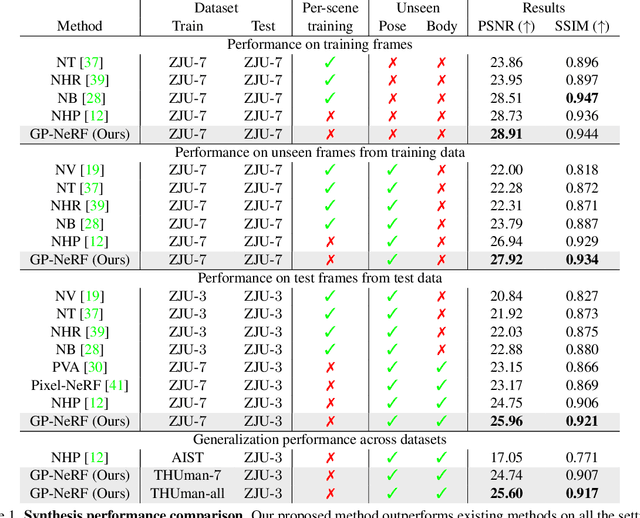
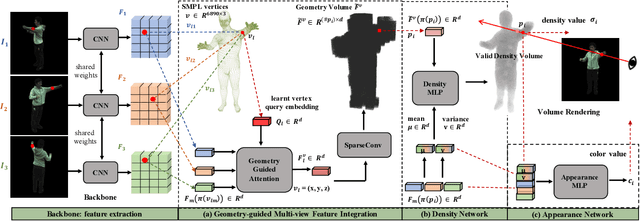
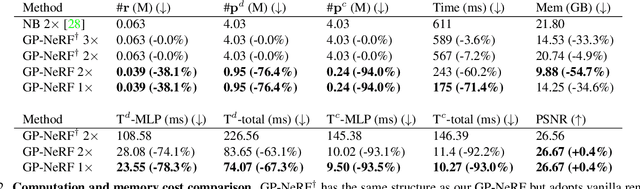
In this work we develop a generalizable and efficient Neural Radiance Field (NeRF) pipeline for high-fidelity free-viewpoint human body synthesis under settings with sparse camera views. Though existing NeRF-based methods can synthesize rather realistic details for human body, they tend to produce poor results when the input has self-occlusion, especially for unseen humans under sparse views. Moreover, these methods often require a large number of sampling points for rendering, which leads to low efficiency and limits their real-world applicability. To address these challenges, we propose a Geometry-guided Progressive NeRF~(GP-NeRF). In particular, to better tackle self-occlusion, we devise a geometry-guided multi-view feature integration approach that utilizes the estimated geometry prior to integrate the incomplete information from input views and construct a complete geometry volume for the target human body. Meanwhile, for achieving higher rendering efficiency, we introduce a geometry-guided progressive rendering pipeline, which leverages the geometric feature volume and the predicted density values to progressively reduce the number of sampling points and speed up the rendering process. Experiments on the ZJU-MoCap and THUman datasets show that our method outperforms the state-of-the-arts significantly across multiple generalization settings, while the time cost is reduced >70% via applying our efficient progressive rendering pipeline.
Reformulating HOI Detection as Adaptive Set Prediction
Mar 10, 2021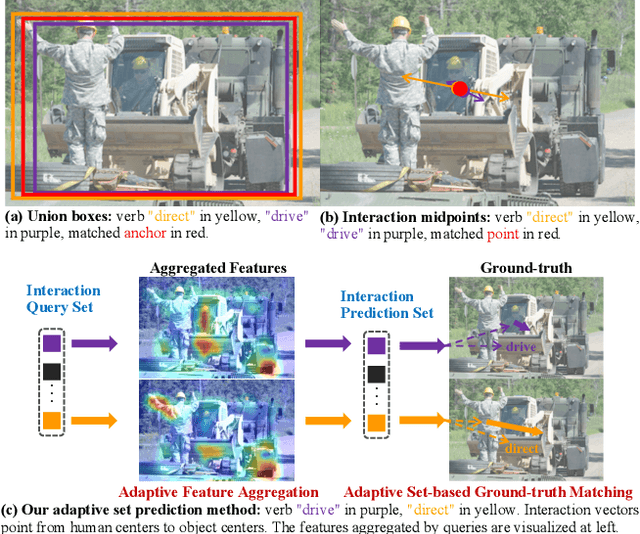
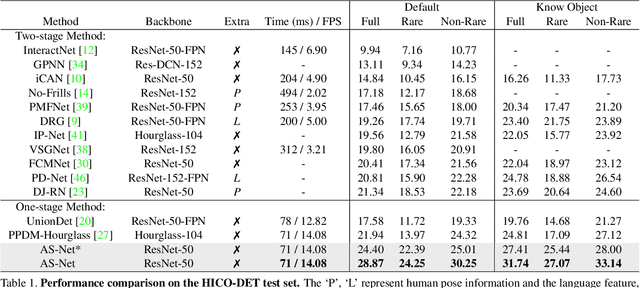
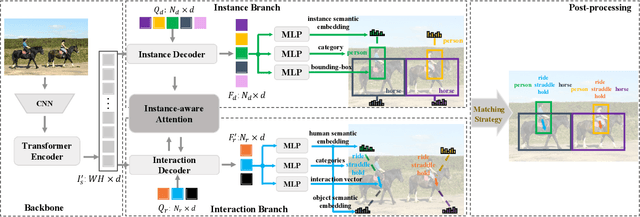
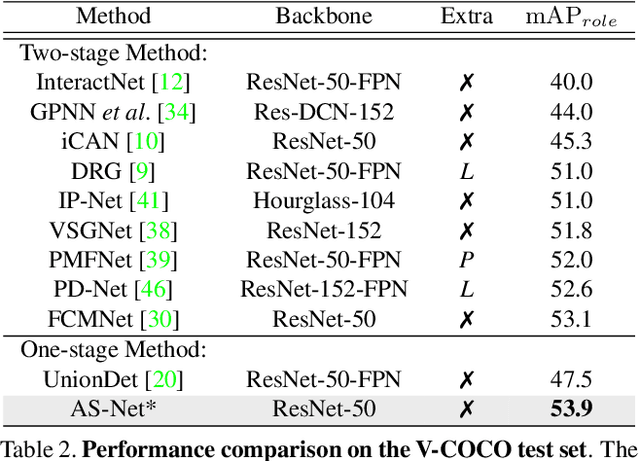
Determining which image regions to concentrate on is critical for Human-Object Interaction (HOI) detection. Conventional HOI detectors focus on either detected human and object pairs or pre-defined interaction locations, which limits learning of the effective features. In this paper, we reformulate HOI detection as an adaptive set prediction problem, with this novel formulation, we propose an Adaptive Set-based one-stage framework (AS-Net) with parallel instance and interaction branches. To attain this, we map a trainable interaction query set to an interaction prediction set with a transformer. Each query adaptively aggregates the interaction-relevant features from global contexts through multi-head co-attention. Besides, the training process is supervised adaptively by matching each ground-truth with the interaction prediction. Furthermore, we design an effective instance-aware attention module to introduce instructive features from the instance branch into the interaction branch. Our method outperforms previous state-of-the-art methods without any extra human pose and language features on three challenging HOI detection datasets. Especially, we achieve over $31\%$ relative improvement on a large scale HICO-DET dataset. Code is available at https://github.com/yoyomimi/AS-Net.