 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftAvatar: Efficient Auto-Creation of Parameterized Stylized Character on Arbitrary Avatar Engines
Jan 19, 2023The creation of a parameterized stylized character involves careful selection of numerous parameters, also known as the "avatar vectors" that can be interpreted by the avatar engine. Existing unsupervised avatar vector estimation methods that auto-create avatars for users, however, often fail to work because of the domain gap between realistic faces and stylized avatar images. To this end, we propose SwiftAvatar, a novel avatar auto-creation framework that is evidently superior to previous works. SwiftAvatar introduces dual-domain generators to create pairs of realistic faces and avatar images using shared latent codes. The latent codes can then be bridged with the avatar vectors as pairs, by performing GAN inversion on the avatar images rendered from the engine using avatar vectors. Through this way, we are able to synthesize paired data in high-quality as many as possible, consisting of avatar vectors and their corresponding realistic faces. We also propose semantic augmentation to improve the diversity of synthesis. Finally, a light-weight avatar vector estimator is trained on the synthetic pairs to implement efficient auto-creation. Our experiments demonstrate the effectiveness and efficiency of SwiftAvatar on two different avatar engines. The superiority and advantageous flexibility of SwiftAvatar are also verified in both subjective and objective evaluations.
Pre-trained Language Models can be Fully Zero-Shot Learners
Dec 14, 2022



How can we extend a pre-trained model to many language understanding tasks, without labeled or additional unlabeled data? Pre-trained language models (PLMs) have been effective for a wide range of NLP tasks. However, existing approaches either require fine-tuning on downstream labeled datasets or manually constructing proper prompts. In this paper, we propose nonparametric prompting PLM (NPPrompt) for fully zero-shot language understanding. Unlike previous methods, NPPrompt uses only pre-trained language models and does not require any labeled data or additional raw corpus for further fine-tuning, nor does it rely on humans to construct a comprehensive set of prompt label words. We evaluate NPPrompt against previous major few-shot and zero-shot learning methods on diverse NLP tasks: including text classification, text entailment, similar text retrieval, and paraphrasing. Experimental results demonstrate that our NPPrompt outperforms the previous best fully zero-shot method by big margins, with absolute gains of 12.8% in accuracy on text classification and 18.9% on the GLUE benchmark.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022



Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Sound Event Localization and Detection for Real Spatial Sound Scenes: Event-Independent Network and Data Augmentation Chains
Sep 09, 2022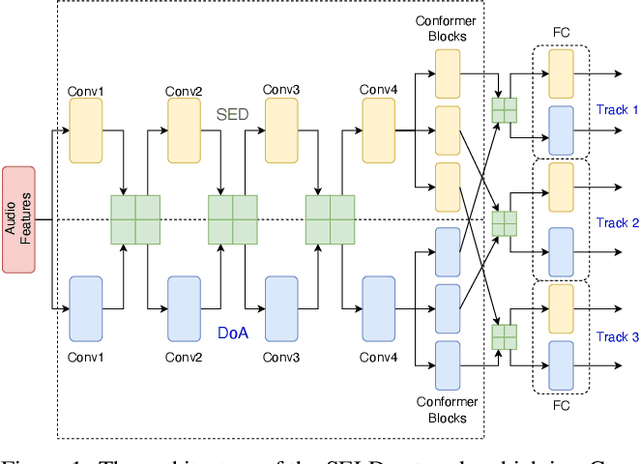

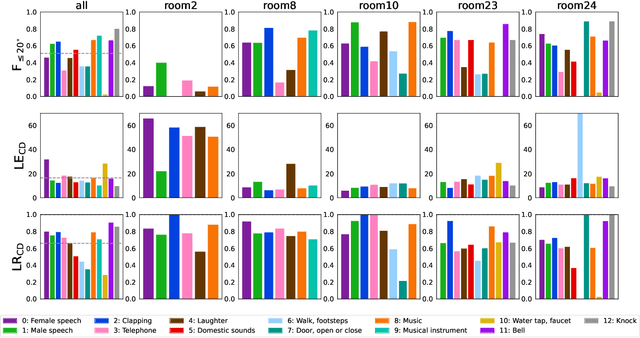
Sound event localization and detection (SELD) is a joint task of sound event detection and direction-of-arrival estimation. In DCASE 2022 Task 3, types of data transform from computationally generated spatial recordings to recordings of real-sound scenes. Our system submitted to the DCASE 2022 Task 3 is based on our previous proposed Event-Independent Network V2 (EINV2) with a novel data augmentation method. Our method employs EINV2 with a track-wise output format, permutation-invariant training, and a soft parameter-sharing strategy, to detect different sound events of the same class but in different locations. The Conformer structure is used for extending EINV2 to learn local and global features. A data augmentation method, which contains several data augmentation chains composed of stochastic combinations of several different data augmentation operations, is utilized to generalize the model. To mitigate the lack of real-scene recordings in the development dataset and the presence of sound events being unbalanced, we exploit FSD50K, AudioSet, and TAU Spatial Room Impulse Response Database (TAU-SRIR DB) to generate simulated datasets for training. We present results on the validation set of Sony-TAu Realistic Spatial Soundscapes 2022 (STARSS22) in detail. Experimental results indicate that the ability to generalize to different environments and unbalanced performance among different classes are two main challenges. We evaluate our proposed method in Task 3 of the DCASE 2022 challenge and obtain the second rank in the teams ranking. Source code is released.
A Track-Wise Ensemble Event Independent Network for Polyphonic Sound Event Localization and Detection
Mar 19, 2022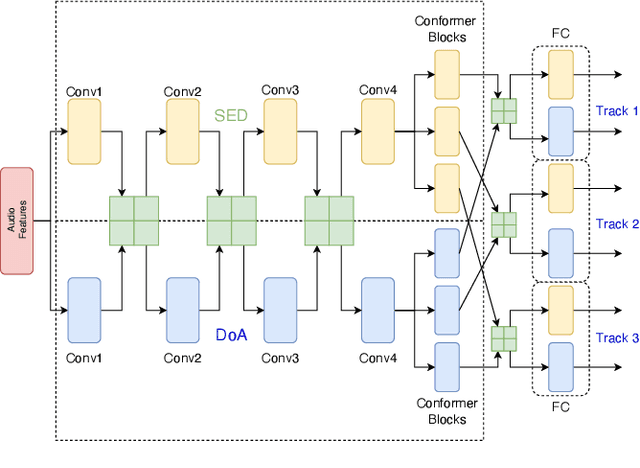

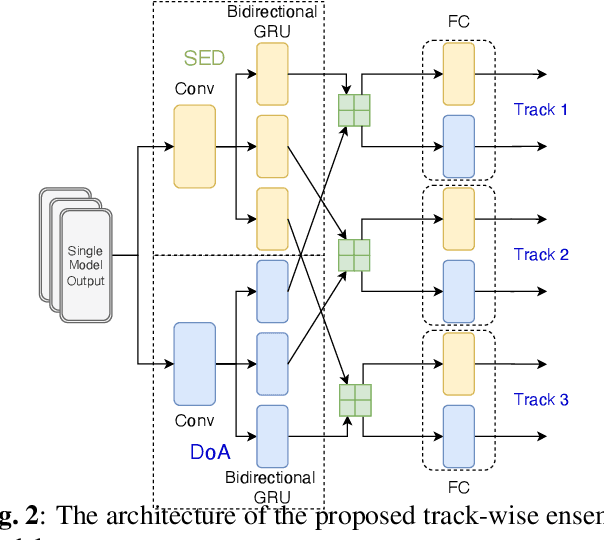
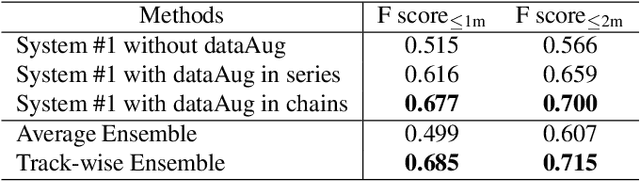
Polyphonic sound event localization and detection (SELD) aims at detecting types of sound events with corresponding temporal activities and spatial locations. In this paper, a track-wise ensemble event independent network with a novel data augmentation method is proposed. The proposed model is based on our previous proposed Event-Independent Network V2 and is extended by conformer blocks and dense blocks. The track-wise ensemble model with track-wise output format is proposed to solve an ensemble model problem for track-wise output format that track permutation may occur among different models. The data augmentation approach contains several data augmentation chains, which are composed of random combinations of several data augmentation operations. The method also utilizes log-mel spectrograms, intensity vectors, and Spatial Cues-Augmented Log-Spectrogram (SALSA) for different models. We evaluate our proposed method in the Task of the L3DAS22 challenge and obtain the top ranking solution with a location-dependent F-score to be 0.699. Source code is released.
Compressing Sentence Representation for Semantic Retrieval via Homomorphic Projective Distillation
Mar 15, 2022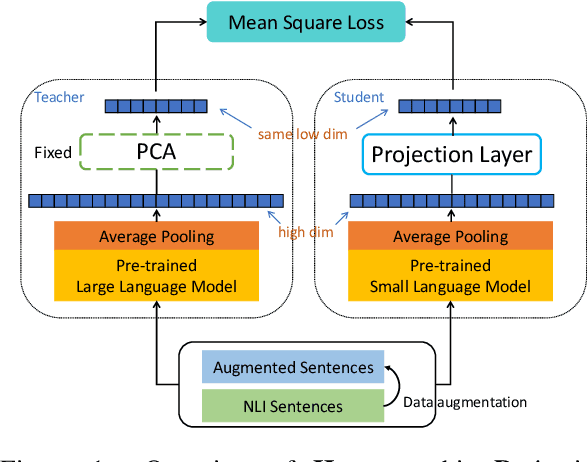
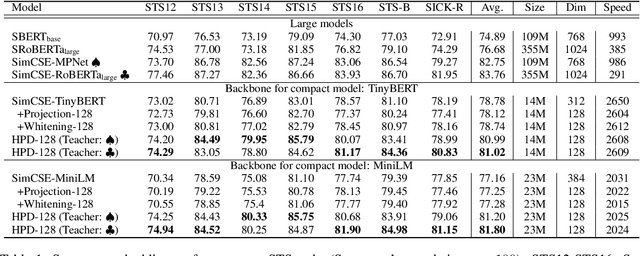
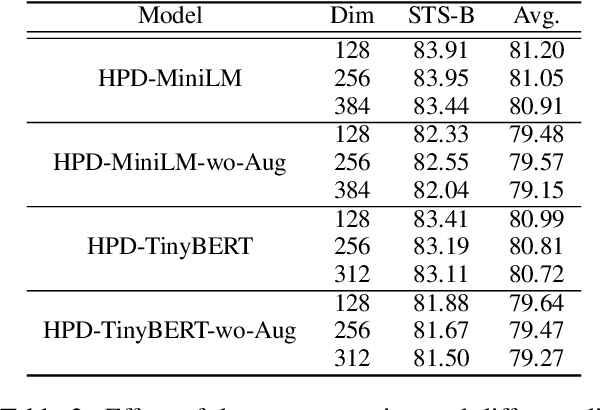
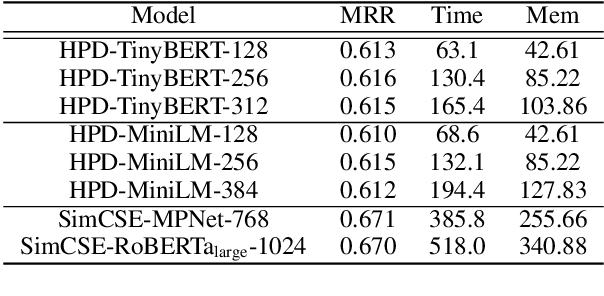
How to learn highly compact yet effective sentence representation? Pre-trained language models have been effective in many NLP tasks. However, these models are often huge and produce large sentence embeddings. Moreover, there is a big performance gap between large and small models. In this paper, we propose Homomorphic Projective Distillation (HPD) to learn compressed sentence embeddings. Our method augments a small Transformer encoder model with learnable projection layers to produce compact representations while mimicking a large pre-trained language model to retain the sentence representation quality. We evaluate our method with different model sizes on both semantic textual similarity (STS) and semantic retrieval (SR) tasks. Experiments show that our method achieves 2.7-4.5 points performance gain on STS tasks compared with previous best representations of the same size. In SR tasks, our method improves retrieval speed (8.2$\times$) and memory usage (8.0$\times$) compared with state-of-the-art large models.
Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Jan 05, 2022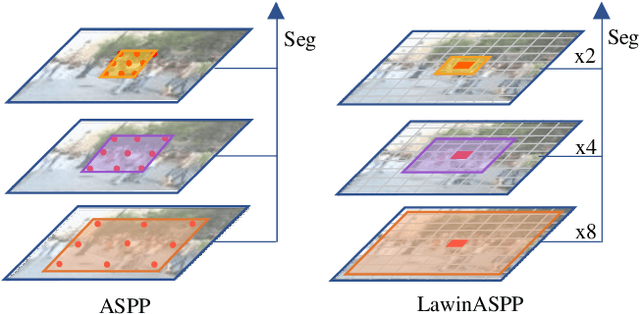
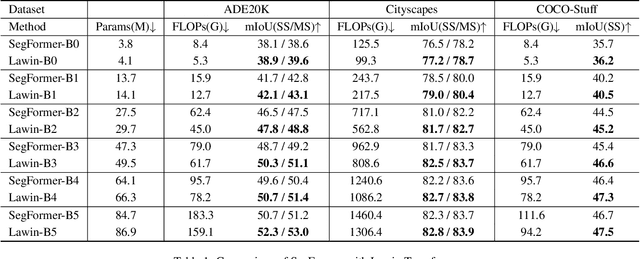
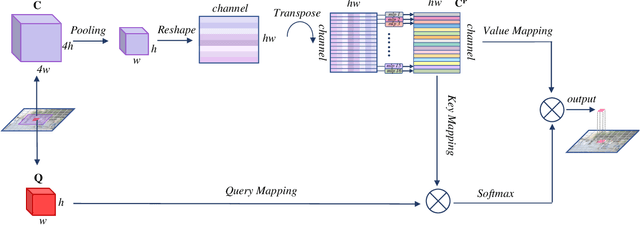
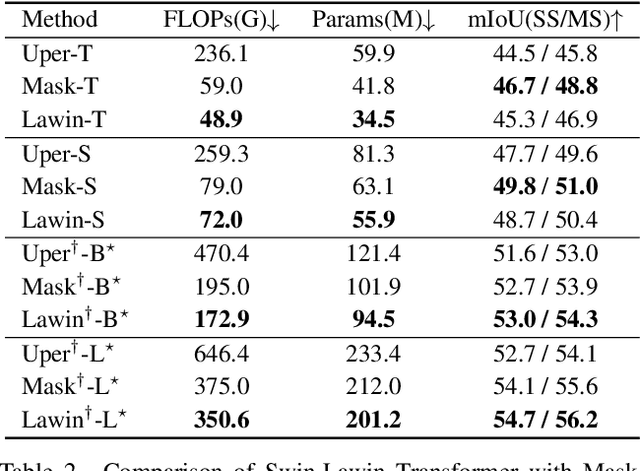
Multi-scale representations are crucial for semantic segmentation. The community has witnessed the flourish of semantic segmentation convolutional neural networks (CNN) exploiting multi-scale contextual information. Motivated by that the vision transformer (ViT) is powerful in image classification, some semantic segmentation ViTs are recently proposed, most of them attaining impressive results but at a cost of computational economy. In this paper, we succeed in introducing multi-scale representations into semantic segmentation ViT via window attention mechanism and further improves the performance and efficiency. To this end, we introduce large window attention which allows the local window to query a larger area of context window at only a little computation overhead. By regulating the ratio of the context area to the query area, we enable the large window attention to capture the contextual information at multiple scales. Moreover, the framework of spatial pyramid pooling is adopted to collaborate with the large window attention, which presents a novel decoder named large window attention spatial pyramid pooling (LawinASPP) for semantic segmentation ViT. Our resulting ViT, Lawin Transformer, is composed of an efficient hierachical vision transformer (HVT) as encoder and a LawinASPP as decoder. The empirical results demonstrate that Lawin Transformer offers an improved efficiency compared to the existing method. Lawin Transformer further sets new state-of-the-art performance on Cityscapes (84.4\% mIoU), ADE20K (56.2\% mIoU) and COCO-Stuff datasets. The code will be released at https://github.com/yan-hao-tian/lawin.
SamplingAug: On the Importance of Patch Sampling Augmentation for Single Image Super-Resolution
Nov 30, 2021With the development of Deep Neural Networks (DNNs), plenty of methods based on DNNs have been proposed for Single Image Super-Resolution (SISR). However, existing methods mostly train the DNNs on uniformly sampled LR-HR patch pairs, which makes them fail to fully exploit informative patches within the image. In this paper, we present a simple yet effective data augmentation method. We first devise a heuristic metric to evaluate the informative importance of each patch pair. In order to reduce the computational cost for all patch pairs, we further propose to optimize the calculation of our metric by integral image, achieving about two orders of magnitude speedup. The training patch pairs are sampled according to their informative importance with our method. Extensive experiments show our sampling augmentation can consistently improve the convergence and boost the performance of various SISR architectures, including EDSR, RCAN, RDN, SRCNN and ESPCN across different scaling factors (x2, x3, x4). Code is available at https://github.com/littlepure2333/SamplingAug
Overfitting the Data: Compact Neural Video Delivery via Content-aware Feature Modulation
Aug 18, 2021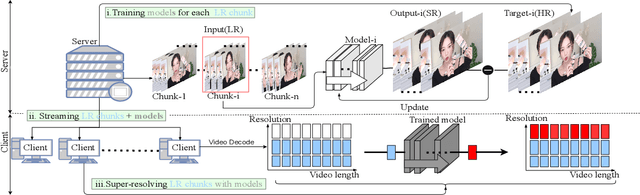
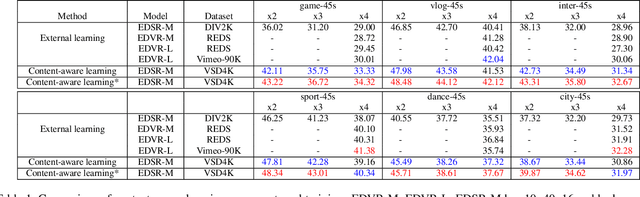

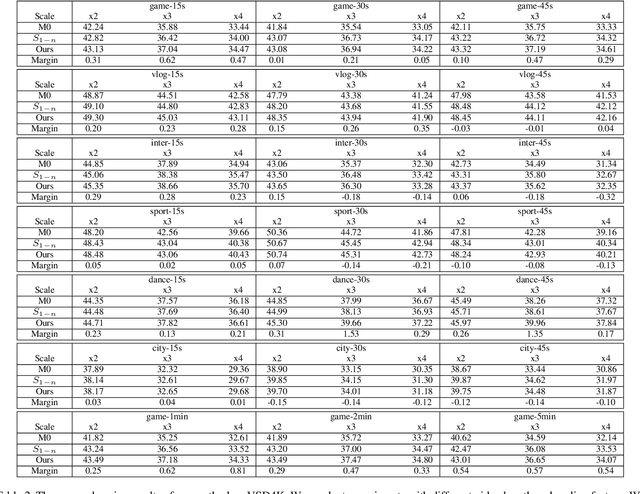
Internet video delivery has undergone a tremendous explosion of growth over the past few years. However, the quality of video delivery system greatly depends on the Internet bandwidth. Deep Neural Networks (DNNs) are utilized to improve the quality of video delivery recently. These methods divide a video into chunks, and stream LR video chunks and corresponding content-aware models to the client. The client runs the inference of models to super-resolve the LR chunks. Consequently, a large number of models are streamed in order to deliver a video. In this paper, we first carefully study the relation between models of different chunks, then we tactfully design a joint training framework along with the Content-aware Feature Modulation (CaFM) layer to compress these models for neural video delivery. {\bf With our method, each video chunk only requires less than $1\% $ of original parameters to be streamed, achieving even better SR performance.} We conduct extensive experiments across various SR backbones, video time length, and scaling factors to demonstrate the advantages of our method. Besides, our method can be also viewed as a new approach of video coding. Our primary experiments achieve better video quality compared with the commercial H.264 and H.265 standard under the same storage cost, showing the great potential of the proposed method. Code is available at:\url{https://github.com/Neural-video-delivery/CaFM-Pytorch-ICCV2021}
ConTNet: Why not use convolution and transformer at the same time?
May 10, 2021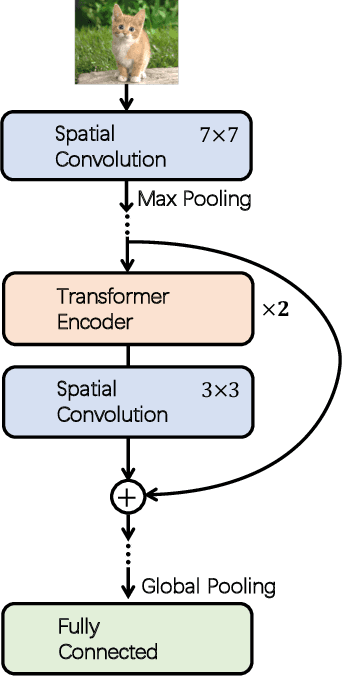
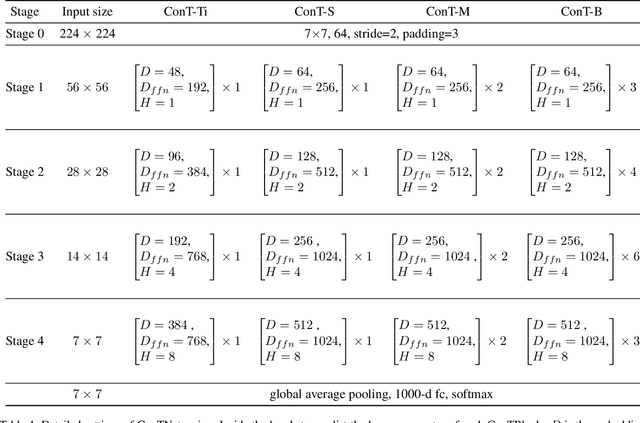

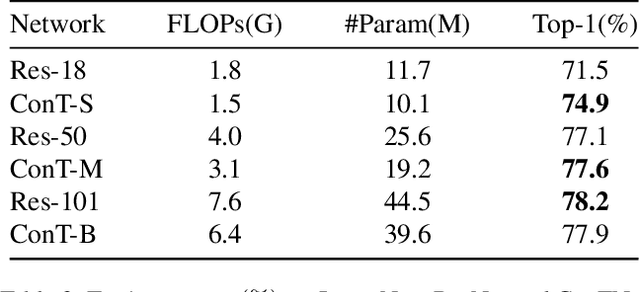
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design