 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaryBERT: Pushing the Limit of BERT Quantization
Dec 31, 2020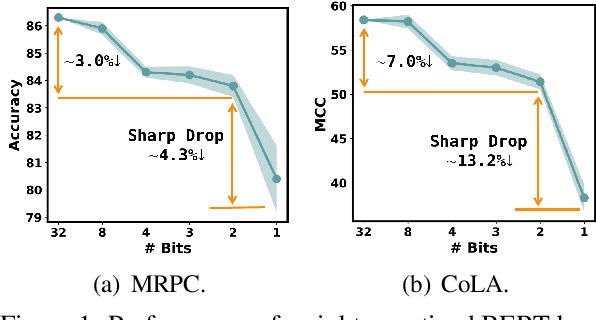
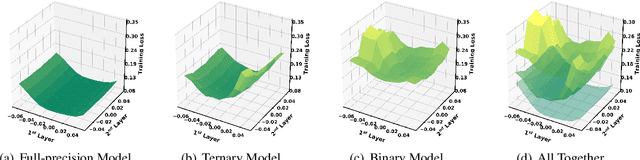
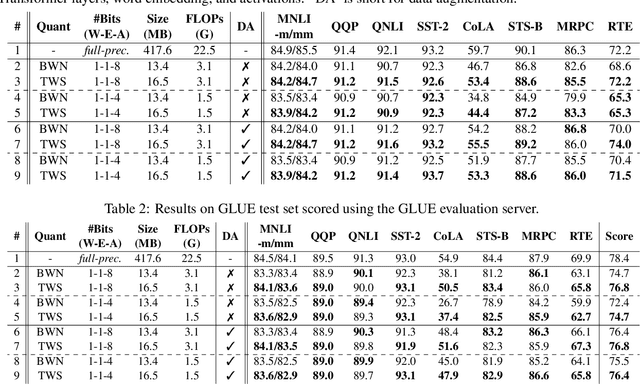
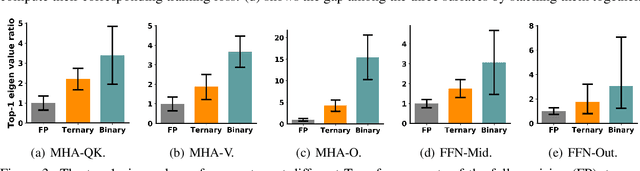
The rapid development of large pre-trained language models has greatly increased the demand for model compression techniques, among which quantization is a popular solution. In this paper, we propose BinaryBERT, which pushes BERT quantization to the limit with weight binarization. We find that a binary BERT is hard to be trained directly than a ternary counterpart due to its complex and irregular loss landscapes. Therefore, we propose ternary weight splitting, which initializes the binary model by equivalent splitting from a half-sized ternary network. The binary model thus inherits the good performance of the ternary model, and can be further enhanced by fine-tuning the new architecture after splitting. Empirical results show that BinaryBERT has negligible performance drop compared to the full-precision BERT-base while being $24\times$ smaller, achieving the state-of-the-art results on GLUE and SQuAD benchmarks.
Multi-Task Learning with Shared Encoder for Non-Autoregressive Machine Translation
Oct 24, 2020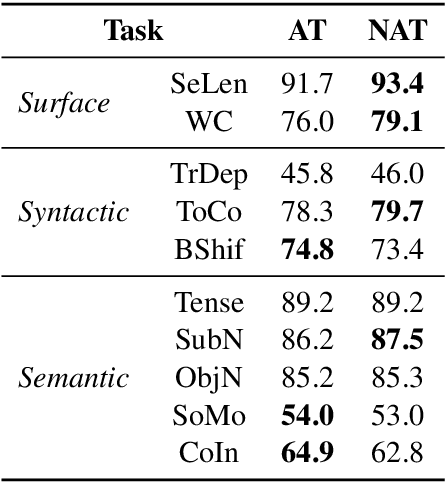
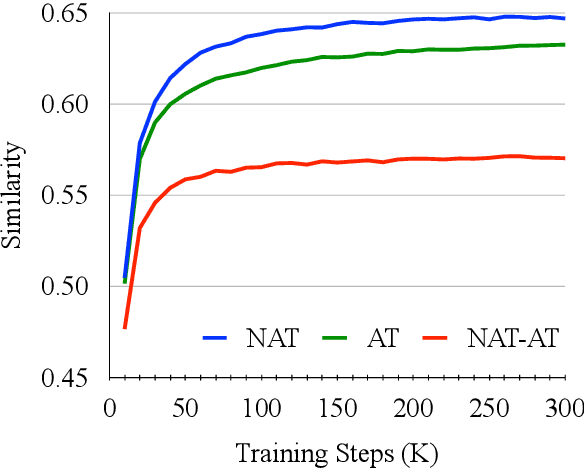
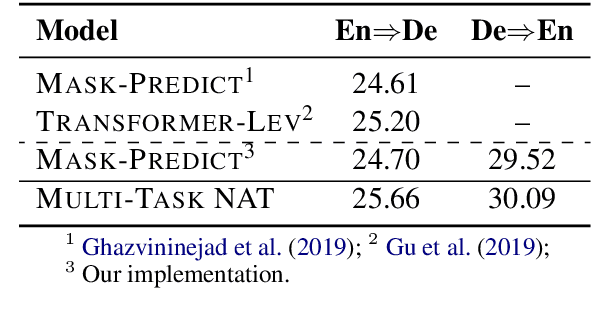
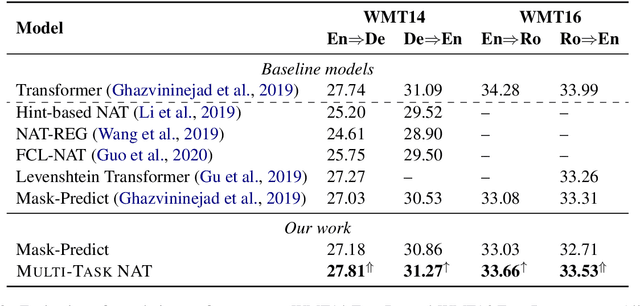
Non-Autoregressive machine Translation (NAT) models have demonstrated significant inference speedup but suffer from inferior translation accuracy. The common practice to tackle the problem is transferring the Autoregressive machine Translation (AT) knowledge to NAT models, e.g., with knowledge distillation. In this work, we hypothesize and empirically verify that AT and NAT encoders capture different linguistic properties and representations of source sentences. Therefore, we propose to adopt the multi-task learning to transfer the AT knowledge to NAT models through the encoder sharing. Specifically, we take the AT model as an auxiliary task to enhance NAT model performance. Experimental results on WMT14 English->German and WMT16 English->Romanian datasets show that the proposed multi-task NAT achieves significant improvements over the baseline NAT models. In addition, experimental results demonstrate that our multi-task NAT is complementary to the standard knowledge transfer method, knowledge distillation. Code is publicly available at https://github.com/yongchanghao/multi-task-nat
Learning 3D Face Reconstruction with a Pose Guidance Network
Oct 09, 2020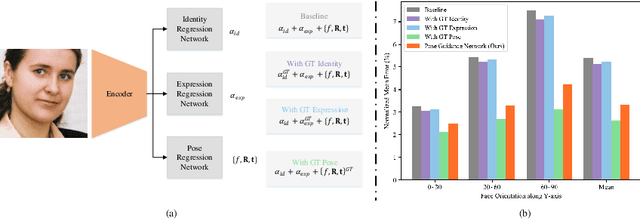
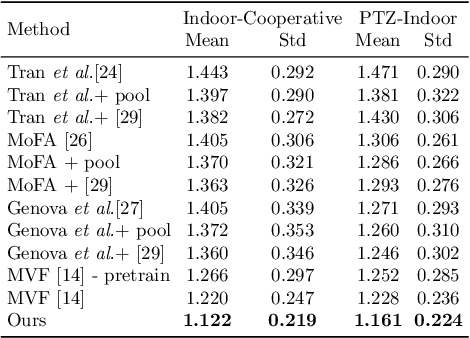
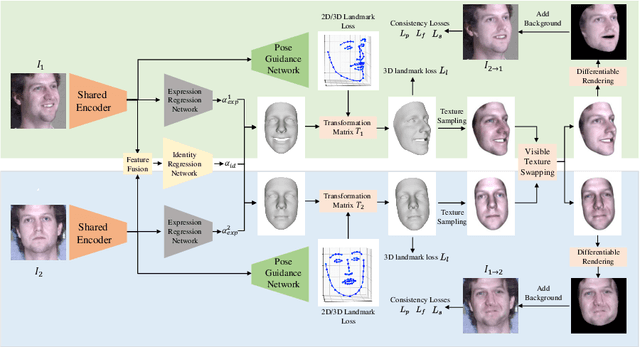

We present a self-supervised learning approach to learning monocular 3D face reconstruction with a pose guidance network (PGN). First, we unveil the bottleneck of pose estimation in prior parametric 3D face learning methods, and propose to utilize 3D face landmarks for estimating pose parameters. With our specially designed PGN, our model can learn from both faces with fully labeled 3D landmarks and unlimited unlabeled in-the-wild face images. Our network is further augmented with a self-supervised learning scheme, which exploits face geometry information embedded in multiple frames of the same person, to alleviate the ill-posed nature of regressing 3D face geometry from a single image. These three insights yield a single approach that combines the complementary strengths of parametric model learning and data-driven learning techniques. We conduct a rigorous evaluation on the challenging AFLW2000-3D, Florence and FaceWarehouse datasets, and show that our method outperforms the state-of-the-art for all metrics.
Why an Android App is Classified as Malware? Towards Malware Classification Interpretation
Apr 24, 2020

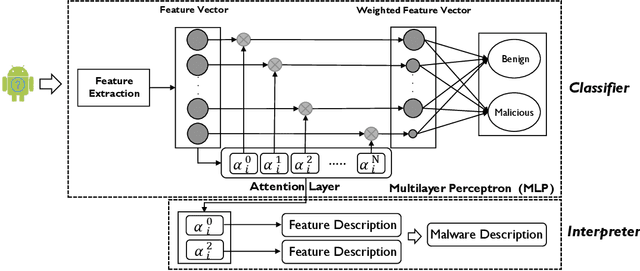

Machine learning (ML) based approach is considered as one of the most promising techniques for Android malware detection and has achieved high accuracy by leveraging commonly-used features. In practice, most of the ML classifications only provide a binary label to mobile users and app security analysts. However, stakeholders are more interested in the reason why apps are classified as malicious in both academia and industry. This belongs to the research area of interpretable ML but in a specific research domain (i.e., mobile malware detection). Although several interpretable ML methods have been exhibited to explain the final classification results in many cutting-edge Artificial Intelligent (AI) based research fields, till now, there is no study interpreting why an app is classified as malware or unveiling the domain-specific challenges. In this paper, to fill this gap, we propose a novel and interpretable ML-based approach (named XMal) to classify malware with high accuracy and explain the classification result meanwhile. (1) The first classification phase of XMal hinges multi-layer perceptron (MLP) and attention mechanism, and also pinpoints the key features most related to the classification result. (2) The second interpreting phase aims at automatically producing neural language descriptions to interpret the core malicious behaviors within apps. We evaluate the behavior description results by comparing with the existing interpretable ML-based methods (i.e., Drebin and LIME) to demonstrate the effectiveness of XMal. We find that XMal is able to reveal the malicious behaviors more accurately. Additionally, our experiments show that XMal can also interpret the reason why some samples are misclassified by ML classifiers. Our study peeks into the interpretable ML through the research of Android malware detection and analysis.
Discrete Variational Attention Models for Language Generation
Apr 21, 2020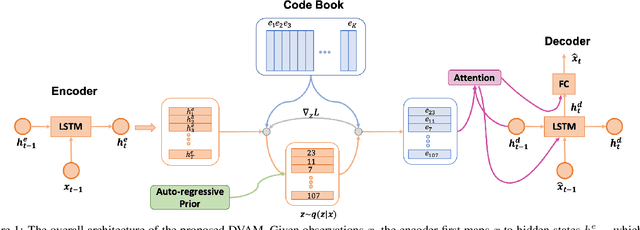
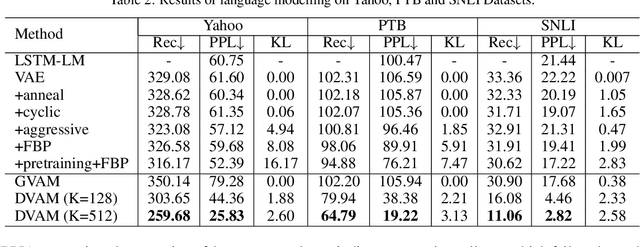
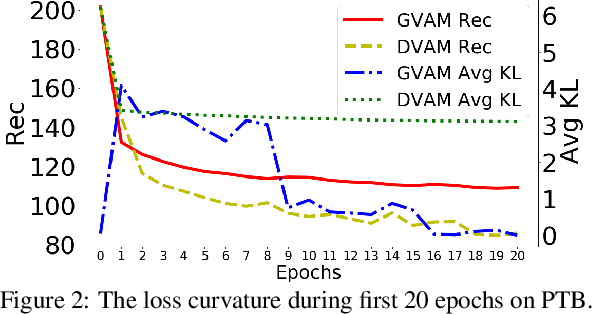
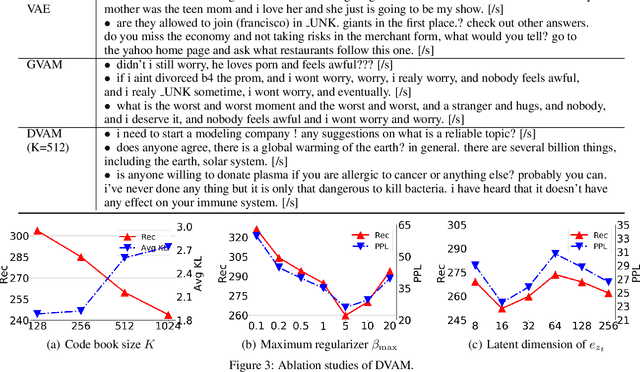
Variational autoencoders have been widely applied for natural language generation, however, there are two long-standing problems: information under-representation and posterior collapse. The former arises from the fact that only the last hidden state from the encoder is transformed to the latent space, which is insufficient to summarize data. The latter comes as a result of the imbalanced scale between the reconstruction loss and the KL divergence in the objective function. To tackle these issues, in this paper we propose the discrete variational attention model with categorical distribution over the attention mechanism owing to the discrete nature in languages. Our approach is combined with an auto-regressive prior to capture the sequential dependency from observations, which can enhance the latent space for language generation. Moreover, thanks to the property of discreteness, the training of our proposed approach does not suffer from posterior collapse. Furthermore, we carefully analyze the superiority of discrete latent space over the continuous space with the common Gaussian distribution. Extensive experiments on language generation demonstrate superior advantages of our proposed approach in comparison with the state-of-the-art counterparts.
Flow2Stereo: Effective Self-Supervised Learning of Optical Flow and Stereo Matching
Apr 05, 2020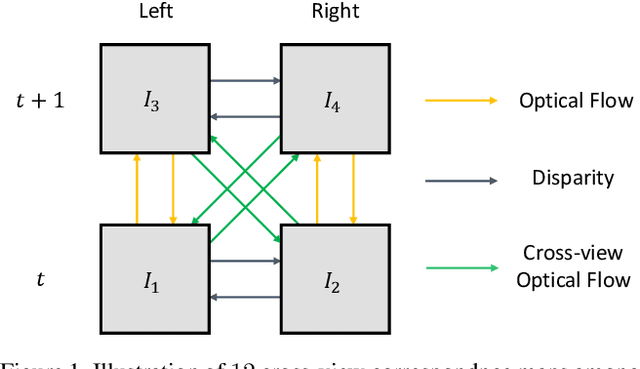
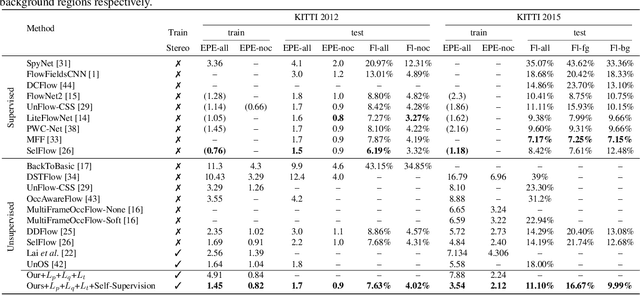
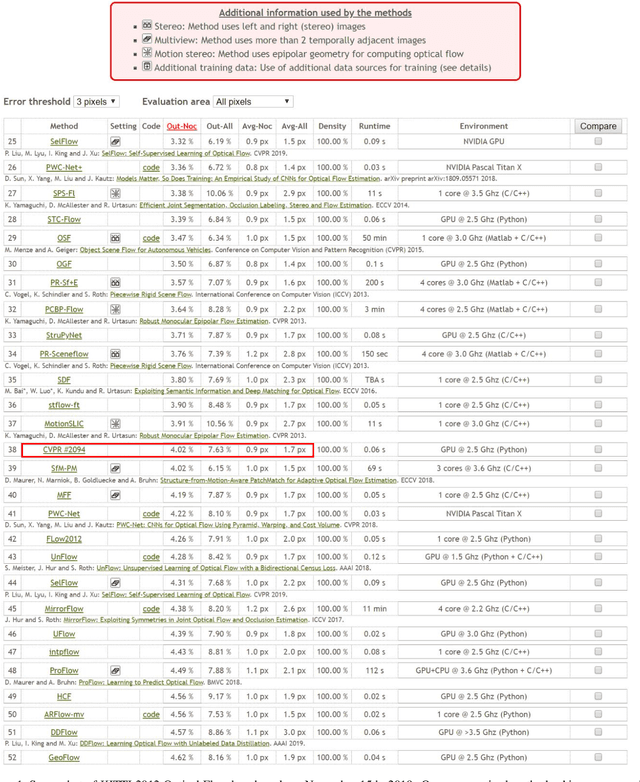
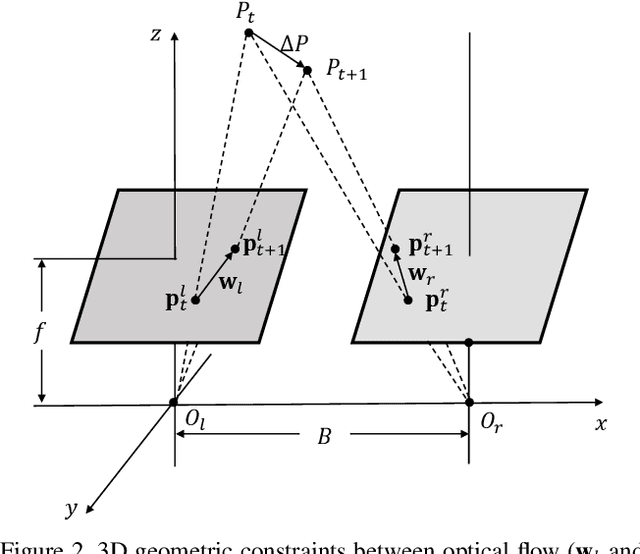
In this paper, we propose a unified method to jointly learn optical flow and stereo matching. Our first intuition is stereo matching can be modeled as a special case of optical flow, and we can leverage 3D geometry behind stereoscopic videos to guide the learning of these two forms of correspondences. We then enroll this knowledge into the state-of-the-art self-supervised learning framework, and train one single network to estimate both flow and stereo. Second, we unveil the bottlenecks in prior self-supervised learning approaches, and propose to create a new set of challenging proxy tasks to boost performance. These two insights yield a single model that achieves the highest accuracy among all existing unsupervised flow and stereo methods on KITTI 2012 and 2015 benchmarks. More remarkably, our self-supervised method even outperforms several state-of-the-art fully supervised methods, including PWC-Net and FlowNet2 on KITTI 2012.
Few Shot Network Compression via Cross Distillation
Nov 21, 2019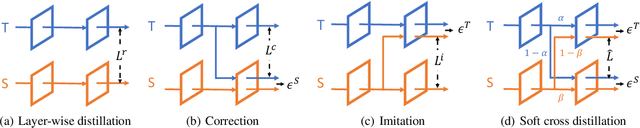
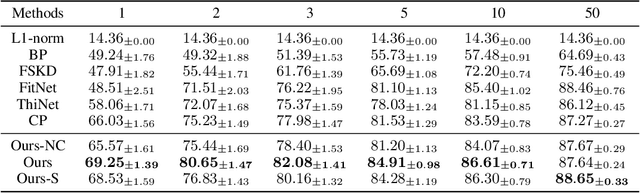
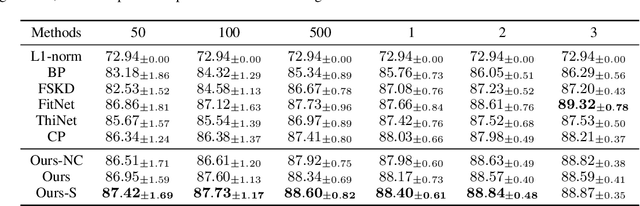
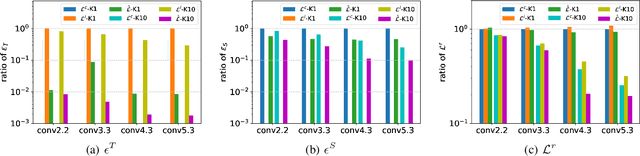
Model compression has been widely adopted to obtain light-weighted deep neural networks. Most prevalent methods, however, require fine-tuning with sufficient training data to ensure accuracy, which could be challenged by privacy and security issues. As a compromise between privacy and performance, in this paper we investigate few shot network compression: given few samples per class, how can we effectively compress the network with negligible performance drop? The core challenge of few shot network compression lies in high estimation errors from the original network during inference, since the compressed network can easily over-fits on the few training instances. The estimation errors could propagate and accumulate layer-wisely and finally deteriorate the network output. To address the problem, we propose cross distillation, a novel layer-wise knowledge distillation approach. By interweaving hidden layers of teacher and student network, layer-wisely accumulated estimation errors can be effectively reduced.The proposed method offers a general framework compatible with prevalent network compression techniques such as pruning. Extensive experiments on benchmark datasets demonstrate that cross distillation can significantly improve the student network's accuracy when only a few training instances are available.
Detecting Deep Neural Network Defects with Data Flow Analysis
Sep 30, 2019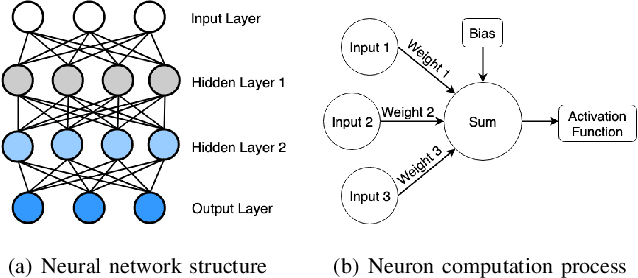


Deep neural networks (DNNs) are shown to be promising solutions in many challenging artificial intelligence tasks. However, it is very hard to figure out whether the low precision of a DNN model is an inevitable result, or caused by defects. This paper aims at addressing this challenging problem. We find that the internal data flow footprints of a DNN model can provide insights to locate the root cause effectively. We develop DeepMorph (DNN Tomography) to analyze the root cause, which can guide a DNN developer to improve the model.
SelFlow: Self-Supervised Learning of Optical Flow
Apr 19, 2019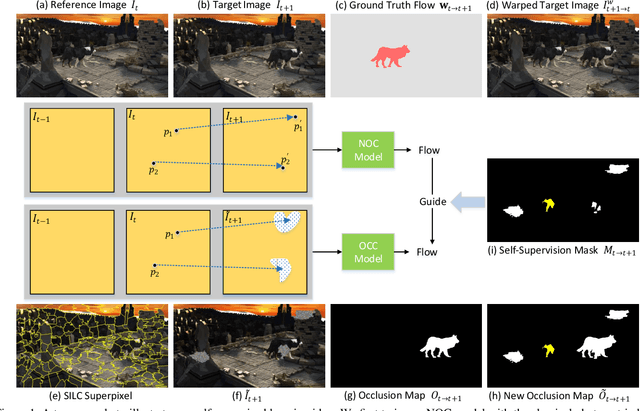
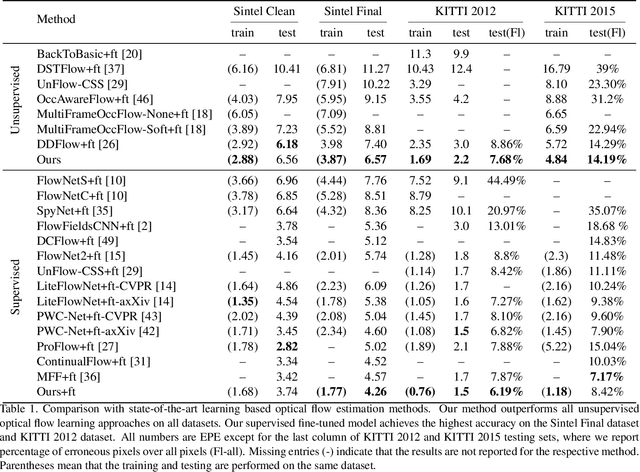
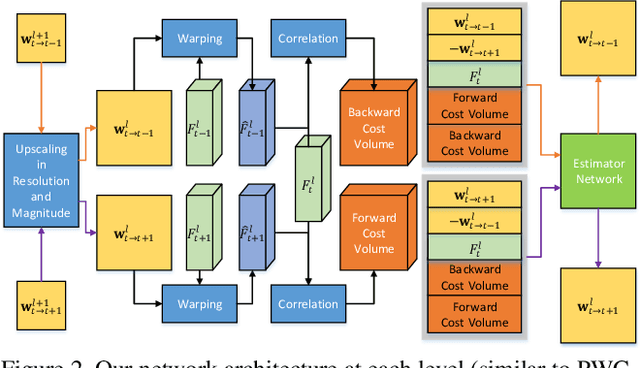
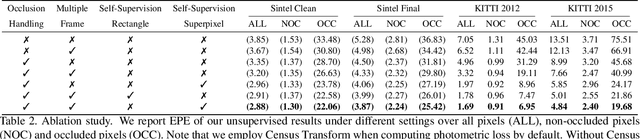
We present a self-supervised learning approach for optical flow. Our method distills reliable flow estimations from non-occluded pixels, and uses these predictions as ground truth to learn optical flow for hallucinated occlusions. We further design a simple CNN to utilize temporal information from multiple frames for better flow estimation. These two principles lead to an approach that yields the best performance for unsupervised optical flow learning on the challenging benchmarks including MPI Sintel, KITTI 2012 and 2015. More notably, our self-supervised pre-trained model provides an excellent initialization for supervised fine-tuning. Our fine-tuned models achieve state-of-the-art results on all three datasets. At the time of writing, we achieve EPE=4.26 on the Sintel benchmark, outperforming all submitted methods.
Simple and Efficient Parallelization for Probabilistic Temporal Tensor Factorization
Nov 11, 2016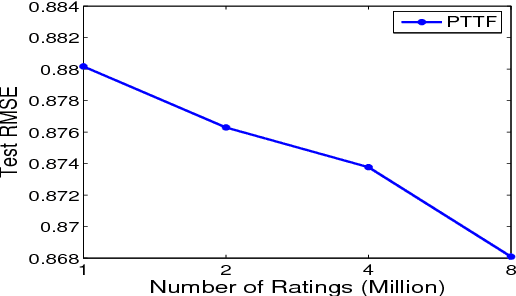
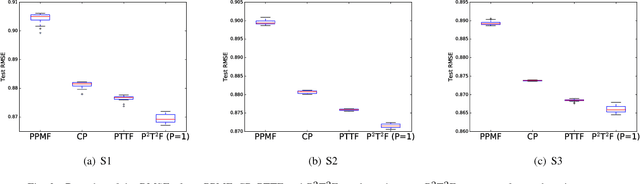
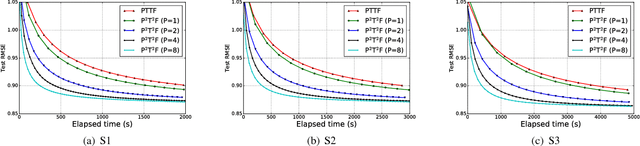
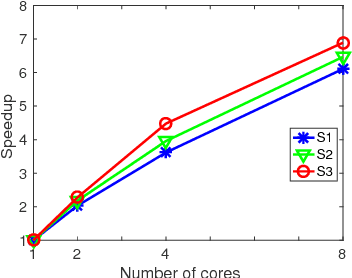
Probabilistic Temporal Tensor Factorization (PTTF) is an effective algorithm to model the temporal tensor data. It leverages a time constraint to capture the evolving properties of tensor data. Nowadays the exploding dataset demands a large scale PTTF analysis, and a parallel solution is critical to accommodate the trend. Whereas, the parallelization of PTTF still remains unexplored. In this paper, we propose a simple yet efficient Parallel Probabilistic Temporal Tensor Factorization, referred to as P$^2$T$^2$F, to provide a scalable PTTF solution. P$^2$T$^2$F is fundamentally disparate from existing parallel tensor factorizations by considering the probabilistic decomposition and the temporal effects of tensor data. It adopts a new tensor data split strategy to subdivide a large tensor into independent sub-tensors, the computation of which is inherently parallel. We train P$^2$T$^2$F with an efficient algorithm of stochastic Alternating Direction Method of Multipliers, and show that the convergence is guaranteed. Experiments on several real-word tensor datasets demonstrate that P$^2$T$^2$F is a highly effective and efficiently scalable algorithm dedicated for large scale probabilistic temporal tensor analysis.