 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks
Sep 18, 2019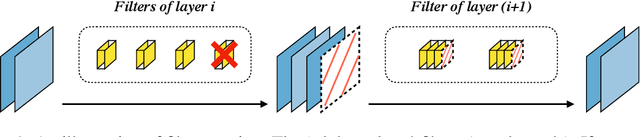

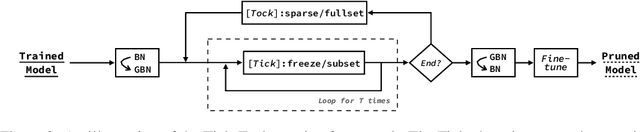
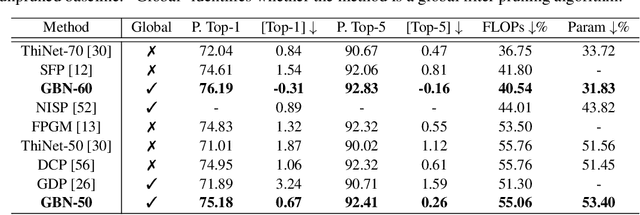
Filter pruning is one of the most effective ways to accelerate and compress convolutional neural networks (CNNs). In this work, we propose a global filter pruning algorithm called Gate Decorator, which transforms a vanilla CNN module by multiplying its output by the channel-wise scaling factors, i.e. gate. When the scaling factor is set to zero, it is equivalent to removing the corresponding filter. We use Taylor expansion to estimate the change in the loss function caused by setting the scaling factor to zero and use the estimation for the global filter importance ranking. Then we prune the network by removing those unimportant filters. After pruning, we merge all the scaling factors into its original module, so no special operations or structures are introduced. Moreover, we propose an iterative pruning framework called Tick-Tock to improve pruning accuracy. The extensive experiments demonstrate the effectiveness of our approaches. For example, we achieve the state-of-the-art pruning ratio on ResNet-56 by reducing 70% FLOPs without noticeable loss in accuracy. For ResNet-50 on ImageNet, our pruned model with 40% FLOPs reduction outperforms the baseline model by 0.31% in top-1 accuracy. Various datasets are used, including CIFAR-10, CIFAR-100, CUB-200, ImageNet ILSVRC-12 and PASCAL VOC 2011. Code is available at github.com/youzhonghui/gate-decorator-pruning
Compressing Recurrent Neural Networks with Tensor Ring for Action Recognition
Nov 19, 2018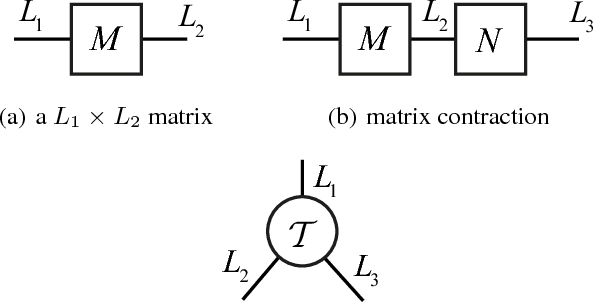
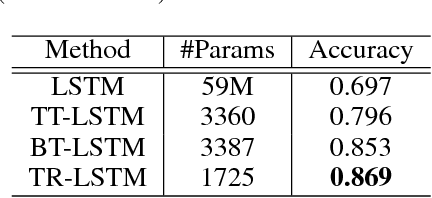
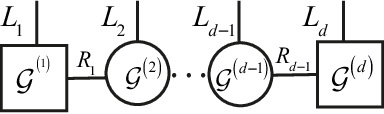
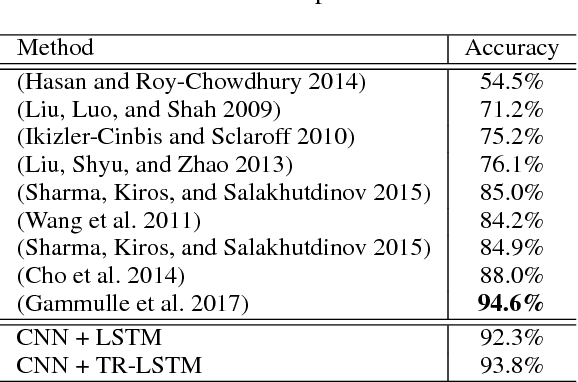
Recurrent Neural Networks (RNNs) and their variants, such as Long-Short Term Memory (LSTM) networks, and Gated Recurrent Unit (GRU) networks, have achieved promising performance in sequential data modeling. The hidden layers in RNNs can be regarded as the memory units, which are helpful in storing information in sequential contexts. However, when dealing with high dimensional input data, such as video and text, the input-to-hidden linear transformation in RNNs brings high memory usage and huge computational cost. This makes the training of RNNs unscalable and difficult. To address this challenge, we propose a novel compact LSTM model, named as TR-LSTM, by utilizing the low-rank tensor ring decomposition (TRD) to reformulate the input-to-hidden transformation. Compared with other tensor decomposition methods, TR-LSTM is more stable. In addition, TR-LSTM can complete an end-to-end training and also provide a fundamental building block for RNNs in handling large input data. Experiments on real-world action recognition datasets have demonstrated the promising performance of the proposed TR-LSTM compared with the tensor train LSTM and other state-of-the-art competitors.
Adversarial Noise Layer: Regularize Neural Network By Adding Noise
Oct 30, 2018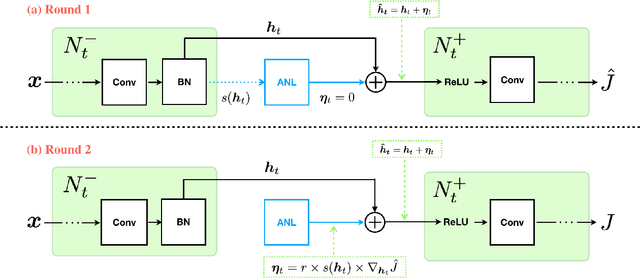
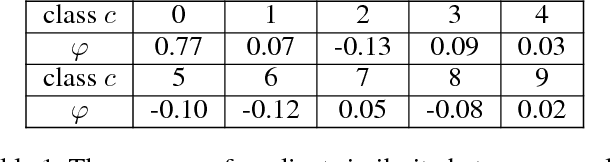
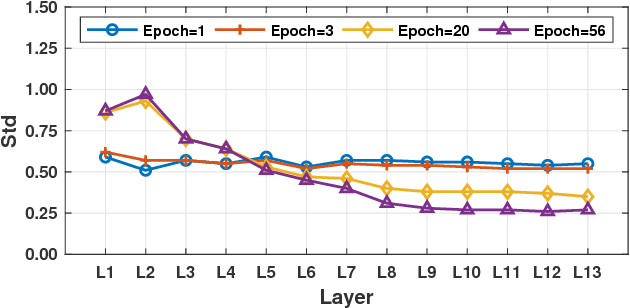
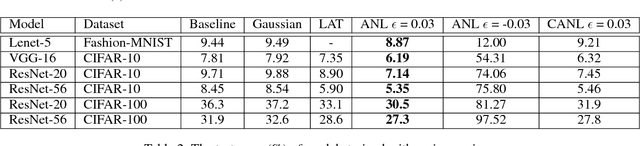
In this paper, we introduce a novel regularization method called Adversarial Noise Layer (ANL) and its efficient version called Class Adversarial Noise Layer (CANL), which are able to significantly improve CNN's generalization ability by adding carefully crafted noise into the intermediate layer activations. ANL and CANL can be easily implemented and integrated with most of the mainstream CNN-based models. We compared the effects of the different types of noise and visually demonstrate that our proposed adversarial noise instruct CNN models to learn to extract cleaner feature maps, which further reduce the risk of over-fitting. We also conclude that models trained with ANL or CANL are more robust to the adversarial examples generated by FGSM than the traditional adversarial training approaches.
Learning Compact Recurrent Neural Networks with Block-Term Tensor Decomposition
May 11, 2018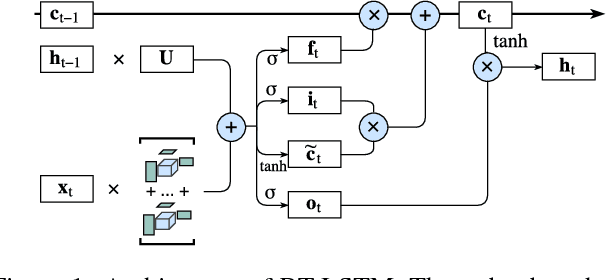
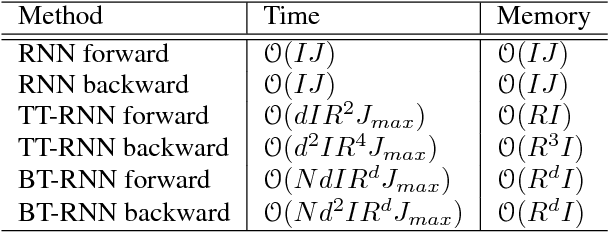
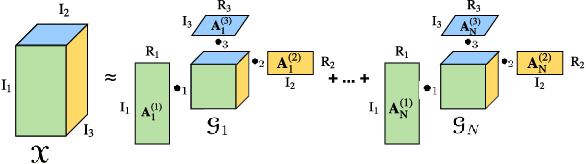
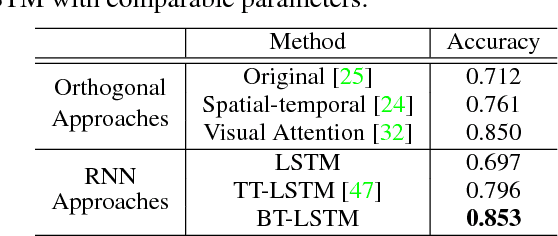
Recurrent Neural Networks (RNNs) are powerful sequence modeling tools. However, when dealing with high dimensional inputs, the training of RNNs becomes computational expensive due to the large number of model parameters. This hinders RNNs from solving many important computer vision tasks, such as Action Recognition in Videos and Image Captioning. To overcome this problem, we propose a compact and flexible structure, namely Block-Term tensor decomposition, which greatly reduces the parameters of RNNs and improves their training efficiency. Compared with alternative low-rank approximations, such as tensor-train RNN (TT-RNN), our method, Block-Term RNN (BT-RNN), is not only more concise (when using the same rank), but also able to attain a better approximation to the original RNNs with much fewer parameters. On three challenging tasks, including Action Recognition in Videos, Image Captioning and Image Generation, BT-RNN outperforms TT-RNN and the standard RNN in terms of both prediction accuracy and convergence rate. Specifically, BT-LSTM utilizes 17,388 times fewer parameters than the standard LSTM to achieve an accuracy improvement over 15.6\% in the Action Recognition task on the UCF11 dataset.
SuperNeurons: Dynamic GPU Memory Management for Training Deep Neural Networks
Jan 13, 2018
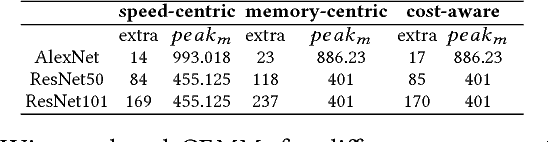
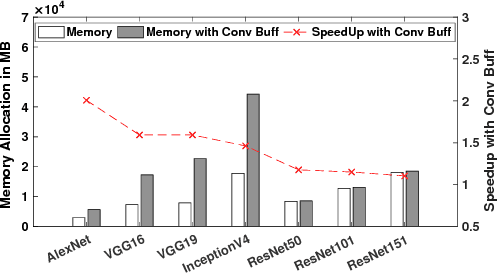

Going deeper and wider in neural architectures improves the accuracy, while the limited GPU DRAM places an undesired restriction on the network design domain. Deep Learning (DL) practitioners either need change to less desired network architectures, or nontrivially dissect a network across multiGPUs. These distract DL practitioners from concentrating on their original machine learning tasks. We present SuperNeurons: a dynamic GPU memory scheduling runtime to enable the network training far beyond the GPU DRAM capacity. SuperNeurons features 3 memory optimizations, \textit{Liveness Analysis}, \textit{Unified Tensor Pool}, and \textit{Cost-Aware Recomputation}, all together they effectively reduce the network-wide peak memory usage down to the maximal memory usage among layers. We also address the performance issues in those memory saving techniques. Given the limited GPU DRAM, SuperNeurons not only provisions the necessary memory for the training, but also dynamically allocates the memory for convolution workspaces to achieve the high performance. Evaluations against Caffe, Torch, MXNet and TensorFlow have demonstrated that SuperNeurons trains at least 3.2432 deeper network than current ones with the leading performance. Particularly, SuperNeurons can train ResNet2500 that has $10^4$ basic network layers on a 12GB K40c.
BT-Nets: Simplifying Deep Neural Networks via Block Term Decomposition
Dec 15, 2017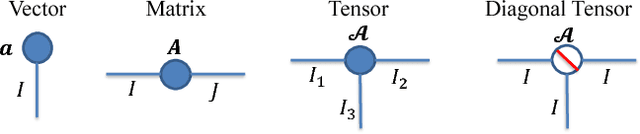
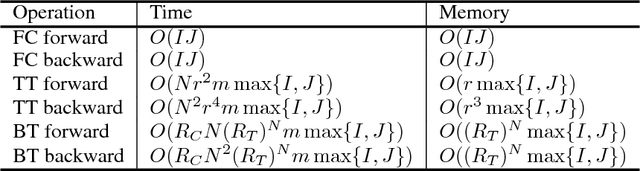
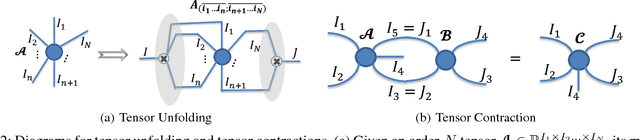

Recently, deep neural networks (DNNs) have been regarded as the state-of-the-art classification methods in a wide range of applications, especially in image classification. Despite the success, the huge number of parameters blocks its deployment to situations with light computing resources. Researchers resort to the redundancy in the weights of DNNs and attempt to find how fewer parameters can be chosen while preserving the accuracy at the same time. Although several promising results have been shown along this research line, most existing methods either fail to significantly compress a well-trained deep network or require a heavy fine-tuning process for the compressed network to regain the original performance. In this paper, we propose the \textit{Block Term} networks (BT-nets) in which the commonly used fully-connected layers (FC-layers) are replaced with block term layers (BT-layers). In BT-layers, the inputs and the outputs are reshaped into two low-dimensional high-order tensors, then block-term decomposition is applied as tensor operators to connect them. We conduct extensive experiments on benchmark datasets to demonstrate that BT-layers can achieve a very large compression ratio on the number of parameters while preserving the representation power of the original FC-layers as much as possible. Specifically, we can get a higher performance while requiring fewer parameters compared with the tensor train method.
Simple and Efficient Parallelization for Probabilistic Temporal Tensor Factorization
Nov 11, 2016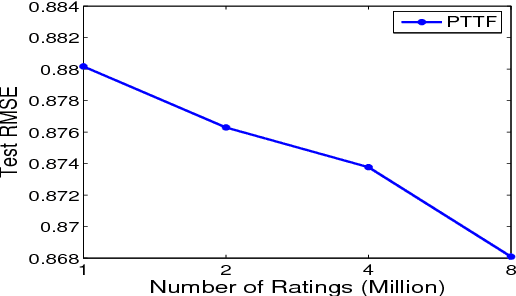
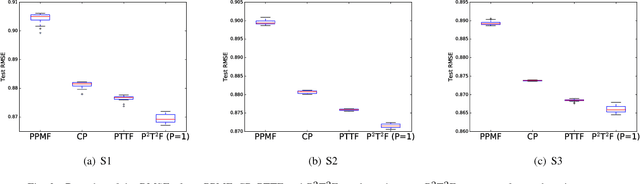
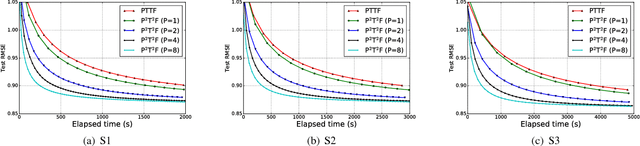
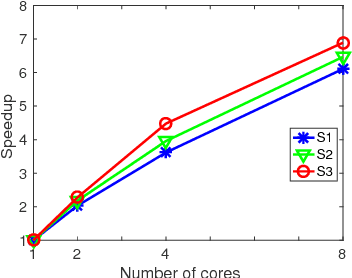
Probabilistic Temporal Tensor Factorization (PTTF) is an effective algorithm to model the temporal tensor data. It leverages a time constraint to capture the evolving properties of tensor data. Nowadays the exploding dataset demands a large scale PTTF analysis, and a parallel solution is critical to accommodate the trend. Whereas, the parallelization of PTTF still remains unexplored. In this paper, we propose a simple yet efficient Parallel Probabilistic Temporal Tensor Factorization, referred to as P$^2$T$^2$F, to provide a scalable PTTF solution. P$^2$T$^2$F is fundamentally disparate from existing parallel tensor factorizations by considering the probabilistic decomposition and the temporal effects of tensor data. It adopts a new tensor data split strategy to subdivide a large tensor into independent sub-tensors, the computation of which is inherently parallel. We train P$^2$T$^2$F with an efficient algorithm of stochastic Alternating Direction Method of Multipliers, and show that the convergence is guaranteed. Experiments on several real-word tensor datasets demonstrate that P$^2$T$^2$F is a highly effective and efficiently scalable algorithm dedicated for large scale probabilistic temporal tensor analysis.