 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Value Estimation for Efficient Model-Free Reinforcement Learning
Feb 28, 2018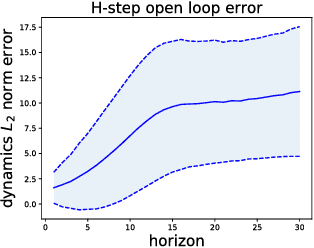

Recent model-free reinforcement learning algorithms have proposed incorporating learned dynamics models as a source of additional data with the intention of reducing sample complexity. Such methods hold the promise of incorporating imagined data coupled with a notion of model uncertainty to accelerate the learning of continuous control tasks. Unfortunately, they rely on heuristics that limit usage of the dynamics model. We present model-based value expansion, which controls for uncertainty in the model by only allowing imagination to fixed depth. By enabling wider use of learned dynamics models within a model-free reinforcement learning algorithm, we improve value estimation, which, in turn, reduces the sample complexity of learning.
On the Theory of Variance Reduction for Stochastic Gradient Monte Carlo
Feb 15, 2018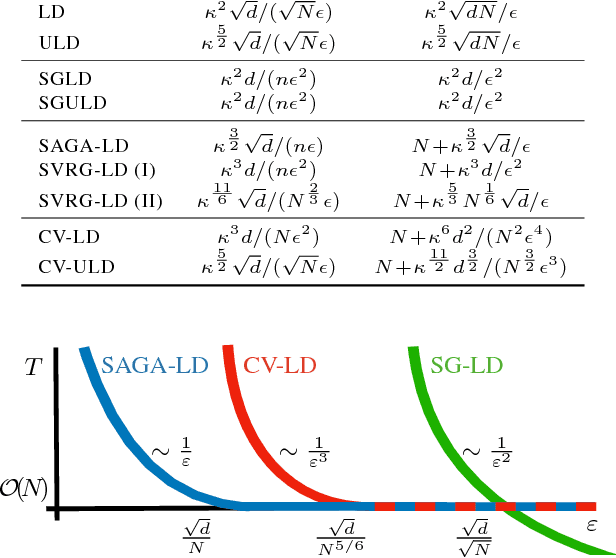
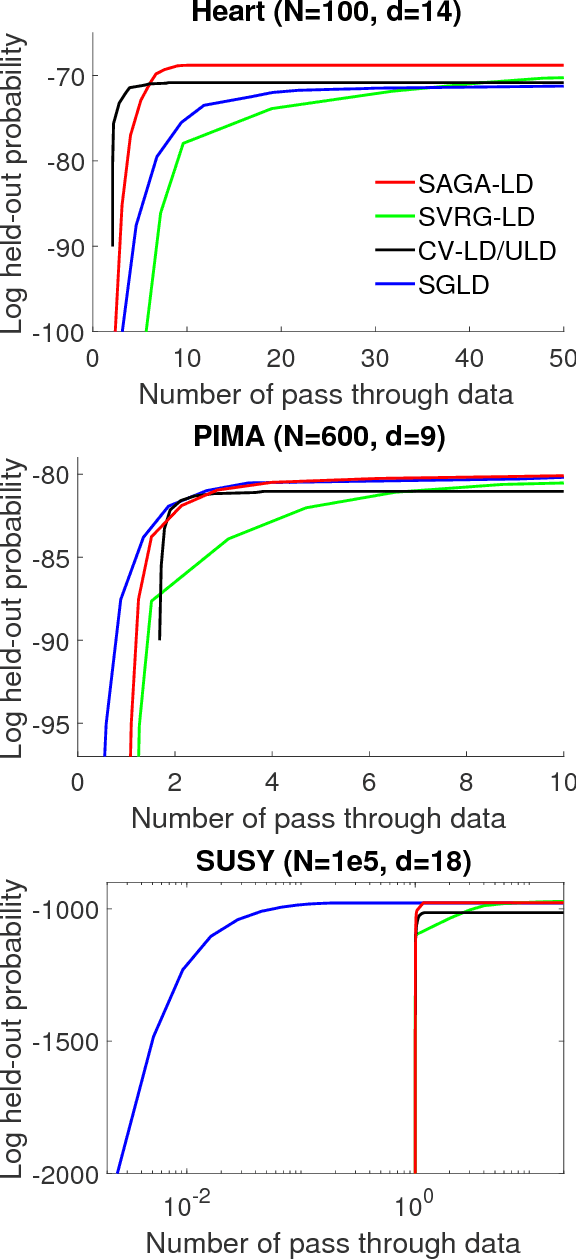
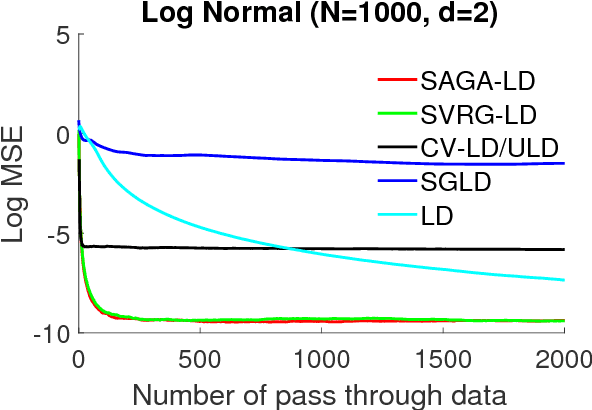
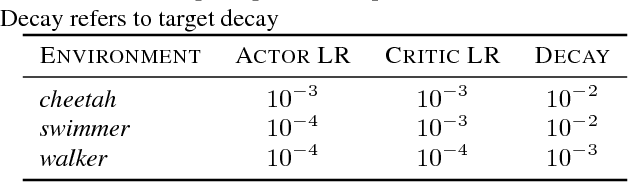
We provide convergence guarantees in Wasserstein distance for a variety of variance-reduction methods: SAGA Langevin diffusion, SVRG Langevin diffusion and control-variate underdamped Langevin diffusion. We analyze these methods under a uniform set of assumptions on the log-posterior distribution, assuming it to be smooth, strongly convex and Hessian Lipschitz. This is achieved by a new proof technique combining ideas from finite-sum optimization and the analysis of sampling methods. Our sharp theoretical bounds allow us to identify regimes of interest where each method performs better than the others. Our theory is verified with experiments on real-world and synthetic datasets.
Conditional Adversarial Domain Adaptation
Feb 10, 2018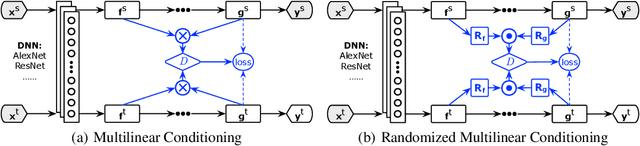
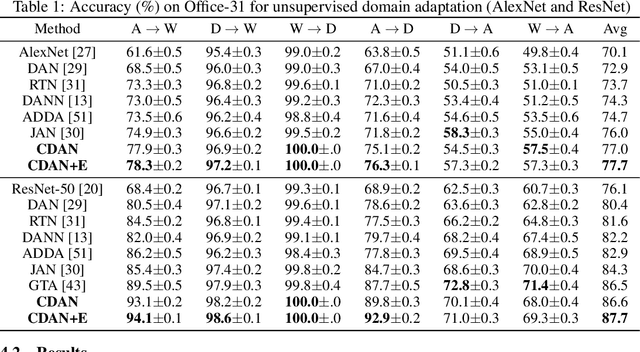
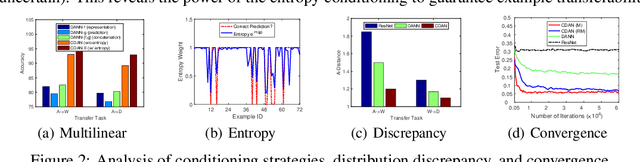
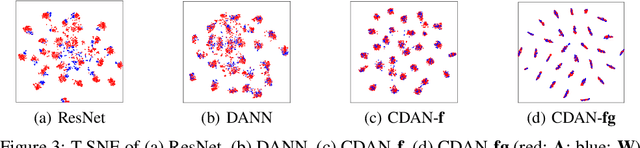
Adversarial learning has been embedded into deep networks to learn transferable representations for domain adaptation. Existing adversarial domain adaptation methods may struggle to align different domains of multimode distributions that are native in classification problems. In this paper, we present conditional adversarial domain adaptation, a novel framework that conditions the adversarial adaptation models on discriminative information conveyed in the classifier predictions. Conditional domain adversarial networks are proposed to enable discriminative adversarial adaptation of multimode domains. The experiments testify that the proposed approaches exceed the state-of-the-art performance on three domain adaptation datasets.
Underdamped Langevin MCMC: A non-asymptotic analysis
Jan 26, 2018We study the underdamped Langevin diffusion when the log of the target distribution is smooth and strongly concave. We present a MCMC algorithm based on its discretization and show that it achieves $\varepsilon$ error (in 2-Wasserstein distance) in $\mathcal{O}(\sqrt{d}/\varepsilon)$ steps. This is a significant improvement over the best known rate for overdamped Langevin MCMC, which is $\mathcal{O}(d/\varepsilon^2)$ steps under the same smoothness/concavity assumptions. The underdamped Langevin MCMC scheme can be viewed as a version of Hamiltonian Monte Carlo (HMC) which has been observed to outperform overdamped Langevin MCMC methods in a number of application areas. We provide quantitative rates that support this empirical wisdom.
Stochastic Cubic Regularization for Fast Nonconvex Optimization
Dec 05, 2017
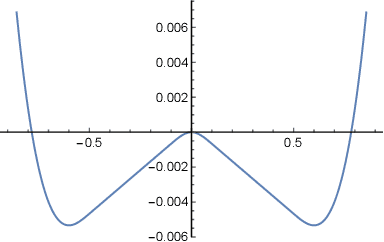
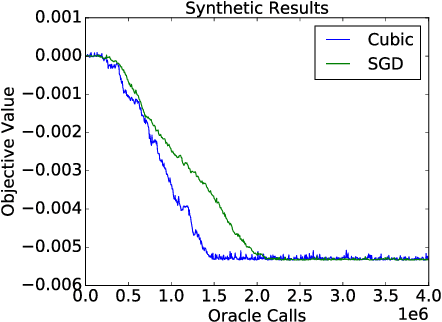
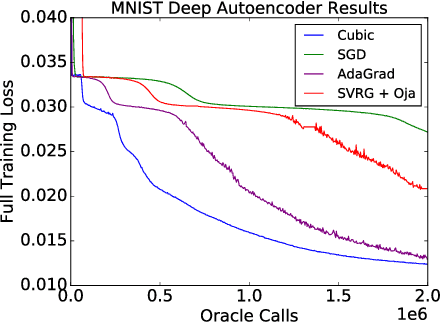
This paper proposes a stochastic variant of a classic algorithm---the cubic-regularized Newton method [Nesterov and Polyak 2006]. The proposed algorithm efficiently escapes saddle points and finds approximate local minima for general smooth, nonconvex functions in only $\mathcal{\tilde{O}}(\epsilon^{-3.5})$ stochastic gradient and stochastic Hessian-vector product evaluations. The latter can be computed as efficiently as stochastic gradients. This improves upon the $\mathcal{\tilde{O}}(\epsilon^{-4})$ rate of stochastic gradient descent. Our rate matches the best-known result for finding local minima without requiring any delicate acceleration or variance-reduction techniques.
Accelerated Gradient Descent Escapes Saddle Points Faster than Gradient Descent
Nov 28, 2017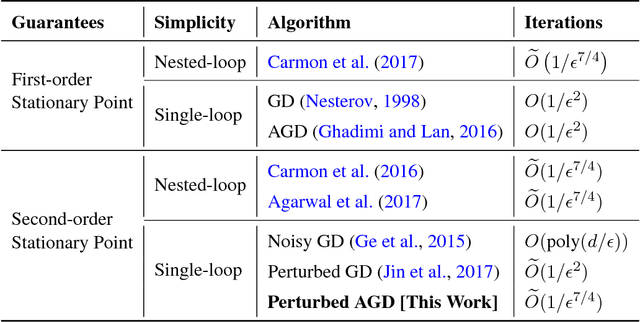
Nesterov's accelerated gradient descent (AGD), an instance of the general family of "momentum methods", provably achieves faster convergence rate than gradient descent (GD) in the convex setting. However, whether these methods are superior to GD in the nonconvex setting remains open. This paper studies a simple variant of AGD, and shows that it escapes saddle points and finds a second-order stationary point in $\tilde{O}(1/\epsilon^{7/4})$ iterations, faster than the $\tilde{O}(1/\epsilon^{2})$ iterations required by GD. To the best of our knowledge, this is the first Hessian-free algorithm to find a second-order stationary point faster than GD, and also the first single-loop algorithm with a faster rate than GD even in the setting of finding a first-order stationary point. Our analysis is based on two key ideas: (1) the use of a simple Hamiltonian function, inspired by a continuous-time perspective, which AGD monotonically decreases per step even for nonconvex functions, and (2) a novel framework called improve or localize, which is useful for tracking the long-term behavior of gradient-based optimization algorithms. We believe that these techniques may deepen our understanding of both acceleration algorithms and nonconvex optimization.
Gradient Descent Can Take Exponential Time to Escape Saddle Points
Nov 05, 2017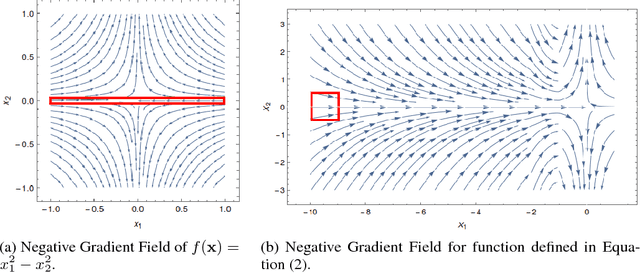
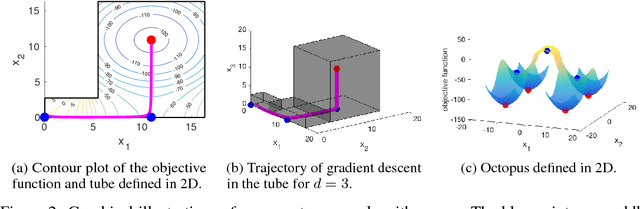
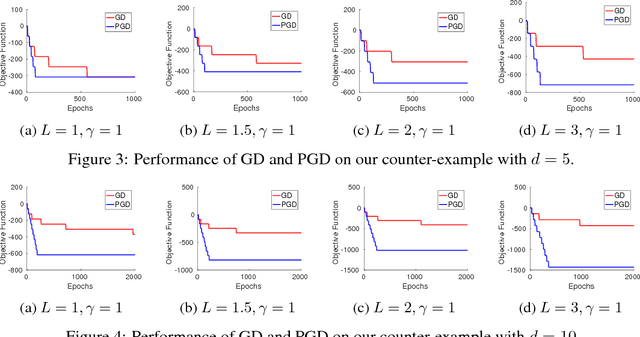
Although gradient descent (GD) almost always escapes saddle points asymptotically [Lee et al., 2016], this paper shows that even with fairly natural random initialization schemes and non-pathological functions, GD can be significantly slowed down by saddle points, taking exponential time to escape. On the other hand, gradient descent with perturbations [Ge et al., 2015, Jin et al., 2017] is not slowed down by saddle points - it can find an approximate local minimizer in polynomial time. This result implies that GD is inherently slower than perturbed GD, and justifies the importance of adding perturbations for efficient non-convex optimization. While our focus is theoretical, we also present experiments that illustrate our theoretical findings.
Fast Black-box Variational Inference through Stochastic Trust-Region Optimization
Nov 05, 2017
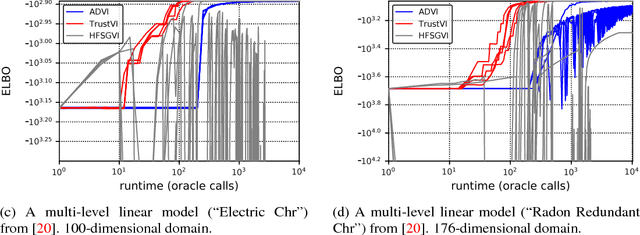
We introduce TrustVI, a fast second-order algorithm for black-box variational inference based on trust-region optimization and the reparameterization trick. At each iteration, TrustVI proposes and assesses a step based on minibatches of draws from the variational distribution. The algorithm provably converges to a stationary point. We implemented TrustVI in the Stan framework and compared it to two alternatives: Automatic Differentiation Variational Inference (ADVI) and Hessian-free Stochastic Gradient Variational Inference (HFSGVI). The former is based on stochastic first-order optimization. The latter uses second-order information, but lacks convergence guarantees. TrustVI typically converged at least one order of magnitude faster than ADVI, demonstrating the value of stochastic second-order information. TrustVI often found substantially better variational distributions than HFSGVI, demonstrating that our convergence theory can matter in practice.
First-order Methods Almost Always Avoid Saddle Points
Oct 20, 2017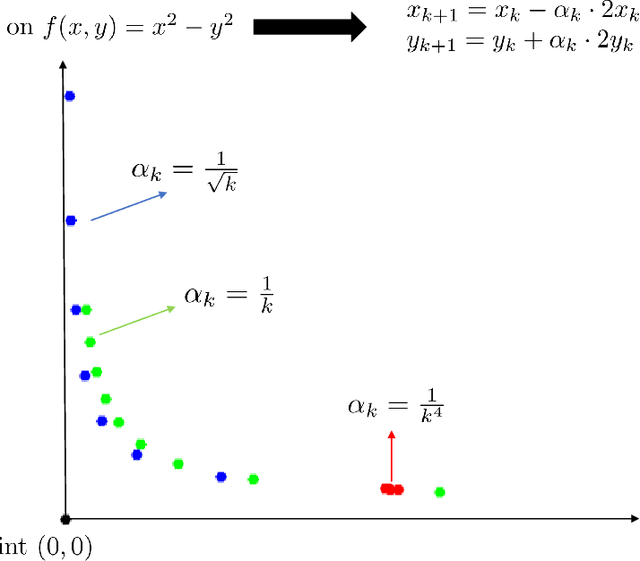
We establish that first-order methods avoid saddle points for almost all initializations. Our results apply to a wide variety of first-order methods, including gradient descent, block coordinate descent, mirror descent and variants thereof. The connecting thread is that such algorithms can be studied from a dynamical systems perspective in which appropriate instantiations of the Stable Manifold Theorem allow for a global stability analysis. Thus, neither access to second-order derivative information nor randomness beyond initialization is necessary to provably avoid saddle points.
DAGGER: A sequential algorithm for FDR control on DAGs
Oct 10, 2017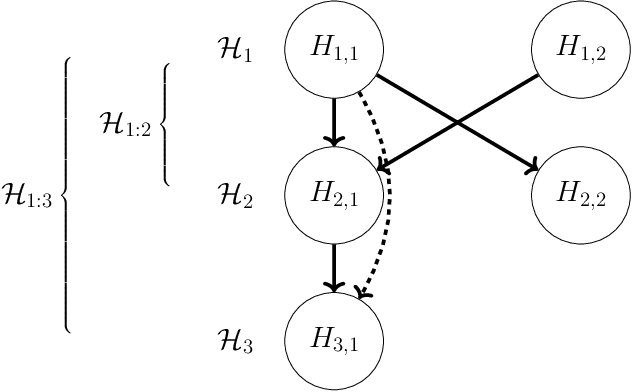

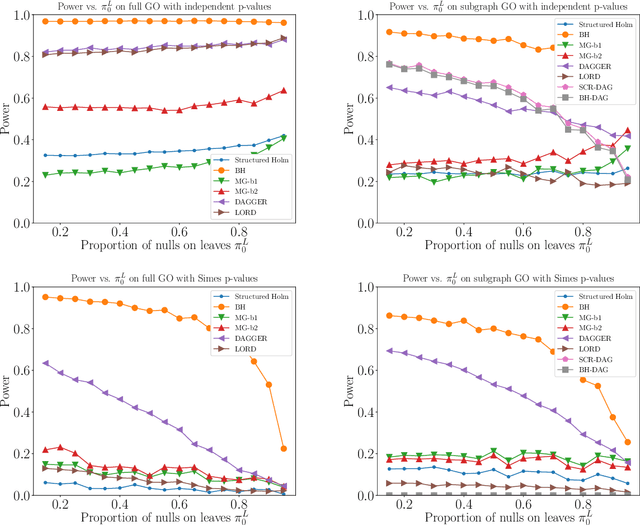
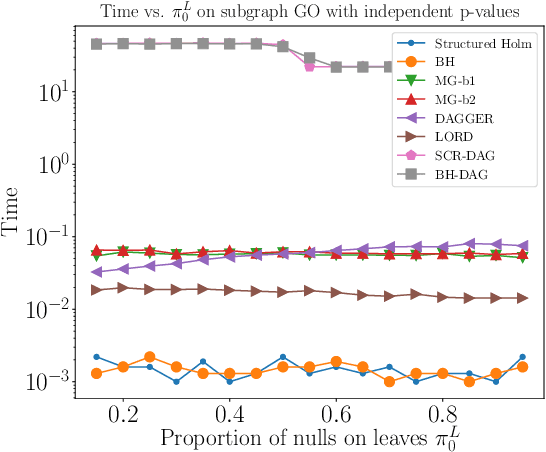
We propose a top-down algorithm for multiple testing on directed acyclic graphs (DAGs), where nodes represent hypotheses and edges specify a partial ordering in which hypotheses must be tested. The procedure is guaranteed to reject a sub-DAG with bounded false discovery rate (FDR) while satisfying the logical constraint that a rejected node's parents must also be rejected. It is designed for sequential testing settings, when the DAG structure is known a priori, but the p-values are obtained selectively (such as sequential conduction of experiments), but the algorithm is also applicable in non-sequential settings when all p-values can be calculated in advance (such as variable/model selection). Our DAGGER algorithm, shorthand for Greedily Evolving Rejections on DAGs, allows for independence, positive or arbitrary dependence of the p-values, and is guaranteed to work on two different types of DAGs: (a) intersection DAGs in which all nodes are intersection hypotheses, with parents being supersets of children, or (b) general DAGs in which all nodes may be elementary hypotheses. The DAGGER procedure has the appealing property that it specializes to known algorithms in the special cases of trees and line graphs, and simplifies to the classic Benjamini-Hochberg procedure when the DAG has no edges. We explore the empirical performance of DAGGER using simulations, as well as a real dataset corresponding to a gene ontology DAG, showing that it performs favorably in terms of time and power.