 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEBS: Multi-task End-to-end Bid Shading for Multi-slot Display Advertising
Mar 05, 2024



Online bidding and auction are crucial aspects of the online advertising industry. Conventionally, there is only one slot for ad display and most current studies focus on it. Nowadays, multi-slot display advertising is gradually becoming popular where many ads could be displayed in a list and shown as a whole to users. However, multi-slot display advertising leads to different cost-effectiveness. Advertisers have the incentive to adjust bid prices so as to win the most economical ad positions. In this study, we introduce bid shading into multi-slot display advertising for bid price adjustment with a Multi-task End-to-end Bid Shading(MEBS) method. We prove the optimality of our method theoretically and examine its performance experimentally. Through extensive offline and online experiments, we demonstrate the effectiveness and efficiency of our method, and we obtain a 7.01% lift in Gross Merchandise Volume, a 7.42% lift in Return on Investment, and a 3.26% lift in ad buy count.
CaMU: Disentangling Causal Effects in Deep Model Unlearning
Jan 30, 2024



Machine unlearning requires removing the information of forgetting data while keeping the necessary information of remaining data. Despite recent advancements in this area, existing methodologies mainly focus on the effect of removing forgetting data without considering the negative impact this can have on the information of the remaining data, resulting in significant performance degradation after data removal. Although some methods try to repair the performance of remaining data after removal, the forgotten information can also return after repair. Such an issue is due to the intricate intertwining of the forgetting and remaining data. Without adequately differentiating the influence of these two kinds of data on the model, existing algorithms take the risk of either inadequate removal of the forgetting data or unnecessary loss of valuable information from the remaining data. To address this shortcoming, the present study undertakes a causal analysis of the unlearning and introduces a novel framework termed Causal Machine Unlearning (CaMU). This framework adds intervention on the information of remaining data to disentangle the causal effects between forgetting data and remaining data. Then CaMU eliminates the causal impact associated with forgetting data while concurrently preserving the causal relevance of the remaining data. Comprehensive empirical results on various datasets and models suggest that CaMU enhances performance on the remaining data and effectively minimizes the influences of forgetting data. Notably, this work is the first to interpret deep model unlearning tasks from a new perspective of causality and provide a solution based on causal analysis, which opens up new possibilities for future research in deep model unlearning.
Complementary to Multiple Labels: A Correlation-Aware Correction Approach
Feb 25, 2023



\textit{Complementary label learning} (CLL) requires annotators to give \emph{irrelevant} labels instead of relevant labels for instances. Currently, CLL has shown its promising performance on multi-class data by estimating a transition matrix. However, current multi-class CLL techniques cannot work well on multi-labeled data since they assume each instance is associated with one label while each multi-labeled instance is relevant to multiple labels. Here, we show theoretically how the estimated transition matrix in multi-class CLL could be distorted in multi-labeled cases as they ignore co-existing relevant labels. Moreover, theoretical findings reveal that calculating a transition matrix from label correlations in \textit{multi-labeled CLL} (ML-CLL) needs multi-labeled data, while this is unavailable for ML-CLL. To solve this issue, we propose a two-step method to estimate the transition matrix from candidate labels. Specifically, we first estimate an initial transition matrix by decomposing the multi-label problem into a series of binary classification problems, then the initial transition matrix is corrected by label correlations to enforce the addition of relationships among labels. We further show that the proposal is classifier-consistent, and additionally introduce an MSE-based regularizer to alleviate the tendency of BCE loss overfitting to noises. Experimental results have demonstrated the effectiveness of the proposed method.
Positive-Unlabeled Learning using Random Forests via Recursive Greedy Risk Minimization
Oct 16, 2022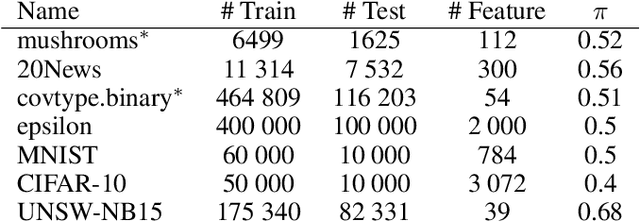
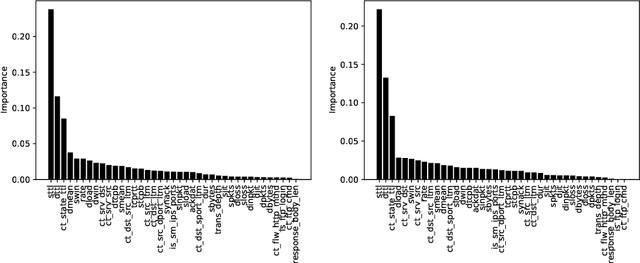
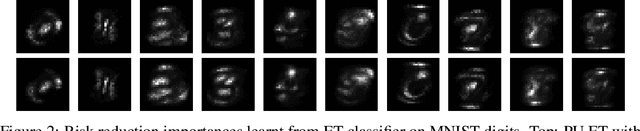
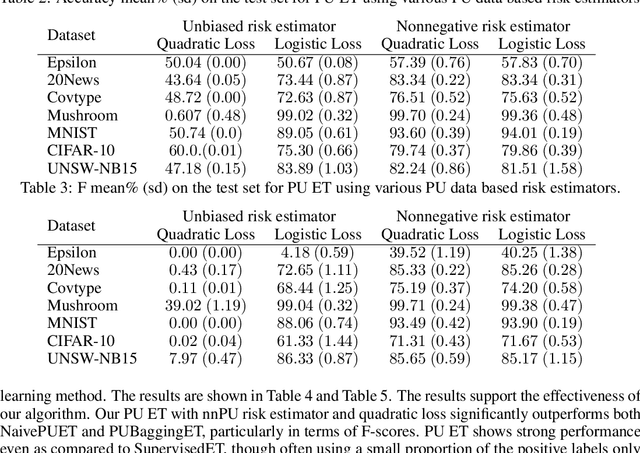
The need to learn from positive and unlabeled data, or PU learning, arises in many applications and has attracted increasing interest. While random forests are known to perform well on many tasks with positive and negative data, recent PU algorithms are generally based on deep neural networks, and the potential of tree-based PU learning is under-explored. In this paper, we propose new random forest algorithms for PU-learning. Key to our approach is a new interpretation of decision tree algorithms for positive and negative data as \emph{recursive greedy risk minimization algorithms}. We extend this perspective to the PU setting to develop new decision tree learning algorithms that directly minimizes PU-data based estimators for the expected risk. This allows us to develop an efficient PU random forest algorithm, PU extra trees. Our approach features three desirable properties: it is robust to the choice of the loss function in the sense that various loss functions lead to the same decision trees; it requires little hyperparameter tuning as compared to neural network based PU learning; it supports a feature importance that directly measures a feature's contribution to risk minimization. Our algorithms demonstrate strong performance on several datasets. Our code is available at \url{https://github.com/puetpaper/PUExtraTrees}.
Confidence Matters: Inspecting Backdoors in Deep Neural Networks via Distribution Transfer
Aug 13, 2022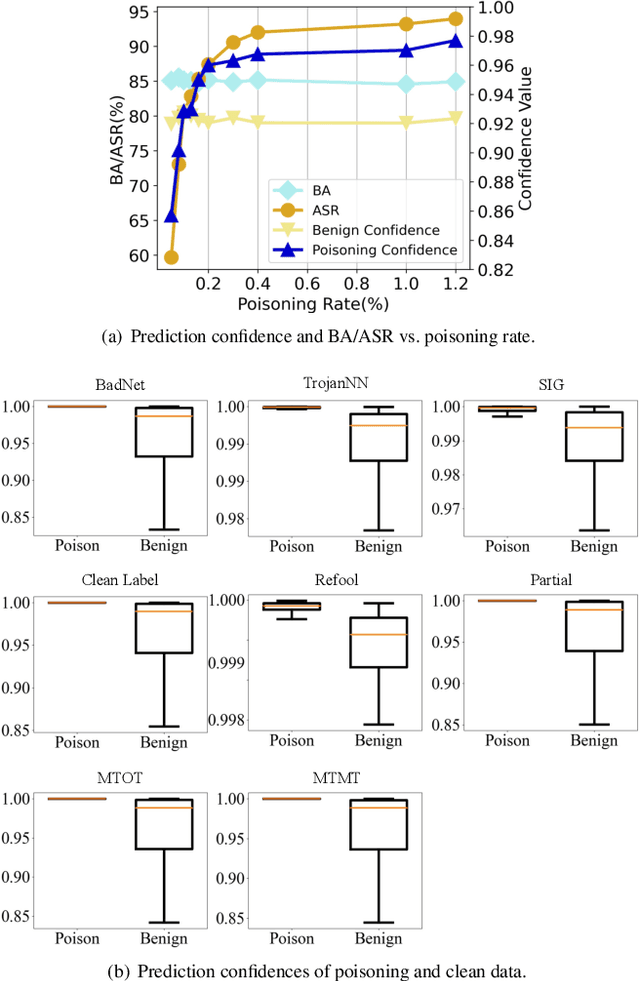
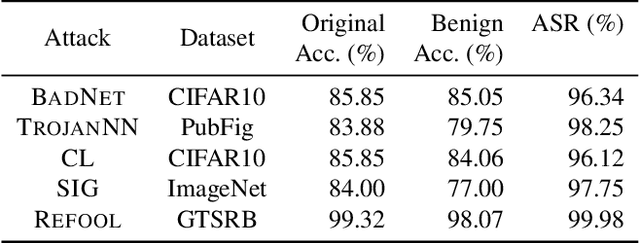
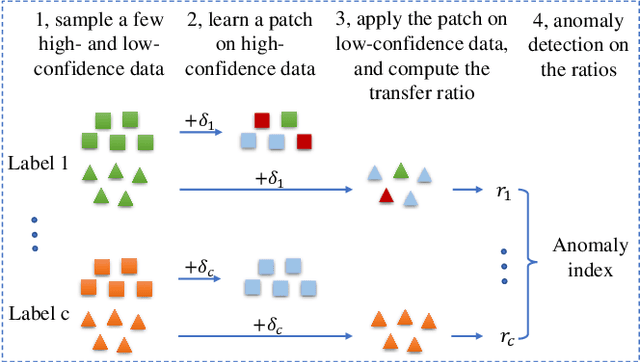

Backdoor attacks have been shown to be a serious security threat against deep learning models, and detecting whether a given model has been backdoored becomes a crucial task. Existing defenses are mainly built upon the observation that the backdoor trigger is usually of small size or affects the activation of only a few neurons. However, the above observations are violated in many cases especially for advanced backdoor attacks, hindering the performance and applicability of the existing defenses. In this paper, we propose a backdoor defense DTInspector built upon a new observation. That is, an effective backdoor attack usually requires high prediction confidence on the poisoned training samples, so as to ensure that the trained model exhibits the targeted behavior with a high probability. Based on this observation, DTInspector first learns a patch that could change the predictions of most high-confidence data, and then decides the existence of backdoor by checking the ratio of prediction changes after applying the learned patch on the low-confidence data. Extensive evaluations on five backdoor attacks, four datasets, and three advanced attacking types demonstrate the effectiveness of the proposed defense.
A Boosting Algorithm for Positive-Unlabeled Learning
May 19, 2022
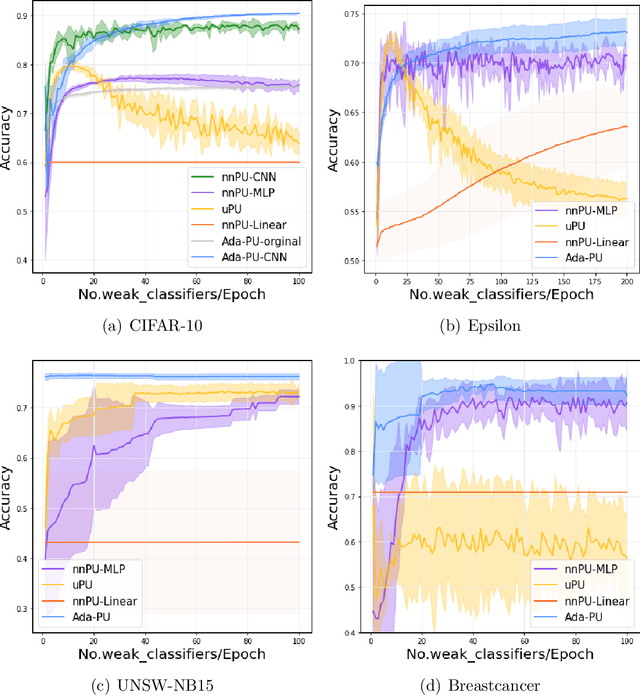

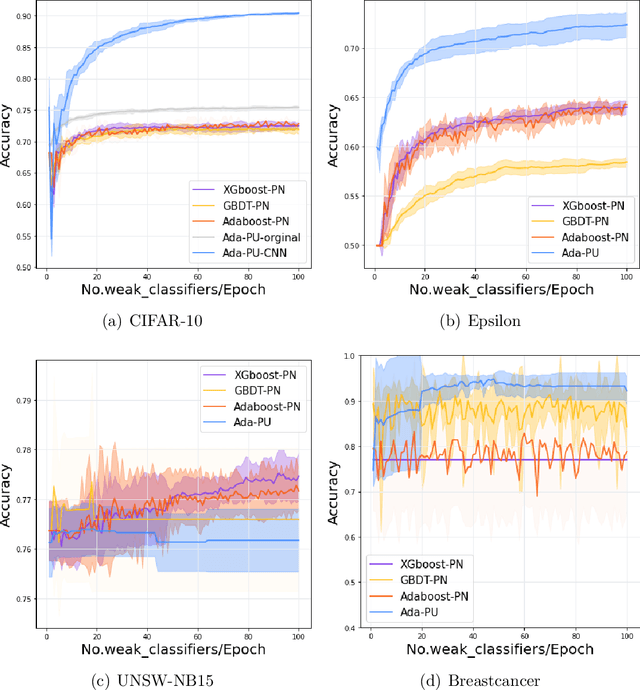
Positive-unlabeled (PU) learning deals with binary classification problems when only positive (P) and unlabeled (U) data are available. A lot of PU methods based on linear models and neural networks have been proposed; however, there still lacks study on how the theoretically sound boosting-style algorithms could work with P and U data. Considering that in some scenarios when neural networks cannot perform as good as boosting algorithms even with fully-supervised data, we propose a novel boosting algorithm for PU learning: Ada-PU, which compares against neural networks. Ada-PU follows the general procedure of AdaBoost while two different distributions of P data are maintained and updated. After a weak classifier is learned on the newly updated distribution, the corresponding combining weight for the final ensemble is estimated using only PU data. We demonstrated that with a smaller set of base classifiers, the proposed method is guaranteed to keep the theoretical properties of boosting algorithm. In experiments, we showed that Ada-PU outperforms neural networks on benchmark PU datasets. We also study a real-world dataset UNSW-NB15 in cyber security and demonstrated that Ada-PU has superior performance for malicious activities detection.
Single-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022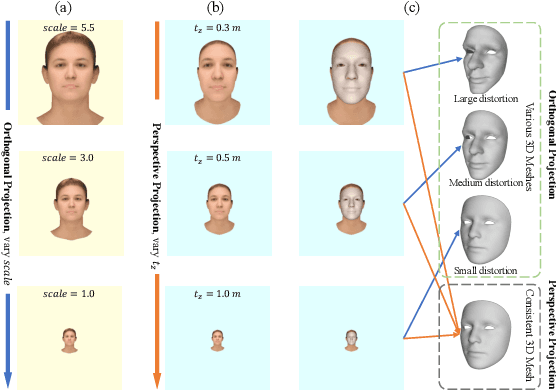
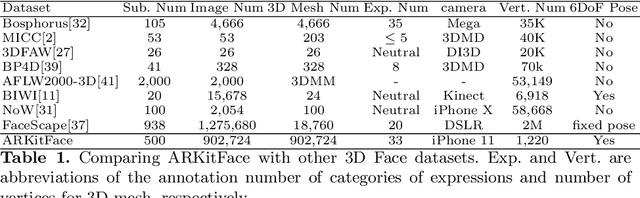
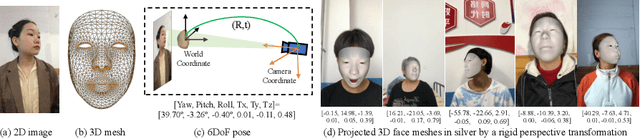

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.
Personalized On-Device E-health Analytics with Decentralized Block Coordinate Descent
Dec 17, 2021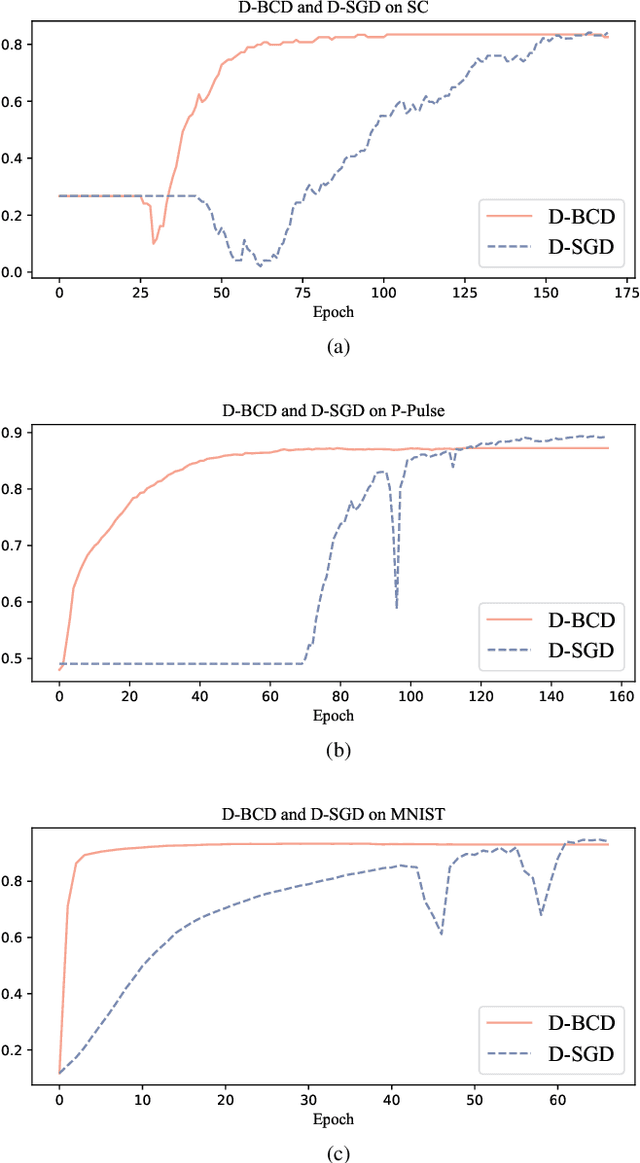
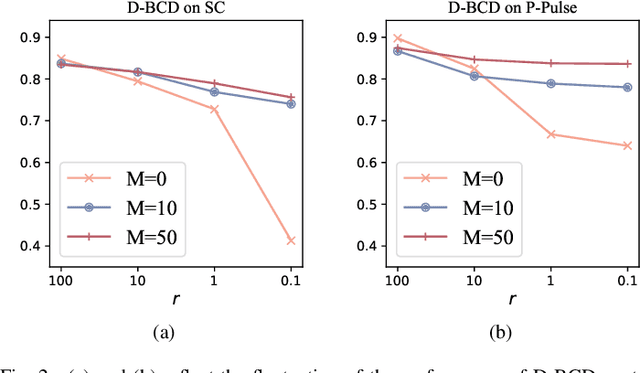
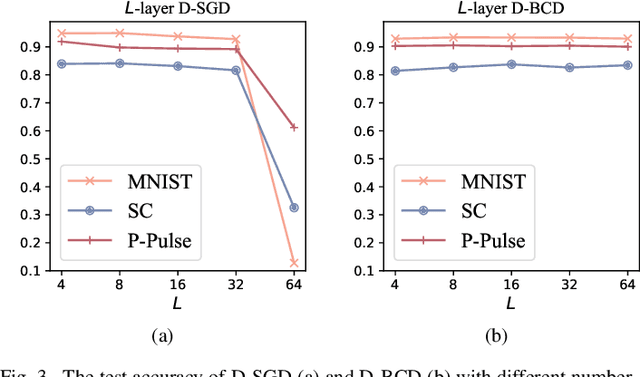
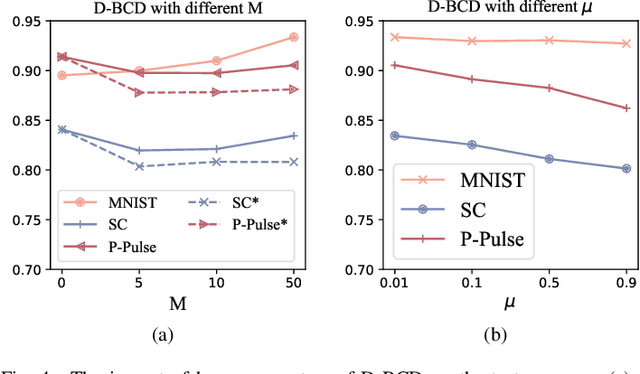
Actuated by the growing attention to personal healthcare and the pandemic, the popularity of E-health is proliferating. Nowadays, enhancement on medical diagnosis via machine learning models has been highly effective in many aspects of e-health analytics. Nevertheless, in the classic cloud-based/centralized e-health paradigms, all the data will be centrally stored on the server to facilitate model training, which inevitably incurs privacy concerns and high time delay. Distributed solutions like Decentralized Stochastic Gradient Descent (D-SGD) are proposed to provide safe and timely diagnostic results based on personal devices. However, methods like D-SGD are subject to the gradient vanishing issue and usually proceed slowly at the early training stage, thereby impeding the effectiveness and efficiency of training. In addition, existing methods are prone to learning models that are biased towards users with dense data, compromising the fairness when providing E-health analytics for minority groups. In this paper, we propose a Decentralized Block Coordinate Descent (D-BCD) learning framework that can better optimize deep neural network-based models distributed on decentralized devices for E-health analytics. Benchmarking experiments on three real-world datasets illustrate the effectiveness and practicality of our proposed D-BCD, where additional simulation study showcases the strong applicability of D-BCD in real-life E-health scenarios.
Active Refinement for Multi-Label Learning: A Pseudo-Label Approach
Sep 29, 2021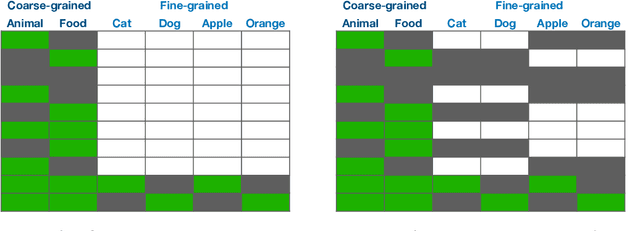
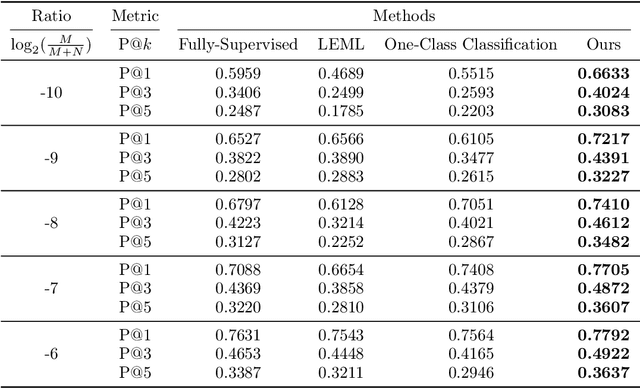
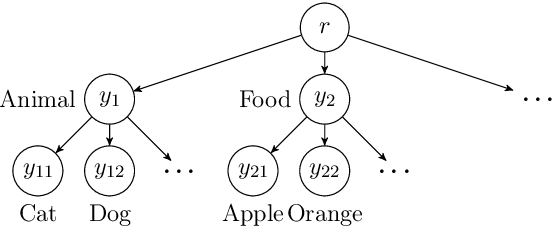
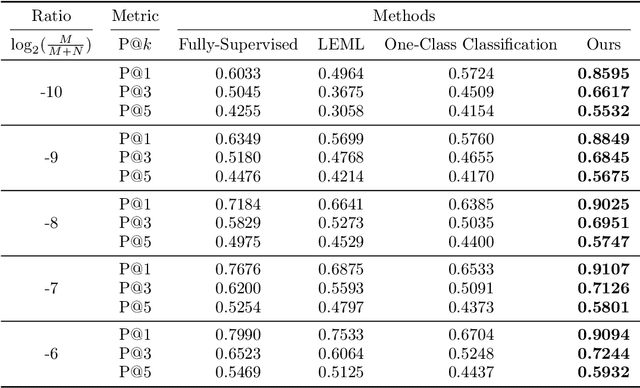
The goal of multi-label learning (MLL) is to associate a given instance with its relevant labels from a set of concepts. Previous works of MLL mainly focused on the setting where the concept set is assumed to be fixed, while many real-world applications require introducing new concepts into the set to meet new demands. One common need is to refine the original coarse concepts and split them into finer-grained ones, where the refinement process typically begins with limited labeled data for the finer-grained concepts. To address the need, we formalize the problem into a special weakly supervised MLL problem to not only learn the fine-grained concepts efficiently but also allow interactive queries to strategically collect more informative annotations to further improve the classifier. The key idea within our approach is to learn to assign pseudo-labels to the unlabeled entries, and in turn leverage the pseudo-labels to train the underlying classifier and to inform a better query strategy. Experimental results demonstrate that our pseudo-label approach is able to accurately recover the missing ground truth, boosting the prediction performance significantly over the baseline methods and facilitating a competitive active learning strategy.
A Cooperative-Competitive Multi-Agent Framework for Auto-bidding in Online Advertising
Jun 11, 2021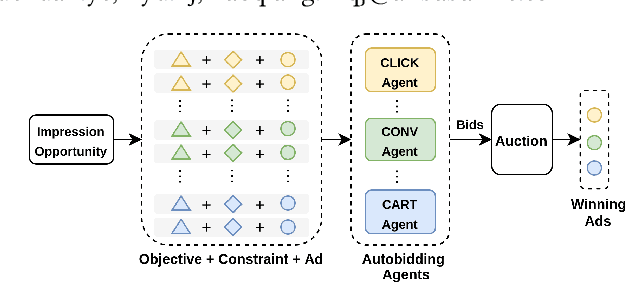
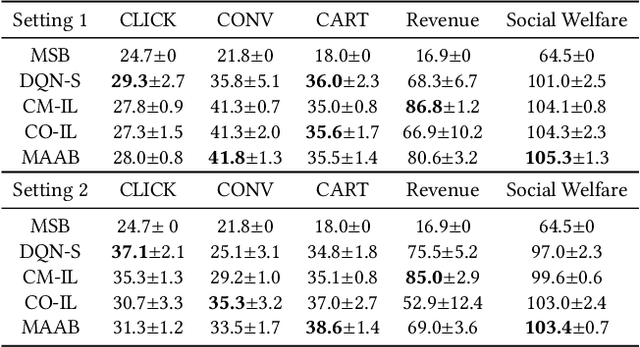
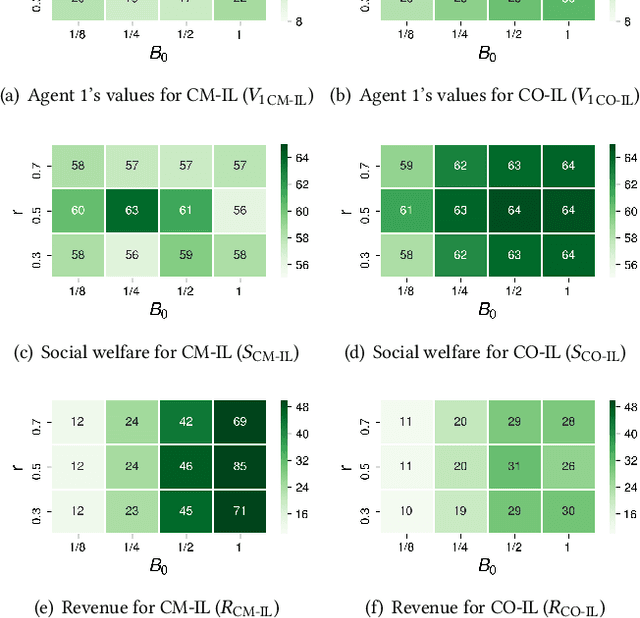

In online advertising, auto-bidding has become an essential tool for advertisers to optimize their preferred ad performance metrics by simply expressing the high-level campaign objectives and constraints. Previous works consider the design of auto-bidding agents from the single-agent view without modeling the mutual influence between agents. In this paper, we instead consider this problem from the perspective of a distributed multi-agent system, and propose a general Multi-Agent reinforcement learning framework for Auto-Bidding, namely MAAB, to learn the auto-bidding strategies. First, we investigate the competition and cooperation relation among auto-bidding agents, and propose temperature-regularized credit assignment for establishing a mixed cooperative-competitive paradigm. By carefully making a competition and cooperation trade-off among the agents, we can reach an equilibrium state that guarantees not only individual advertiser's utility but also the system performance (social welfare). Second, due to the observed collusion behaviors of bidding low prices underlying the cooperation, we further propose bar agents to set a personalized bidding bar for each agent, and then to alleviate the degradation of revenue. Third, to deploy MAAB to the large-scale advertising system with millions of advertisers, we propose a mean-field approach. By grouping advertisers with the same objective as a mean auto-bidding agent, the interactions among advertisers are greatly simplified, making it practical to train MAAB efficiently. Extensive experiments on the offline industrial dataset and Alibaba advertising platform demonstrate that our approach outperforms several baseline methods in terms of social welfare and guarantees the ad platform's revenue.