 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIU: A Restricted Data Access Unlearning for Imbalanced Data
Jun 12, 2024



With the increasing emphasis on data privacy, the significance of machine unlearning has grown substantially. Class unlearning, which involves enabling a trained model to forget data belonging to a specific class learned before, is important as classification tasks account for the majority of today's machine learning as a service (MLaaS). Retraining the model on the original data, excluding the data to be forgotten (a.k.a forgetting data), is a common approach to class unlearning. However, the availability of original data during the unlearning phase is not always guaranteed, leading to the exploration of class unlearning with restricted data access. While current unlearning methods with restricted data access usually generate proxy sample via the trained neural network classifier, they typically focus on training and forgetting balanced data. However, the imbalanced original data can cause trouble for these proxies and unlearning, particularly when the forgetting data consists predominantly of the majority class. To address this issue, we propose the GENerative Imbalanced Unlearning (GENIU) framework. GENIU utilizes a Variational Autoencoder (VAE) to concurrently train a proxy generator alongside the original model. These generated proxies accurately represent each class and are leveraged in the unlearning phase, eliminating the reliance on the original training data. To further mitigate the performance degradation resulting from forgetting the majority class, we introduce an in-batch tuning strategy that works with the generated proxies. GENIU is the first practical framework for class unlearning in imbalanced data settings and restricted data access, ensuring the preservation of essential information for future unlearning. Experimental results confirm the superiority of GENIU over existing methods, establishing its effectiveness in empirical scenarios.
Label-Agnostic Forgetting: A Supervision-Free Unlearning in Deep Models
Mar 31, 2024



Machine unlearning aims to remove information derived from forgotten data while preserving that of the remaining dataset in a well-trained model. With the increasing emphasis on data privacy, several approaches to machine unlearning have emerged. However, these methods typically rely on complete supervision throughout the unlearning process. Unfortunately, obtaining such supervision, whether for the forgetting or remaining data, can be impractical due to the substantial cost associated with annotating real-world datasets. This challenge prompts us to propose a supervision-free unlearning approach that operates without the need for labels during the unlearning process. Specifically, we introduce a variational approach to approximate the distribution of representations for the remaining data. Leveraging this approximation, we adapt the original model to eliminate information from the forgotten data at the representation level. To further address the issue of lacking supervision information, which hinders alignment with ground truth, we introduce a contrastive loss to facilitate the matching of representations between the remaining data and those of the original model, thus preserving predictive performance. Experimental results across various unlearning tasks demonstrate the effectiveness of our proposed method, Label-Agnostic Forgetting (LAF) without using any labels, which achieves comparable performance to state-of-the-art methods that rely on full supervision information. Furthermore, our approach excels in semi-supervised scenarios, leveraging limited supervision information to outperform fully supervised baselines. This work not only showcases the viability of supervision-free unlearning in deep models but also opens up a new possibility for future research in unlearning at the representation level.
A Boosting Algorithm for Positive-Unlabeled Learning
May 19, 2022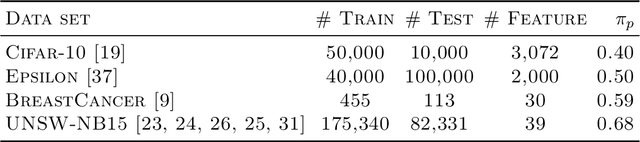
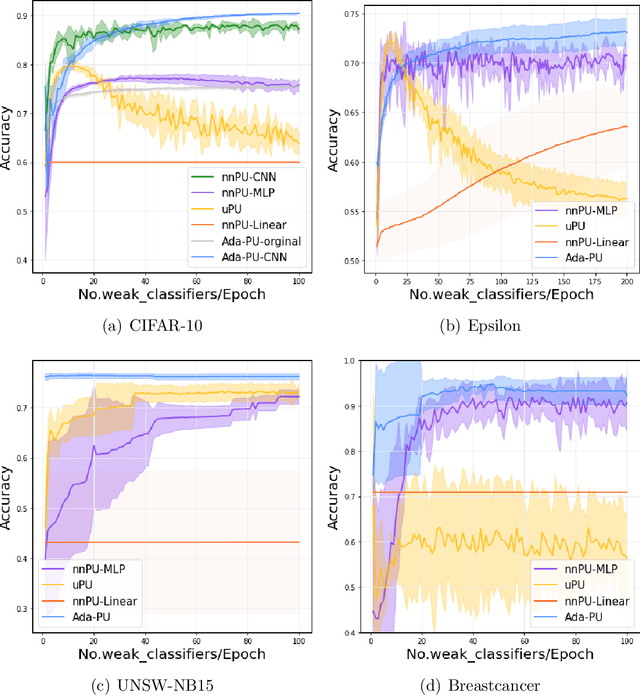

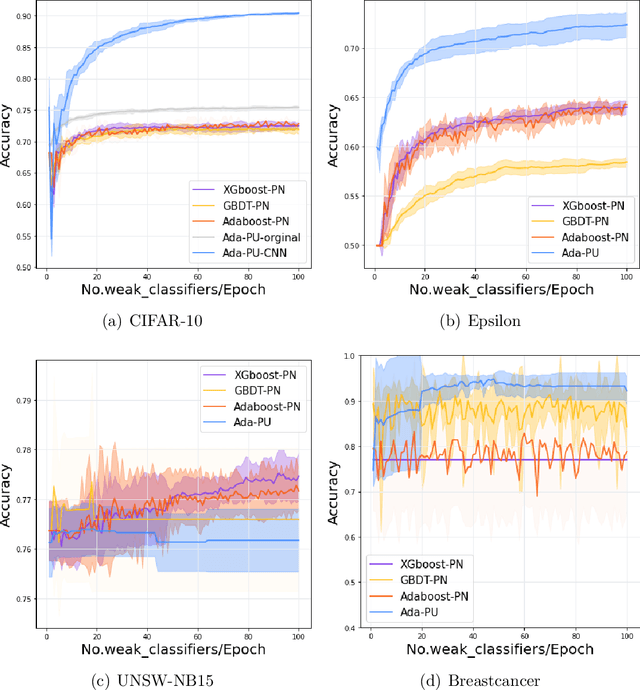
Positive-unlabeled (PU) learning deals with binary classification problems when only positive (P) and unlabeled (U) data are available. A lot of PU methods based on linear models and neural networks have been proposed; however, there still lacks study on how the theoretically sound boosting-style algorithms could work with P and U data. Considering that in some scenarios when neural networks cannot perform as good as boosting algorithms even with fully-supervised data, we propose a novel boosting algorithm for PU learning: Ada-PU, which compares against neural networks. Ada-PU follows the general procedure of AdaBoost while two different distributions of P data are maintained and updated. After a weak classifier is learned on the newly updated distribution, the corresponding combining weight for the final ensemble is estimated using only PU data. We demonstrated that with a smaller set of base classifiers, the proposed method is guaranteed to keep the theoretical properties of boosting algorithm. In experiments, we showed that Ada-PU outperforms neural networks on benchmark PU datasets. We also study a real-world dataset UNSW-NB15 in cyber security and demonstrated that Ada-PU has superior performance for malicious activities detection.