 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimWeaver: Zero-Shot RGB Sim-to-Real for Deformable Manipulation
Jun 13, 2026RGB sim-to-real for deformable manipulation has remained largely unsolved without real-world fine-tuning. We present SimWeaver, which trains zero-shot RGB VLA policies on 200 simulated demonstrations per task, reaching above 80% per-task and 91% average real-world success across 5 diverse deformable tasks including plastic-bag manipulation, without teleoperation or per-task calibration. SimWeaver combines a reliable measurement-backed simulator (SimWeaver-Sim) with an extensible asset framework supporting single-image generation(SimWeaver-Asset), a deterministic topology-aware trajectory synthesizer (SimWeaver-Syn), and a sim-to-real protocol with ISP-aware photometric augmentation (SimWeaver-Real). On silk grasping, the sim-trained policy reaches 100% under visual distribution shifts where real-data baselines drop to 9-70%, at two orders of magnitude lower per-trajectory cost. We will release SimWeaver and a representative asset subset. Project page: https://simweaver.github.io/
HoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition
Oct 24, 2019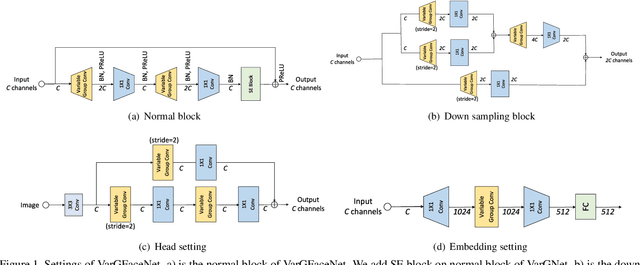
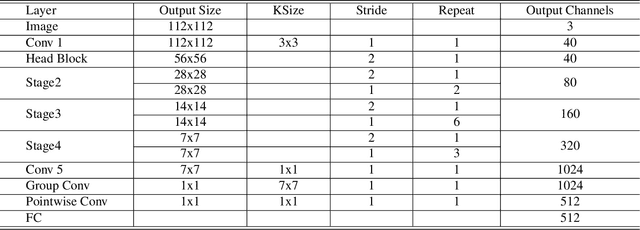
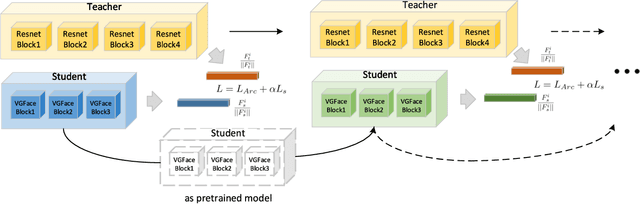

To improve the discriminative and generalization ability of lightweight network for face recognition, we propose an efficient variable group convolutional network called VarGFaceNet. Variable group convolution is introduced by VarGNet to solve the conflict between small computational cost and the unbalance of computational intensity inside a block. We employ variable group convolution to design our network which can support large scale face identification while reduce computational cost and parameters. Specifically, we use a head setting to reserve essential information at the start of the network and propose a particular embedding setting to reduce parameters of fully-connected layer for embedding. To enhance interpretation ability, we employ an equivalence of angular distillation loss to guide our lightweight network and we apply recursive knowledge distillation to relieve the discrepancy between the teacher model and the student model. The champion of deepglint-light track of LFR (2019) challenge demonstrates the effectiveness of our model and approach. Implementation of VarGFaceNet will be released at https://github.com/zma-c-137/VarGFaceNet soon.