 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariance Through Inference
Dec 15, 2021
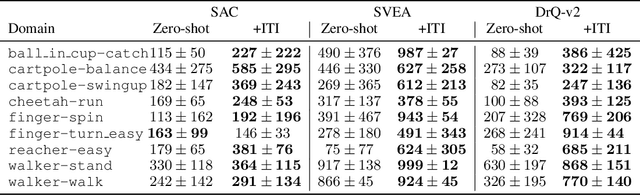
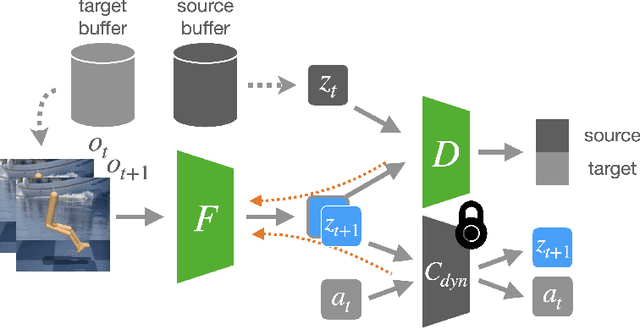
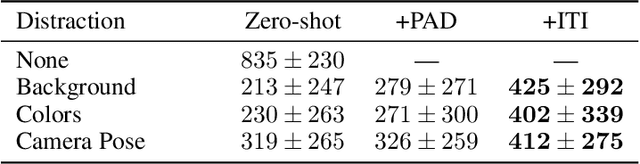
We introduce a general approach, called Invariance through Inference, for improving the test-time performance of an agent in deployment environments with unknown perceptual variations. Instead of producing invariant visual features through interpolation, invariance through inference turns adaptation at deployment-time into an unsupervised learning problem. This is achieved in practice by deploying a straightforward algorithm that tries to match the distribution of latent features to the agent's prior experience, without relying on paired data. Although simple, we show that this idea leads to surprising improvements on a variety of adaptation scenarios without access to deployment-time rewards, including changes in camera poses and lighting conditions. Results are presented on challenging distractor control suite, a robotics environment with image-based observations.
Self-Supervised Camera Self-Calibration from Video
Dec 06, 2021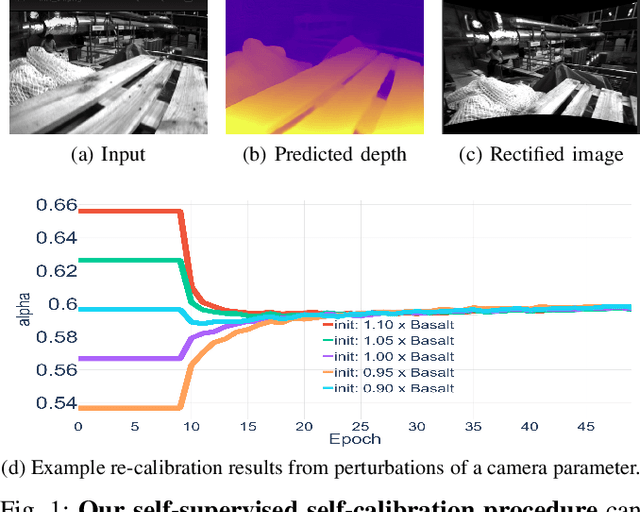
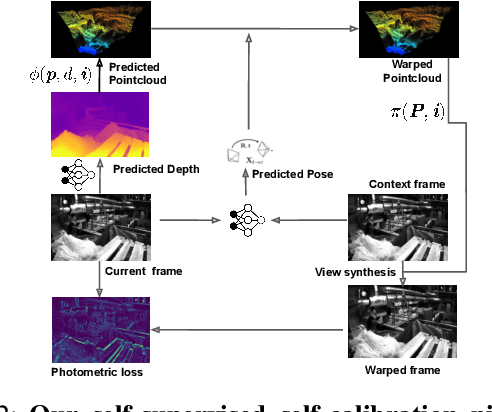
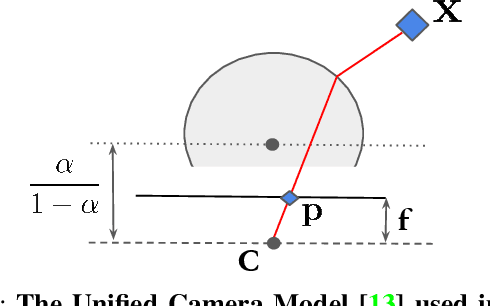

Camera calibration is integral to robotics and computer vision algorithms that seek to infer geometric properties of the scene from visual input streams. In practice, calibration is a laborious procedure requiring specialized data collection and careful tuning. This process must be repeated whenever the parameters of the camera change, which can be a frequent occurrence for mobile robots and autonomous vehicles. In contrast, self-supervised depth and ego-motion estimation approaches can bypass explicit calibration by inferring per-frame projection models that optimize a view synthesis objective. In this paper, we extend this approach to explicitly calibrate a wide range of cameras from raw videos in the wild. We propose a learning algorithm to regress per-sequence calibration parameters using an efficient family of general camera models. Our procedure achieves self-calibration results with sub-pixel reprojection error, outperforming other learning-based methods. We validate our approach on a wide variety of camera geometries, including perspective, fisheye, and catadioptric. Finally, we show that our approach leads to improvements in the downstream task of depth estimation, achieving state-of-the-art results on the EuRoC dataset with greater computational efficiency than contemporary methods.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
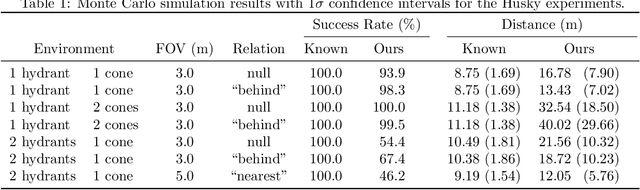

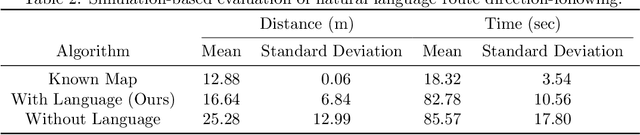
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
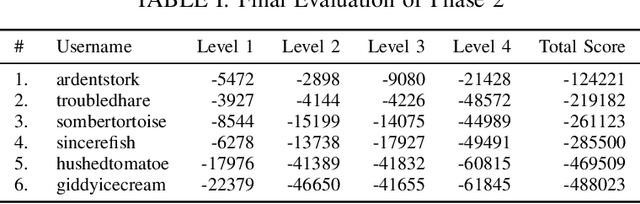
Benchmarking Structured Policies and Policy Optimization for Real-World Dexterous Object Manipulation
May 05, 2021

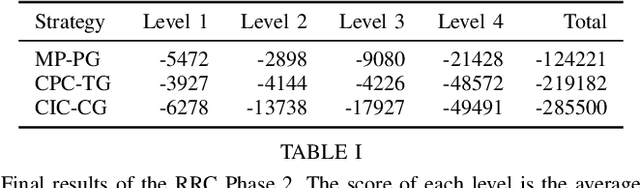
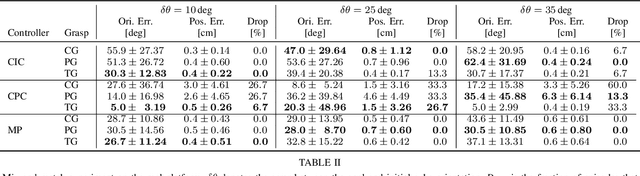
Dexterous manipulation is a challenging and important problem in robotics. While data-driven methods are a promising approach, current benchmarks require simulation or extensive engineering support due to the sample inefficiency of popular methods. We present benchmarks for the TriFinger system, an open-source robotic platform for dexterous manipulation and the focus of the 2020 Real Robot Challenge. The benchmarked methods, which were successful in the challenge, can be generally described as structured policies, as they combine elements of classical robotics and modern policy optimization. This inclusion of inductive biases facilitates sample efficiency, interpretability, reliability and high performance. The key aspects of this benchmarking is validation of the baselines across both simulation and the real system, thorough ablation study over the core features of each solution, and a retrospective analysis of the challenge as a manipulation benchmark. The code and demo videos for this work can be found on our website (https://sites.google.com/view/benchmark-rrc).
Boosting Contrastive Self-Supervised Learning with False Negative Cancellation
Nov 23, 2020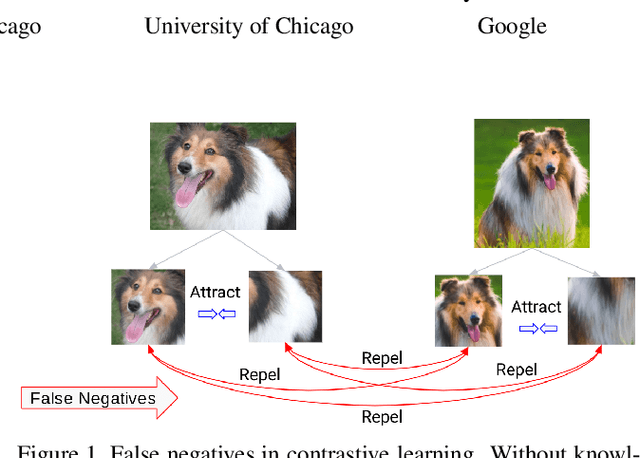

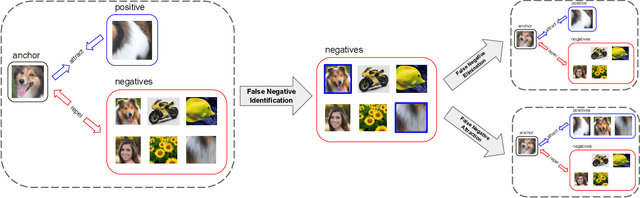

Self-supervised representation learning has witnessed significant leaps fueled by recent progress in Contrastive learning, which seeks to learn transformations that embed positive input pairs nearby, while pushing negative pairs far apart. While positive pairs can be generated reliably (e.g., as different views of the same image), it is difficult to accurately establish negative pairs, defined as samples from different images regardless of their semantic content or visual features. A fundamental problem in contrastive learning is mitigating the effects of false negatives. Contrasting false negatives induces two critical issues in representation learning: discarding semantic information and slow convergence. In this paper, we study this problem in detail and propose novel approaches to mitigate the effects of false negatives. The proposed methods exhibit consistent and significant improvements over existing contrastive learning-based models. They achieve new state-of-the-art performance on ImageNet evaluations, achieving 5.8% absolute improvement in top-1 accuracy over the previous state-of-the-art when finetuning with 1% labels, as well as transferring to downstream tasks.
Pow-Wow: A Dataset and Study on Collaborative Communication in Pommerman
Sep 13, 2020
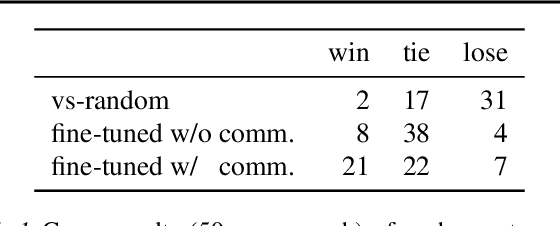
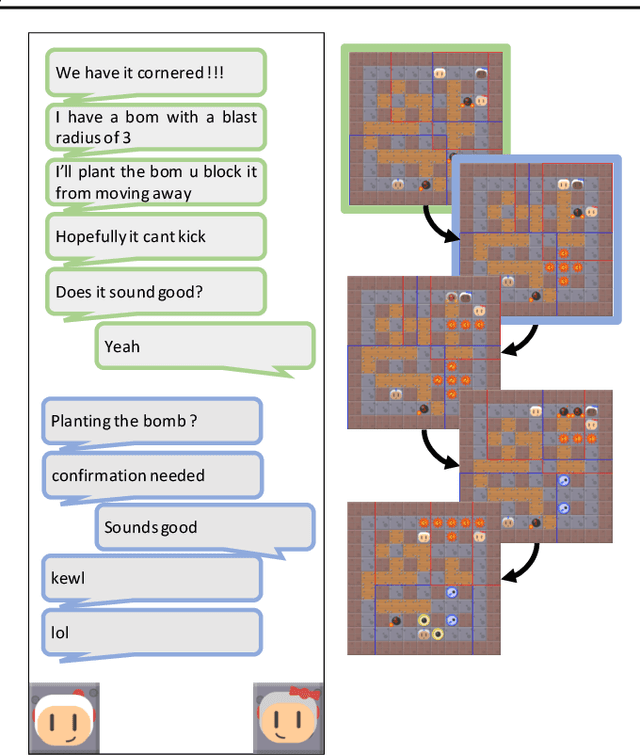
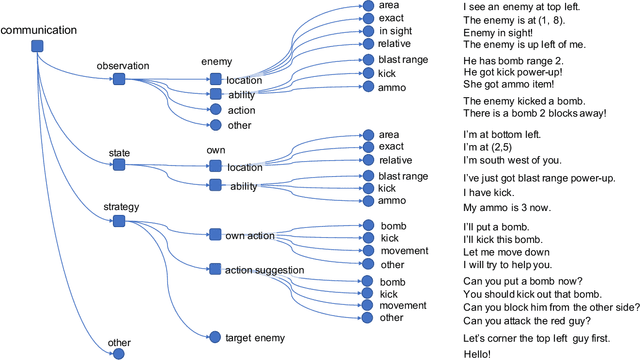
In multi-agent learning, agents must coordinate with each other in order to succeed. For humans, this coordination is typically accomplished through the use of language. In this work we perform a controlled study of human language use in a competitive team-based game, and search for useful lessons for structuring communication protocol between autonomous agents. We construct Pow-Wow, a new dataset for studying situated goal-directed human communication. Using the Pommerman game environment, we enlisted teams of humans to play against teams of AI agents, recording their observations, actions, and communications. We analyze the types of communications which result in effective game strategies, annotate them accordingly, and present corpus-level statistical analysis of how trends in communications affect game outcomes. Based on this analysis, we design a communication policy for learning agents, and show that agents which utilize communication achieve higher win-rates against baseline systems than those which do not.
Integrated Benchmarking and Design for Reproducible and Accessible Evaluation of Robotic Agents
Sep 09, 2020

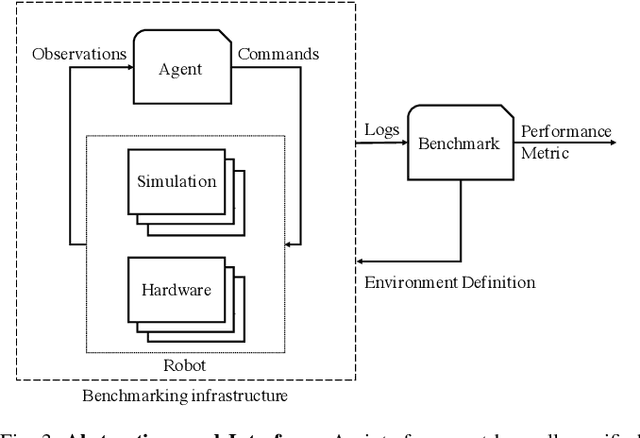
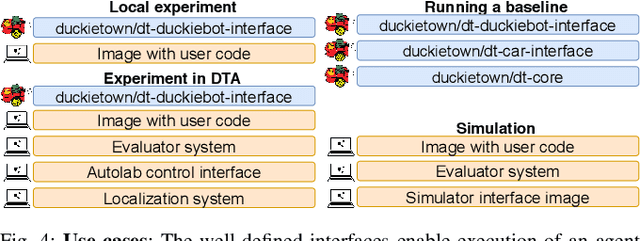
As robotics matures and increases in complexity, it is more necessary than ever that robot autonomy research be reproducible. Compared to other sciences, there are specific challenges to benchmarking autonomy, such as the complexity of the software stacks, the variability of the hardware and the reliance on data-driven techniques, amongst others. In this paper, we describe a new concept for reproducible robotics research that integrates development and benchmarking, so that reproducibility is obtained "by design" from the beginning of the research/development processes. We first provide the overall conceptual objectives to achieve this goal and then a concrete instance that we have built: the DUCKIENet. One of the central components of this setup is the Duckietown Autolab, a remotely accessible standardized setup that is itself also relatively low-cost and reproducible. When evaluating agents, careful definition of interfaces allows users to choose among local versus remote evaluation using simulation, logs, or remote automated hardware setups. We validate the system by analyzing the repeatability of experiments conducted using the infrastructure and show that there is low variance across different robot hardware and across different remote labs.
Concurrent Training Improves the Performance of Behavioral Cloning from Observation
Aug 03, 2020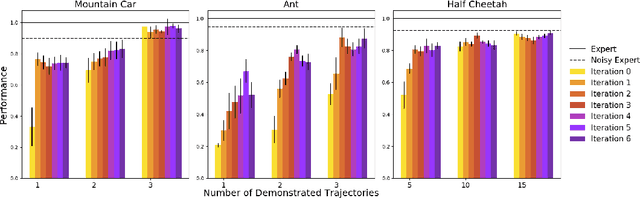
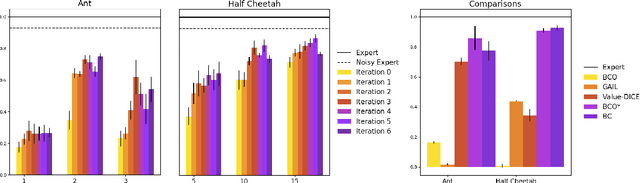
Learning from demonstration is widely used as an efficient way for robots to acquire new skills. However, it typically requires that demonstrations provide full access to the state and action sequences. In contrast, learning from observation offers a way to utilize unlabeled demonstrations (e.g., video) to perform imitation learning. One approach to this is behavioral cloning from observation (BCO). The original implementation of BCO proceeds by first learning an inverse dynamics model and then using that model to estimate action labels, thereby reducing the problem to behavioral cloning. However, existing approaches to BCO require a large number of initial interactions in the first step. Here, we provide a novel theoretical analysis of BCO, introduce a modification BCO*, and show that in the semi-supervised setting, BCO* can concurrently improve both its estimate for the inverse dynamics model and the expert policy. This result allows us to eliminate the dependence on initial interactions and dramatically improve the sample complexity of BCO. We evaluate the effectiveness of our algorithm through experiments on various benchmark domains. The results demonstrate that concurrent training not only improves over the performance of BCO but also results in performance that is competitive with state-of-the-art imitation learning methods such as GAIL and Value-Dice.
Residual Policy Learning for Shared Autonomy
Apr 10, 2020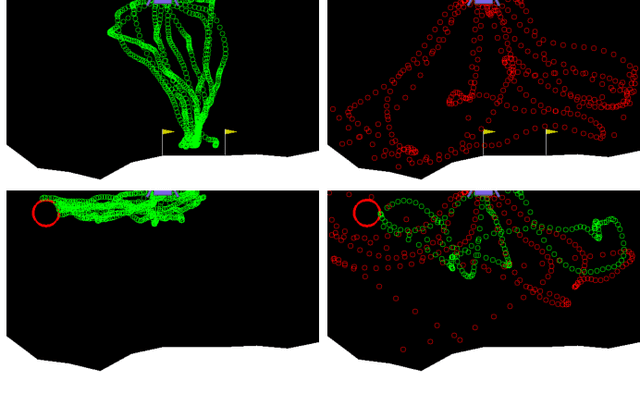
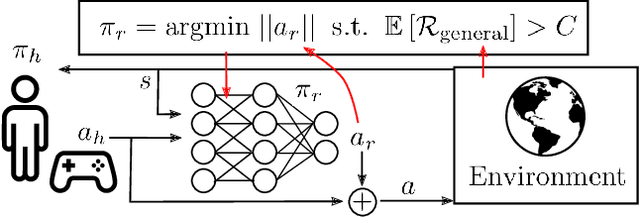

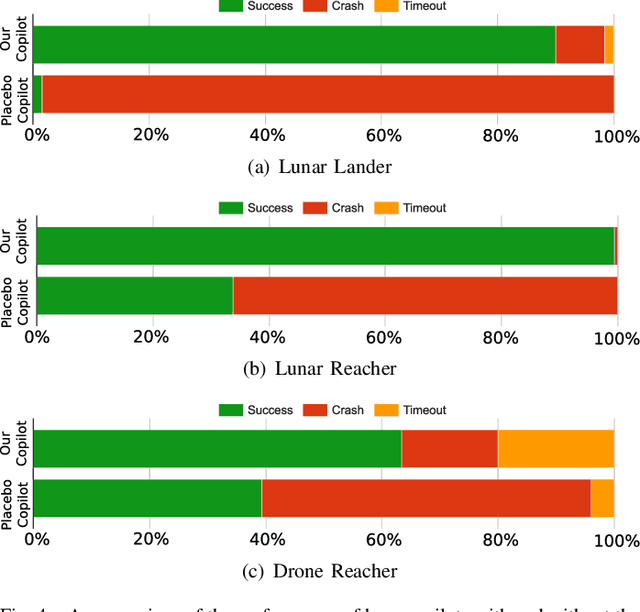
Shared autonomy provides an effective framework for human-robot collaboration that takes advantage of the complementary strengths of humans and robots to achieve common goals. Many existing approaches to shared autonomy make restrictive assumptions that the goal space, environment dynamics, or human policy are known a priori, or are limited to discrete action spaces, preventing those methods from scaling to complicated real world environments. We propose a model-free, residual policy learning algorithm for shared autonomy that alleviates the need for these assumptions. Our agents are trained to minimally adjust the human's actions such that a set of goal-agnostic constraints are satisfied. We test our method in two continuous control environments: LunarLander, a 2D flight control domain, and a 6-DOF quadrotor reaching task. In experiments with human and surrogate pilots, our method significantly improves task performance even though the agent has no explicit or implicit knowledge of the human's goal. These results highlight the ability of model-free deep reinforcement learning to realize assistive agents suited to complicated continuous control settings with minimal knowledge of user intent.