 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCushSense: Soft, Stretchable, and Comfortable Tactile-Sensing Skin for Physical Human-Robot Interaction
May 06, 2024



Whole-arm tactile feedback is crucial for robots to ensure safe physical interaction with their surroundings. This paper introduces CushSense, a fabric-based soft and stretchable tactile-sensing skin designed for physical human-robot interaction (pHRI) tasks such as robotic caregiving. Using stretchable fabric and hyper-elastic polymer, CushSense identifies contacts by monitoring capacitive changes due to skin deformation. CushSense is cost-effective ($\sim$US\$7 per taxel) and easy to fabricate. We detail the sensor design and fabrication process and perform characterization, highlighting its high sensing accuracy (relative error of 0.58%) and durability (0.054% accuracy drop after 1000 interactions). We also present a user study underscoring its perceived safety and comfort for the assistive task of limb manipulation. We open source all sensor-related resources on https://emprise.cs.cornell.edu/cushsense.
RABBIT: A Robot-Assisted Bed Bathing System with Multimodal Perception and Integrated Compliance
Jan 26, 2024This paper introduces RABBIT, a novel robot-assisted bed bathing system designed to address the growing need for assistive technologies in personal hygiene tasks. It combines multimodal perception and dual (software and hardware) compliance to perform safe and comfortable physical human-robot interaction. Using RGB and thermal imaging to segment dry, soapy, and wet skin regions accurately, RABBIT can effectively execute washing, rinsing, and drying tasks in line with expert caregiving practices. Our system includes custom-designed motion primitives inspired by human caregiving techniques, and a novel compliant end-effector called Scrubby, optimized for gentle and effective interactions. We conducted a user study with 12 participants, including one participant with severe mobility limitations, demonstrating the system's effectiveness and perceived comfort. Supplementary material and videos can be found on our website https://emprise.cs.cornell.edu/rabbit.
Real Robot Challenge 2021: Cartesian Position Control with Triangle Grasp and Trajectory Interpolation
Mar 19, 2022
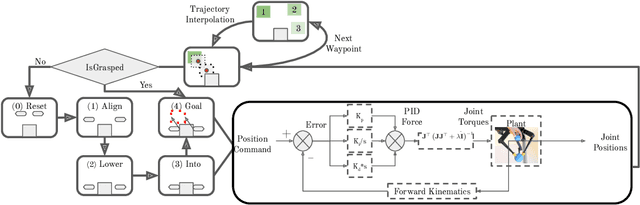


We present our runner-up approach for the Real Robot Challenge 2021. We build upon our previous approach used in Real Robot Challenge 2020. To solve the task of sequential goal-reaching we focus on two aspects to achieving near-optimal trajectory: Grasp stability and Controller performance. In the RRC 2021 simulated challenge, our method relied on a hand-designed Pinch grasp combined with Trajectory Interpolation for better stability during the motion for fast goal-reaching. In Stage 1, we observe reverting to a Triangular grasp to provide a more stable grasp when combined with Trajectory Interpolation, possibly due to the sim2real gap. The video demonstration for our approach is available at https://youtu.be/dlOueoaRWrM. The code is publicly available at https://github.com/madan96/benchmark-rrc.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

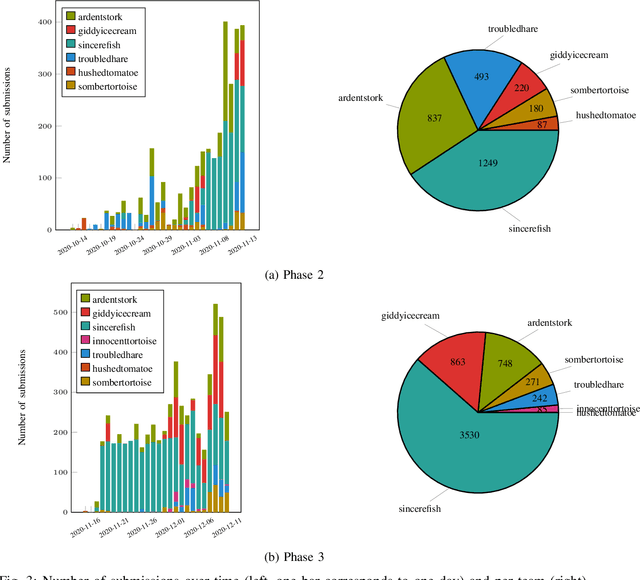
Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Benchmarking Structured Policies and Policy Optimization for Real-World Dexterous Object Manipulation
May 05, 2021

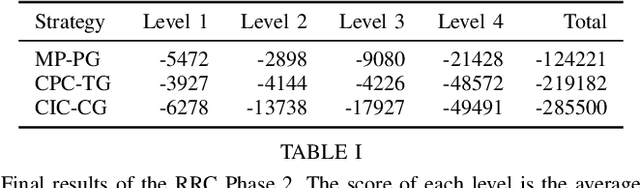
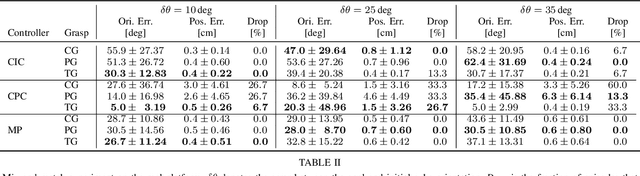
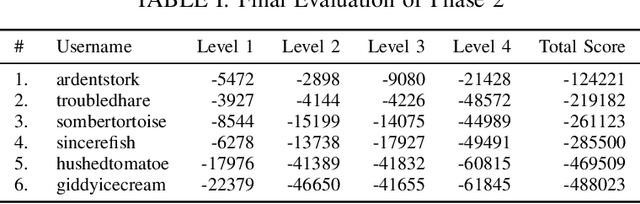
Dexterous manipulation is a challenging and important problem in robotics. While data-driven methods are a promising approach, current benchmarks require simulation or extensive engineering support due to the sample inefficiency of popular methods. We present benchmarks for the TriFinger system, an open-source robotic platform for dexterous manipulation and the focus of the 2020 Real Robot Challenge. The benchmarked methods, which were successful in the challenge, can be generally described as structured policies, as they combine elements of classical robotics and modern policy optimization. This inclusion of inductive biases facilitates sample efficiency, interpretability, reliability and high performance. The key aspects of this benchmarking is validation of the baselines across both simulation and the real system, thorough ablation study over the core features of each solution, and a retrospective analysis of the challenge as a manipulation benchmark. The code and demo videos for this work can be found on our website (https://sites.google.com/view/benchmark-rrc).
Multimodal Trajectory Prediction via Topological Invariance for Navigation at Uncontrolled Intersections
Nov 08, 2020
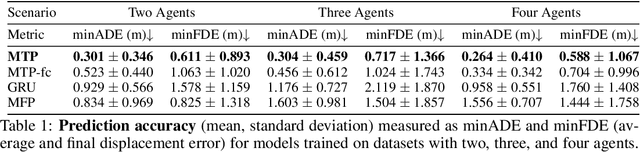
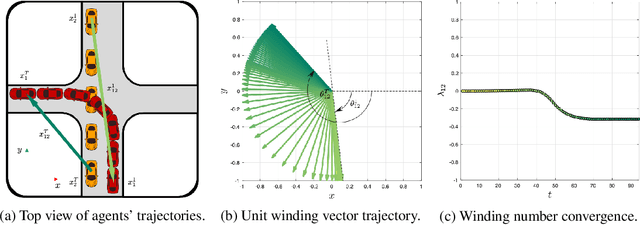
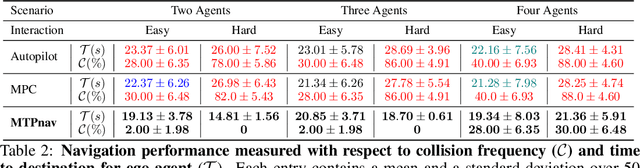
We focus on decentralized navigation among multiple non-communicating rational agents at \emph{uncontrolled} intersections, i.e., street intersections without traffic signs or signals. Avoiding collisions in such domains relies on the ability of agents to predict each others' intentions reliably, and react quickly. Multiagent trajectory prediction is NP-hard whereas the sample complexity of existing data-driven approaches limits their applicability. Our key insight is that the geometric structure of the intersection and the incentive of agents to move efficiently and avoid collisions (rationality) reduces the space of likely behaviors, effectively relaxing the problem of trajectory prediction. In this paper, we collapse the space of multiagent trajectories at an intersection into a set of modes representing different classes of multiagent behavior, formalized using a notion of topological invariance. Based on this formalism, we design Multiple Topologies Prediction (MTP), a data-driven trajectory-prediction mechanism that reconstructs trajectory representations of high-likelihood modes in multiagent intersection scenes. We show that MTP outperforms a state-of-the-art multimodal trajectory prediction baseline (MFP) in terms of prediction accuracy by 78.24% on a challenging simulated dataset. Finally, we show that MTP enables our optimization-based planner, MTPnav, to achieve collision-free and time-efficient navigation across a variety of challenging intersection scenarios on the CARLA simulator.
ExTra: Transfer-guided Exploration
Jun 27, 2019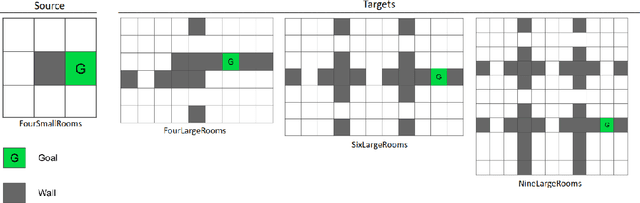
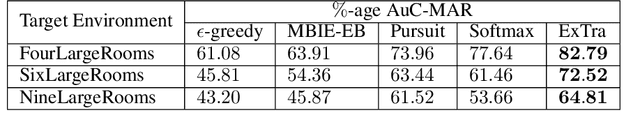
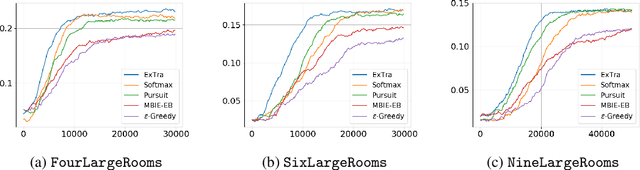

In this work we present a novel approach for transfer-guided exploration in reinforcement learning that is inspired by the human tendency to leverage experiences from similar encounters in the past while navigating a new task. Given an optimal policy in a related task-environment, we show that its bisimulation distance from the current task-environment gives a lower bound on the optimal advantage of state-action pairs in the current task-environment. Transfer-guided Exploration (ExTra) samples actions from a Softmax distribution over these lower bounds. In this way, actions with potentially higher optimum advantage are sampled more frequently. In our experiments on gridworld environments, we demonstrate that given access to an optimal policy in a related task-environment, ExTra can outperform popular domain-specific exploration strategies viz. epsilon greedy, Model-Based Interval Estimation - Exploration Based (MBIE-EB), Pursuit and Boltzmann in terms of sample complexity and rate of convergence. We further show that ExTra is robust to choices of source task and shows a graceful degradation of performance as the dissimilarity of the source task increases. We also demonstrate that ExTra, when used alongside traditional exploration algorithms, improves their rate of convergence. Thus it is capable of complimenting the efficacy of traditional exploration algorithms.