 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Improve My Code? Optimizing Programs with Local Search
Jul 10, 2023



This paper introduces a local search method for improving an existing program with respect to a measurable objective. Program Optimization with Locally Improving Search (POLIS) exploits the structure of a program, defined by its lines. POLIS improves a single line of the program while keeping the remaining lines fixed, using existing brute-force synthesis algorithms, and continues iterating until it is unable to improve the program's performance. POLIS was evaluated with a 27-person user study, where participants wrote programs attempting to maximize the score of two single-agent games: Lunar Lander and Highway. POLIS was able to substantially improve the participants' programs with respect to the game scores. A proof-of-concept demonstration on existing Stack Overflow code measures applicability in real-world problems. These results suggest that POLIS could be used as a helpful programming assistant for programming problems with measurable objectives.
Automatic Noise Filtering with Dynamic Sparse Training in Deep Reinforcement Learning
Feb 13, 2023Tomorrow's robots will need to distinguish useful information from noise when performing different tasks. A household robot for instance may continuously receive a plethora of information about the home, but needs to focus on just a small subset to successfully execute its current chore. Filtering distracting inputs that contain irrelevant data has received little attention in the reinforcement learning literature. To start resolving this, we formulate a problem setting in reinforcement learning called the $\textit{extremely noisy environment}$ (ENE), where up to $99\%$ of the input features are pure noise. Agents need to detect which features provide task-relevant information about the state of the environment. Consequently, we propose a new method termed $\textit{Automatic Noise Filtering}$ (ANF), which uses the principles of dynamic sparse training in synergy with various deep reinforcement learning algorithms. The sparse input layer learns to focus its connectivity on task-relevant features, such that ANF-SAC and ANF-TD3 outperform standard SAC and TD3 by a large margin, while using up to $95\%$ fewer weights. Furthermore, we devise a transfer learning setting for ENEs, by permuting all features of the environment after 1M timesteps to simulate the fact that other information sources can become relevant as the world evolves. Again, ANF surpasses the baselines in final performance and sample complexity. Our code is available at https://github.com/bramgrooten/automatic-noise-filtering
Learning from Multiple Independent Advisors in Multi-agent Reinforcement Learning
Jan 26, 2023



Multi-agent reinforcement learning typically suffers from the problem of sample inefficiency, where learning suitable policies involves the use of many data samples. Learning from external demonstrators is a possible solution that mitigates this problem. However, most prior approaches in this area assume the presence of a single demonstrator. Leveraging multiple knowledge sources (i.e., advisors) with expertise in distinct aspects of the environment could substantially speed up learning in complex environments. This paper considers the problem of simultaneously learning from multiple independent advisors in multi-agent reinforcement learning. The approach leverages a two-level Q-learning architecture, and extends this framework from single-agent to multi-agent settings. We provide principled algorithms that incorporate a set of advisors by both evaluating the advisors at each state and subsequently using the advisors to guide action selection. We also provide theoretical convergence and sample complexity guarantees. Experimentally, we validate our approach in three different test-beds and show that our algorithms give better performances than baselines, can effectively integrate the combined expertise of different advisors, and learn to ignore bad advice.
Safe Evaluation For Offline Learning: Are We Ready To Deploy?
Dec 16, 2022The world currently offers an abundance of data in multiple domains, from which we can learn reinforcement learning (RL) policies without further interaction with the environment. RL agents learning offline from such data is possible but deploying them while learning might be dangerous in domains where safety is critical. Therefore, it is essential to find a way to estimate how a newly-learned agent will perform if deployed in the target environment before actually deploying it and without the risk of overestimating its true performance. To achieve this, we introduce a framework for safe evaluation of offline learning using approximate high-confidence off-policy evaluation (HCOPE) to estimate the performance of offline policies during learning. In our setting, we assume a source of data, which we split into a train-set, to learn an offline policy, and a test-set, to estimate a lower-bound on the offline policy using off-policy evaluation with bootstrapping. A lower-bound estimate tells us how good a newly-learned target policy would perform before it is deployed in the real environment, and therefore allows us to decide when to deploy our learned policy.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
Augmenting Flight Training with AI to Efficiently Train Pilots
Oct 13, 2022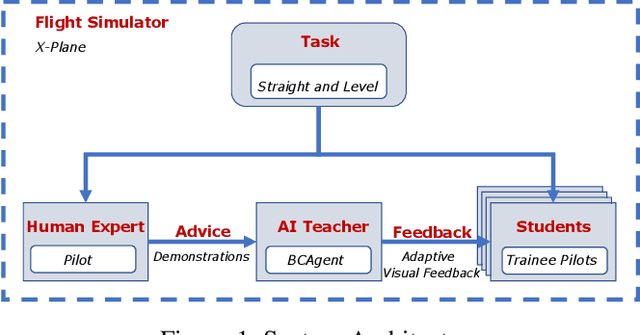
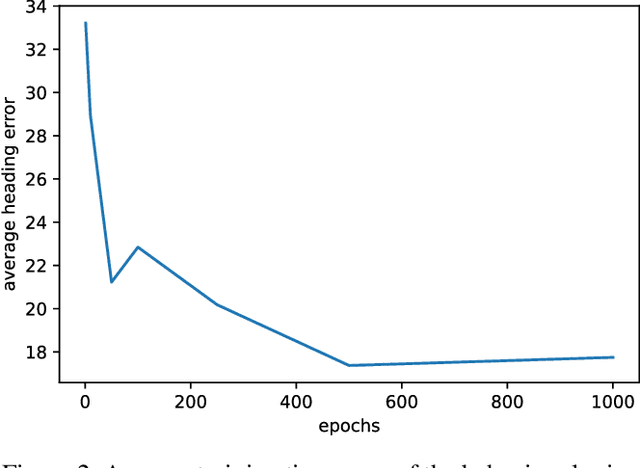

We propose an AI-based pilot trainer to help students learn how to fly aircraft. First, an AI agent uses behavioral cloning to learn flying maneuvers from qualified flight instructors. Later, the system uses the agent's decisions to detect errors made by students and provide feedback to help students correct their errors. This paper presents an instantiation of the pilot trainer. We focus on teaching straight and level flying maneuvers by automatically providing formative feedback to the human student.
Reinforcement Teaching
Apr 25, 2022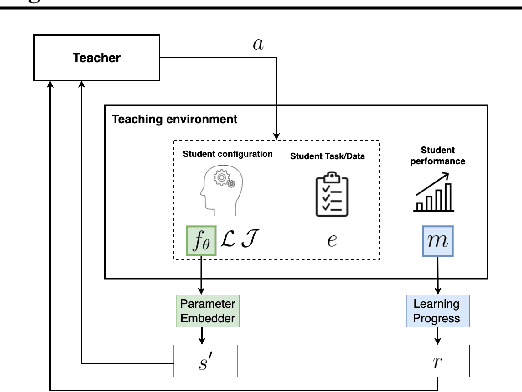

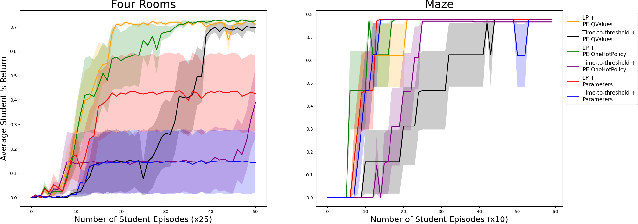
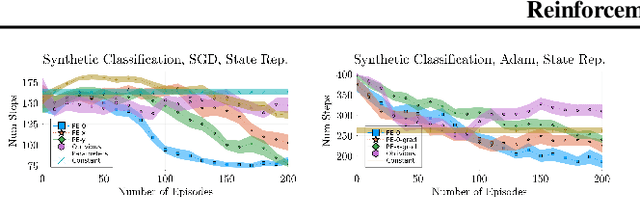
We propose Reinforcement Teaching: a framework for meta-learning in which a teaching policy is learned, through reinforcement, to control a student's learning process. The student's learning process is modelled as a Markov reward process and the teacher, with its action-space, interacts with the induced Markov decision process. We show that, for many learning processes, the student's learnable parameters form a Markov state. To avoid having the teacher learn directly from parameters, we propose the Parameter Embedder that learns a representation of a student's state from its input/output behaviour. Next, we use learning progress to shape the teacher's reward towards maximizing the student's performance. To demonstrate the generality of Reinforcement Teaching, we conducted experiments in which a teacher learns to significantly improve supervised and reinforcement learners by using a combination of learning progress reward and a Parameter Embedded state. These results show that Reinforcement Teaching is not only an expressive framework capable of unifying different approaches, but also provides meta-learning with the plethora of tools from reinforcement learning.
Methodical Advice Collection and Reuse in Deep Reinforcement Learning
Apr 14, 2022
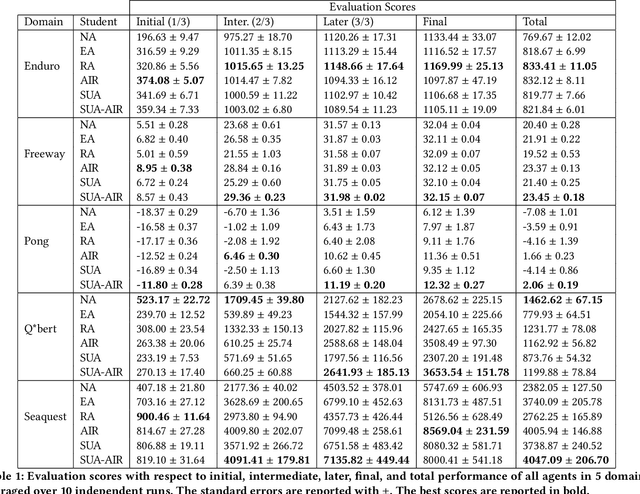
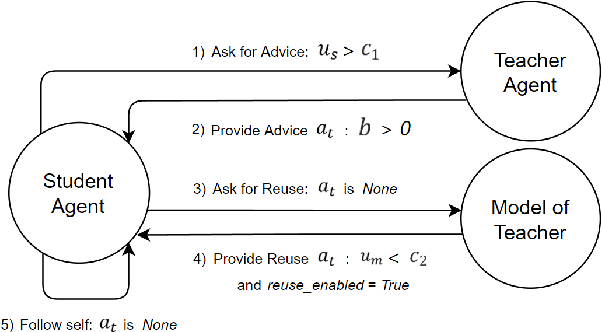
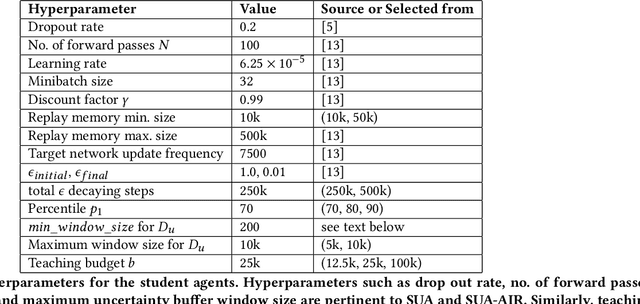
Reinforcement learning (RL) has shown great success in solving many challenging tasks via use of deep neural networks. Although using deep learning for RL brings immense representational power, it also causes a well-known sample-inefficiency problem. This means that the algorithms are data-hungry and require millions of training samples to converge to an adequate policy. One way to combat this issue is to use action advising in a teacher-student framework, where a knowledgeable teacher provides action advice to help the student. This work considers how to better leverage uncertainties about when a student should ask for advice and if the student can model the teacher to ask for less advice. The student could decide to ask for advice when it is uncertain or when both it and its model of the teacher are uncertain. In addition to this investigation, this paper introduces a new method to compute uncertainty for a deep RL agent using a secondary neural network. Our empirical results show that using dual uncertainties to drive advice collection and reuse may improve learning performance across several Atari games.
PMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration
Mar 16, 2022
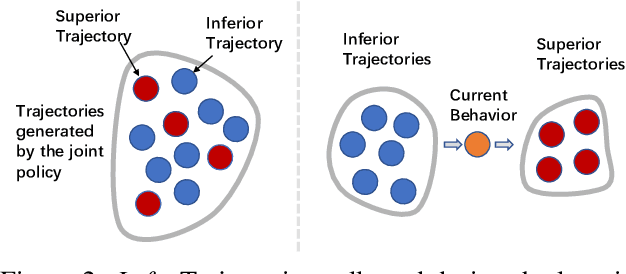
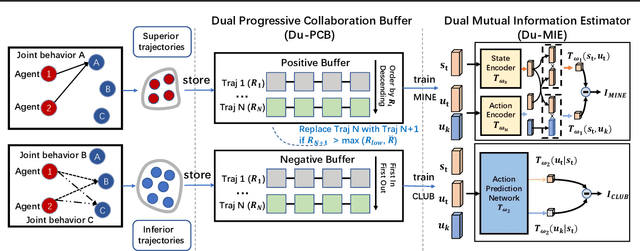
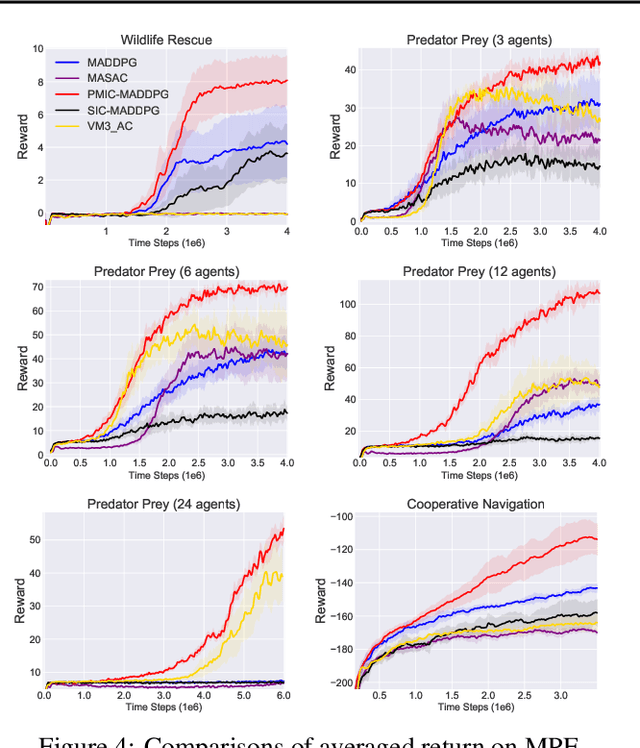
Learning to collaborate is critical in multi-agent reinforcement learning (MARL). A number of previous works promote collaboration by maximizing the correlation of agents' behaviors, which is typically characterised by mutual information (MI) in different forms. However, in this paper, we reveal that strong correlation can emerge from sub-optimal collaborative behaviors, and simply maximizing the MI can, surprisingly, hinder the learning towards better collaboration. To address this issue, we propose a novel MARL framework, called Progressive Mutual Information Collaboration (PMIC), for more effective MI-driven collaboration. In PMIC, we use a new collaboration criterion measured by the MI between global states and joint actions. Based on the criterion, the key idea of PMIC is maximizing the MI associated with superior collaborative behaviors and minimizing the MI associated with inferior ones. The two MI objectives play complementary roles by facilitating learning towards better collaborations while avoiding falling into sub-optimal ones. Specifically, PMIC stores and progressively maintains sets of superior and inferior interaction experiences, from which dual MI neural estimators are established. Experiments on a wide range of MARL benchmarks show the superior performance of PMIC compared with other algorithms.
Learning Representations for Pixel-based Control: What Matters and Why?
Nov 15, 2021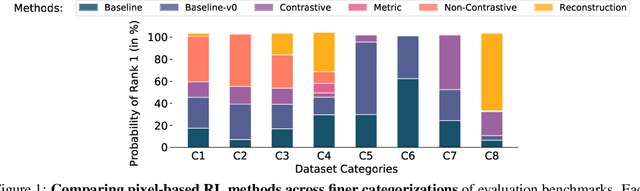
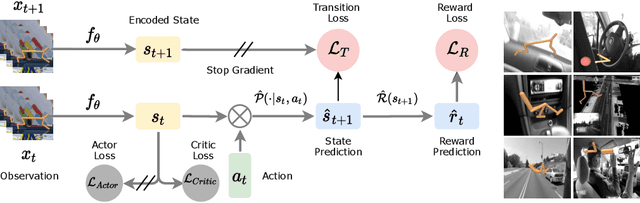
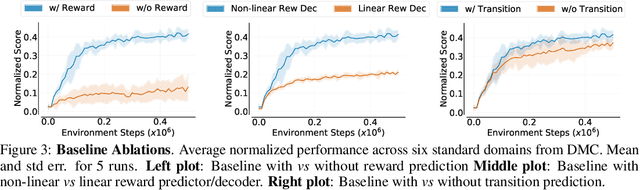

Learning representations for pixel-based control has garnered significant attention recently in reinforcement learning. A wide range of methods have been proposed to enable efficient learning, leading to sample complexities similar to those in the full state setting. However, moving beyond carefully curated pixel data sets (centered crop, appropriate lighting, clear background, etc.) remains challenging. In this paper, we adopt a more difficult setting, incorporating background distractors, as a first step towards addressing this challenge. We present a simple baseline approach that can learn meaningful representations with no metric-based learning, no data augmentations, no world-model learning, and no contrastive learning. We then analyze when and why previously proposed methods are likely to fail or reduce to the same performance as the baseline in this harder setting and why we should think carefully about extending such methods beyond the well curated environments. Our results show that finer categorization of benchmarks on the basis of characteristics like density of reward, planning horizon of the problem, presence of task-irrelevant components, etc., is crucial in evaluating algorithms. Based on these observations, we propose different metrics to consider when evaluating an algorithm on benchmark tasks. We hope such a data-centric view can motivate researchers to rethink representation learning when investigating how to best apply RL to real-world tasks.