 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Alignment Coefficient in Two Acts: From Reward Tuning to Reward Learning
Jan 23, 2026The success of reinforcement learning (RL) is fundamentally tied to having a reward function that accurately reflects the task objective. Yet, designing reward functions is notoriously time-consuming and prone to misspecification. To address this issue, our first goal is to understand how to support RL practitioners in specifying appropriate weights for a reward function. We leverage the Trajectory Alignment Coefficient (TAC), a metric that evaluates how closely a reward function's induced preferences match those of a domain expert. To evaluate whether TAC provides effective support in practice, we conducted a human-subject study in which RL practitioners tuned reward weights for Lunar Lander. We found that providing TAC during reward tuning led participants to produce more performant reward functions and report lower cognitive workload relative to standard tuning without TAC. However, the study also underscored that manual reward design, even with TAC, remains labor-intensive. This limitation motivated our second goal: to learn a reward model that maximizes TAC directly. Specifically, we propose Soft-TAC, a differentiable approximation of TAC that can be used as a loss function to train reward models from human preference data. Validated in the racing simulator Gran Turismo 7, reward models trained using Soft-TAC successfully captured preference-specific objectives, resulting in policies with qualitatively more distinct behaviors than models trained with standard Cross-Entropy loss. This work demonstrates that TAC can serve as both a practical tool for guiding reward tuning and a reward learning objective in complex domains.
Reward Learning through Ranking Mean Squared Error
Jan 15, 2026Reward design remains a significant bottleneck in applying reinforcement learning (RL) to real-world problems. A popular alternative is reward learning, where reward functions are inferred from human feedback rather than manually specified. Recent work has proposed learning reward functions from human feedback in the form of ratings, rather than traditional binary preferences, enabling richer and potentially less cognitively demanding supervision. Building on this paradigm, we introduce a new rating-based RL method, Ranked Return Regression for RL (R4). At its core, R4 employs a novel ranking mean squared error (rMSE) loss, which treats teacher-provided ratings as ordinal targets. Our approach learns from a dataset of trajectory-rating pairs, where each trajectory is labeled with a discrete rating (e.g., "bad," "neutral," "good"). At each training step, we sample a set of trajectories, predict their returns, and rank them using a differentiable sorting operator (soft ranks). We then optimize a mean squared error loss between the resulting soft ranks and the teacher's ratings. Unlike prior rating-based approaches, R4 offers formal guarantees: its solution set is provably minimal and complete under mild assumptions. Empirically, using simulated human feedback, we demonstrate that R4 consistently matches or outperforms existing rating and preference-based RL methods on robotic locomotion benchmarks from OpenAI Gym and the DeepMind Control Suite, while requiring significantly less feedback.
Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Mar 08, 2025



Reinforcement learning agents are fundamentally limited by the quality of the reward functions they learn from, yet reward design is often overlooked under the assumption that a well-defined reward is readily available. However, in practice, designing rewards is difficult, and even when specified, evaluating their correctness is equally problematic: how do we know if a reward function is correctly specified? In our work, we address these challenges by focusing on reward alignment -- assessing whether a reward function accurately encodes the preferences of a human stakeholder. As a concrete measure of reward alignment, we introduce the Trajectory Alignment Coefficient to quantify the similarity between a human stakeholder's ranking of trajectory distributions and those induced by a given reward function. We show that the Trajectory Alignment Coefficient exhibits desirable properties, such as not requiring access to a ground truth reward, invariance to potential-based reward shaping, and applicability to online RL. Additionally, in an 11 -- person user study of RL practitioners, we found that access to the Trajectory Alignment Coefficient during reward selection led to statistically significant improvements. Compared to relying only on reward functions, our metric reduced cognitive workload by 1.5x, was preferred by 82% of users and increased the success rate of selecting reward functions that produced performant policies by 41%.
Boosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity
Jun 10, 2024



For autonomous agents to successfully integrate into human-centered environments, agents should be able to learn from and adapt to humans in their native settings. Preference-based reinforcement learning (PbRL) is a promising approach that learns reward functions from human preferences. This enables RL agents to adapt their behavior based on human desires. However, humans live in a world full of diverse information, most of which is not relevant to completing a particular task. It becomes essential that agents learn to focus on the subset of task-relevant environment features. Unfortunately, prior work has largely ignored this aspect; primarily focusing on improving PbRL algorithms in standard RL environments that are carefully constructed to contain only task-relevant features. This can result in algorithms that may not effectively transfer to a more noisy real-world setting. To that end, this work proposes R2N (Robust-to-Noise), the first PbRL algorithm that leverages principles of dynamic sparse training to learn robust reward models that can focus on task-relevant features. We study the effectiveness of R2N in the Extremely Noisy Environment setting, an RL problem setting where up to 95% of the state features are irrelevant distractions. In experiments with a simulated teacher, we demonstrate that R2N can adapt the sparse connectivity of its neural networks to focus on task-relevant features, enabling R2N to significantly outperform several state-of-the-art PbRL algorithms in multiple locomotion and control environments.
Leveraging Sub-Optimal Data for Human-in-the-Loop Reinforcement Learning
Apr 30, 2024To create useful reinforcement learning (RL) agents, step zero is to design a suitable reward function that captures the nuances of the task. However, reward engineering can be a difficult and time-consuming process. Instead, human-in-the-loop (HitL) RL allows agents to learn reward functions from human feedback. Despite recent successes, many of the HitL RL methods still require numerous human interactions to learn successful reward functions. To improve the feedback efficiency of HitL RL methods (i.e., require less feedback), this paper introduces Sub-optimal Data Pre-training, SDP, an approach that leverages reward-free, sub-optimal data to improve scalar- and preference-based HitL RL algorithms. In SDP, we start by pseudo-labeling all low-quality data with rewards of zero. Through this process, we obtain free reward labels to pre-train our reward model. This pre-training phase provides the reward model a head start in learning, whereby it can identify that low-quality transitions should have a low reward, all without any actual feedback. Through extensive experiments with a simulated teacher, we demonstrate that SDP can significantly improve or achieve competitive performance with state-of-the-art (SOTA) HitL RL algorithms across nine robotic manipulation and locomotion tasks.
Reinforcement Teaching
Apr 25, 2022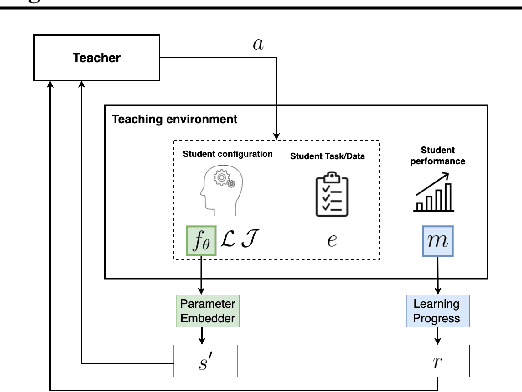

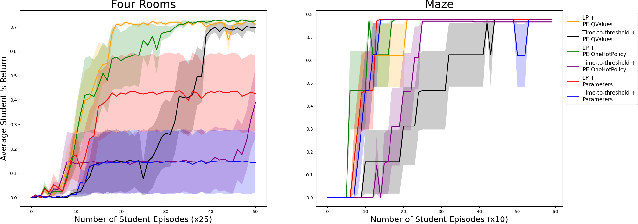
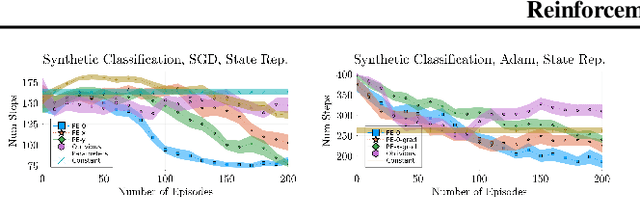
We propose Reinforcement Teaching: a framework for meta-learning in which a teaching policy is learned, through reinforcement, to control a student's learning process. The student's learning process is modelled as a Markov reward process and the teacher, with its action-space, interacts with the induced Markov decision process. We show that, for many learning processes, the student's learnable parameters form a Markov state. To avoid having the teacher learn directly from parameters, we propose the Parameter Embedder that learns a representation of a student's state from its input/output behaviour. Next, we use learning progress to shape the teacher's reward towards maximizing the student's performance. To demonstrate the generality of Reinforcement Teaching, we conducted experiments in which a teacher learns to significantly improve supervised and reinforcement learners by using a combination of learning progress reward and a Parameter Embedded state. These results show that Reinforcement Teaching is not only an expressive framework capable of unifying different approaches, but also provides meta-learning with the plethora of tools from reinforcement learning.