 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the GAP! The Challenges of Scale in Pixel-based Deep Reinforcement Learning
May 23, 2025



Scaling deep reinforcement learning in pixel-based environments presents a significant challenge, often resulting in diminished performance. While recent works have proposed algorithmic and architectural approaches to address this, the underlying cause of the performance drop remains unclear. In this paper, we identify the connection between the output of the encoder (a stack of convolutional layers) and the ensuing dense layers as the main underlying factor limiting scaling capabilities; we denote this connection as the bottleneck, and we demonstrate that previous approaches implicitly target this bottleneck. As a result of our analyses, we present global average pooling as a simple yet effective way of targeting the bottleneck, thereby avoiding the complexity of earlier approaches.
NeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
Don't flatten, tokenize! Unlocking the key to SoftMoE's efficacy in deep RL
Oct 02, 2024



The use of deep neural networks in reinforcement learning (RL) often suffers from performance degradation as model size increases. While soft mixtures of experts (SoftMoEs) have recently shown promise in mitigating this issue for online RL, the reasons behind their effectiveness remain largely unknown. In this work we provide an in-depth analysis identifying the key factors driving this performance gain. We discover the surprising result that tokenizing the encoder output, rather than the use of multiple experts, is what is behind the efficacy of SoftMoEs. Indeed, we demonstrate that even with an appropriately scaled single expert, we are able to maintain the performance gains, largely thanks to tokenization.
Mixtures of Experts Unlock Parameter Scaling for Deep RL
Feb 13, 2024



The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.
Continual Learning with Dynamic Sparse Training: Exploring Algorithms for Effective Model Updates
Aug 28, 2023



Continual learning (CL) refers to the ability of an intelligent system to sequentially acquire and retain knowledge from a stream of data with as little computational overhead as possible. To this end; regularization, replay, architecture, and parameter isolation approaches were introduced to the literature. Parameter isolation using a sparse network which enables to allocate distinct parts of the neural network to different tasks and also allows to share of parameters between tasks if they are similar. Dynamic Sparse Training (DST) is a prominent way to find these sparse networks and isolate them for each task. This paper is the first empirical study investigating the effect of different DST components under the CL paradigm to fill a critical research gap and shed light on the optimal configuration of DST for CL if it exists. Therefore, we perform a comprehensive study in which we investigate various DST components to find the best topology per task on well-known CIFAR100 and miniImageNet benchmarks in a task-incremental CL setup since our primary focus is to evaluate the performance of various DST criteria, rather than the process of mask selection. We found that, at a low sparsity level, Erdos-Renyi Kernel (ERK) initialization utilizes the backbone more efficiently and allows to effectively learn increments of tasks. At a high sparsity level, however, uniform initialization demonstrates more reliable and robust performance. In terms of growth strategy; performance is dependent on the defined initialization strategy, and the extent of sparsity. Finally, adaptivity within DST components is a promising way for better continual learners.
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
Feb 24, 2023



In this work we identify the dormant neuron phenomenon in deep reinforcement learning, where an agent's network suffers from an increasing number of inactive neurons, thereby affecting network expressivity. We demonstrate the presence of this phenomenon across a variety of algorithms and environments, and highlight its effect on learning. To address this issue, we propose a simple and effective method (ReDo) that Recycles Dormant neurons throughout training. Our experiments demonstrate that ReDo maintains the expressive power of networks by reducing the number of dormant neurons and results in improved performance.
Automatic Noise Filtering with Dynamic Sparse Training in Deep Reinforcement Learning
Feb 13, 2023Tomorrow's robots will need to distinguish useful information from noise when performing different tasks. A household robot for instance may continuously receive a plethora of information about the home, but needs to focus on just a small subset to successfully execute its current chore. Filtering distracting inputs that contain irrelevant data has received little attention in the reinforcement learning literature. To start resolving this, we formulate a problem setting in reinforcement learning called the $\textit{extremely noisy environment}$ (ENE), where up to $99\%$ of the input features are pure noise. Agents need to detect which features provide task-relevant information about the state of the environment. Consequently, we propose a new method termed $\textit{Automatic Noise Filtering}$ (ANF), which uses the principles of dynamic sparse training in synergy with various deep reinforcement learning algorithms. The sparse input layer learns to focus its connectivity on task-relevant features, such that ANF-SAC and ANF-TD3 outperform standard SAC and TD3 by a large margin, while using up to $95\%$ fewer weights. Furthermore, we devise a transfer learning setting for ENEs, by permuting all features of the environment after 1M timesteps to simulate the fact that other information sources can become relevant as the world evolves. Again, ANF surpasses the baselines in final performance and sample complexity. Our code is available at https://github.com/bramgrooten/automatic-noise-filtering
Where to Pay Attention in Sparse Training for Feature Selection?
Nov 26, 2022



A new line of research for feature selection based on neural networks has recently emerged. Despite its superiority to classical methods, it requires many training iterations to converge and detect informative features. The computational time becomes prohibitively long for datasets with a large number of samples or a very high dimensional feature space. In this paper, we present a new efficient unsupervised method for feature selection based on sparse autoencoders. In particular, we propose a new sparse training algorithm that optimizes a model's sparse topology during training to pay attention to informative features quickly. The attention-based adaptation of the sparse topology enables fast detection of informative features after a few training iterations. We performed extensive experiments on 10 datasets of different types, including image, speech, text, artificial, and biological. They cover a wide range of characteristics, such as low and high-dimensional feature spaces, and few and large training samples. Our proposed approach outperforms the state-of-the-art methods in terms of selecting informative features while reducing training iterations and computational costs substantially. Moreover, the experiments show the robustness of our method in extremely noisy environments.
Addressing the Stability-Plasticity Dilemma via Knowledge-Aware Continual Learning
Oct 11, 2021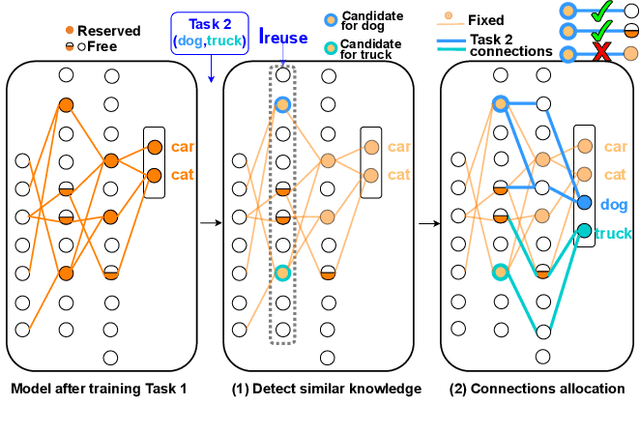

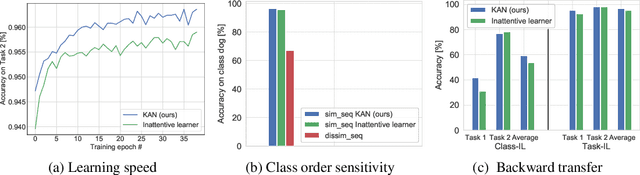
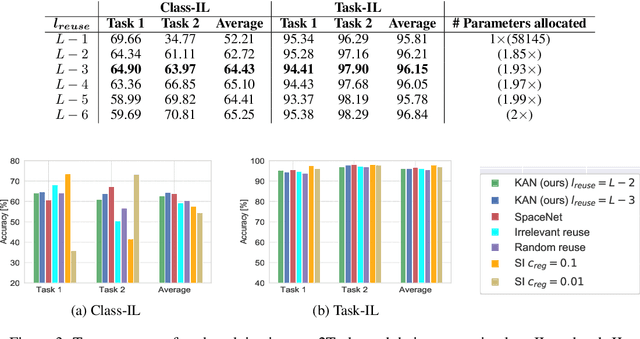
Continual learning agents should incrementally learn a sequence of tasks while satisfying two main desiderata: accumulating on previous knowledge without forgetting and transferring previous relevant knowledge to help in future learning. Existing research largely focuses on alleviating the catastrophic forgetting problem. There, an agent is altered to prevent forgetting based solely on previous tasks. This hinders the balance between preventing forgetting and maximizing the forward transfer. In response to this, we investigate the stability-plasticity dilemma to determine which model components are eligible to be reused, added, fixed, or updated to achieve this balance. We address the class incremental learning scenario where the agent is prone to ambiguities between old and new classes. With our proposed Knowledge-Aware contiNual learner (KAN), we demonstrate that considering the semantic similarity between old and new classes helps in achieving this balance. We show that being aware of existing knowledge helps in: (1) increasing the forward transfer from similar knowledge, (2) reducing the required capacity by leveraging existing knowledge, (3) protecting dissimilar knowledge, and (4) increasing robustness to the class order in the sequence. We evaluated sequences of similar tasks, dissimilar tasks, and a mix of both constructed from the two commonly used benchmarks for class-incremental learning; CIFAR-10 and CIFAR-100.
FreeTickets: Accurate, Robust and Efficient Deep Ensemble by Training with Dynamic Sparsity
Jun 28, 2021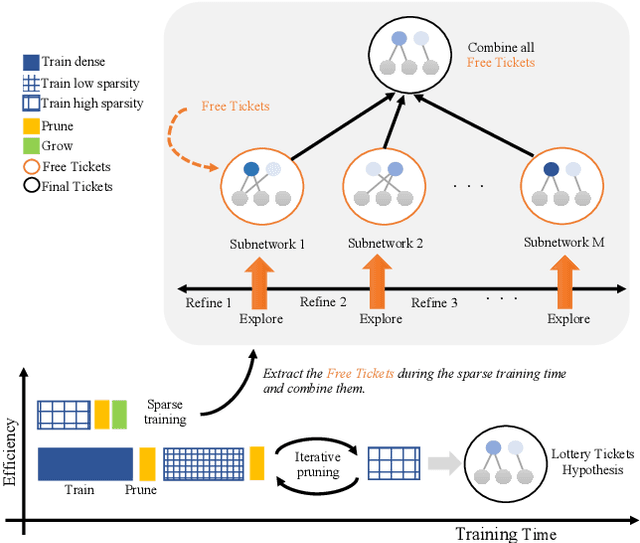
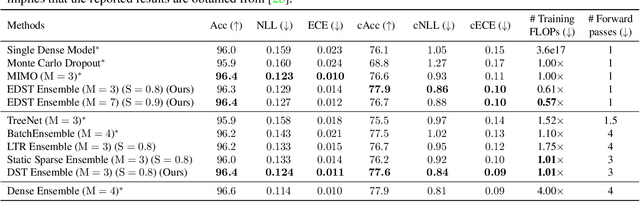
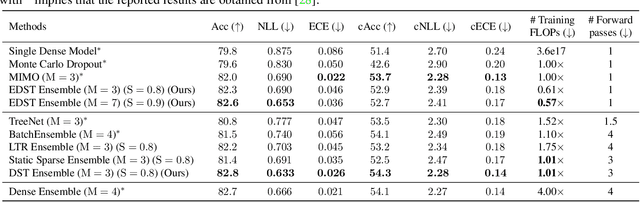
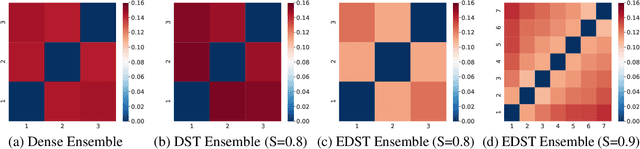
Recent works on sparse neural networks have demonstrated that it is possible to train a sparse network in isolation to match the performance of the corresponding dense networks with a fraction of parameters. However, the identification of these performant sparse neural networks (winning tickets) either involves a costly iterative train-prune-retrain process (e.g., Lottery Ticket Hypothesis) or an over-extended sparse training time (e.g., Training with Dynamic Sparsity), both of which would raise financial and environmental concerns. In this work, we attempt to address this cost-reducing problem by introducing the FreeTickets concept, as the first solution which can boost the performance of sparse convolutional neural networks over their dense network equivalents by a large margin, while using for complete training only a fraction of the computational resources required by the latter. Concretely, we instantiate the FreeTickets concept, by proposing two novel efficient ensemble methods with dynamic sparsity, which yield in one shot many diverse and accurate tickets "for free" during the sparse training process. The combination of these free tickets into an ensemble demonstrates a significant improvement in accuracy, uncertainty estimation, robustness, and efficiency over the corresponding dense (ensemble) networks. Our results provide new insights into the strength of sparse neural networks and suggest that the benefits of sparsity go way beyond the usual training/inference expected efficiency. We will release all codes in https://github.com/Shiweiliuiiiiiii/FreeTickets.