 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
Jan 29, 2026Frontier large language models (LLMs) excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.
Simplifying Bayesian Optimization Via In-Context Direct Optimum Sampling
May 29, 2025



The optimization of expensive black-box functions is ubiquitous in science and engineering. A common solution to this problem is Bayesian optimization (BO), which is generally comprised of two components: (i) a surrogate model and (ii) an acquisition function, which generally require expensive re-training and optimization steps at each iteration, respectively. Although recent work enabled in-context surrogate models that do not require re-training, virtually all existing BO methods still require acquisition function maximization to select the next observation, which introduces many knobs to tune, such as Monte Carlo samplers and multi-start optimizers. In this work, we propose a completely in-context, zero-shot solution for BO that does not require surrogate fitting or acquisition function optimization. This is done by using a pre-trained deep generative model to directly sample from the posterior over the optimum point. We show that this process is equivalent to Thompson sampling and demonstrate the capabilities and cost-effectiveness of our foundation model on a suite of real-world benchmarks. We achieve an efficiency gain of more than 35x in terms of wall-clock time when compared with Gaussian process-based BO, enabling efficient parallel and distributed BO, e.g., for high-throughput optimization.
Learning to Negotiate via Voluntary Commitment
Mar 05, 2025



The partial alignment and conflict of autonomous agents lead to mixed-motive scenarios in many real-world applications. However, agents may fail to cooperate in practice even when cooperation yields a better outcome. One well known reason for this failure comes from non-credible commitments. To facilitate commitments among agents for better cooperation, we define Markov Commitment Games (MCGs), a variant of commitment games, where agents can voluntarily commit to their proposed future plans. Based on MCGs, we propose a learnable commitment protocol via policy gradients. We further propose incentive-compatible learning to accelerate convergence to equilibria with better social welfare. Experimental results in challenging mixed-motive tasks demonstrate faster empirical convergence and higher returns for our method compared with its counterparts. Our code is available at https://github.com/shuhui-zhu/DCL.
A Survey of Inverse Constrained Reinforcement Learning: Definitions, Progress and Challenges
Sep 11, 2024



Inverse Constrained Reinforcement Learning (ICRL) is the task of inferring the implicit constraints followed by expert agents from their demonstration data. As an emerging research topic, ICRL has received considerable attention in recent years. This article presents a categorical survey of the latest advances in ICRL. It serves as a comprehensive reference for machine learning researchers and practitioners, as well as starters seeking to comprehend the definitions, advancements, and important challenges in ICRL. We begin by formally defining the problem and outlining the algorithmic framework that facilitates constraint inference across various scenarios. These include deterministic or stochastic environments, environments with limited demonstrations, and multiple agents. For each context, we illustrate the critical challenges and introduce a series of fundamental methods to tackle these issues. This survey encompasses discrete, virtual, and realistic environments for evaluating ICRL agents. We also delve into the most pertinent applications of ICRL, such as autonomous driving, robot control, and sports analytics. To stimulate continuing research, we conclude the survey with a discussion of key unresolved questions in ICRL that can effectively foster a bridge between theoretical understanding and practical industrial applications.
Confidence Aware Inverse Constrained Reinforcement Learning
Jun 24, 2024



In coming up with solutions to real-world problems, humans implicitly adhere to constraints that are too numerous and complex to be specified completely. However, reinforcement learning (RL) agents need these constraints to learn the correct optimal policy in these settings. The field of Inverse Constraint Reinforcement Learning (ICRL) deals with this problem and provides algorithms that aim to estimate the constraints from expert demonstrations collected offline. Practitioners prefer to know a measure of confidence in the estimated constraints, before deciding to use these constraints, which allows them to only use the constraints that satisfy a desired level of confidence. However, prior works do not allow users to provide the desired level of confidence for the inferred constraints. This work provides a principled ICRL method that can take a confidence level with a set of expert demonstrations and outputs a constraint that is at least as constraining as the true underlying constraint with the desired level of confidence. Further, unlike previous methods, this method allows a user to know if the number of expert trajectories is insufficient to learn a constraint with a desired level of confidence, and therefore collect more expert trajectories as required to simultaneously learn constraints with the desired level of confidence and a policy that achieves the desired level of performance.
How Useful is Intermittent, Asynchronous Expert Feedback for Bayesian Optimization?
Jun 10, 2024



Bayesian optimization (BO) is an integral part of automated scientific discovery -- the so-called self-driving lab -- where human inputs are ideally minimal or at least non-blocking. However, scientists often have strong intuition, and thus human feedback is still useful. Nevertheless, prior works in enhancing BO with expert feedback, such as by incorporating it in an offline or online but blocking (arrives at each BO iteration) manner, are incompatible with the spirit of self-driving labs. In this work, we study whether a small amount of randomly arriving expert feedback that is being incorporated in a non-blocking manner can improve a BO campaign. To this end, we run an additional, independent computing thread on top of the BO loop to handle the feedback-gathering process. The gathered feedback is used to learn a Bayesian preference model that can readily be incorporated into the BO thread, to steer its exploration-exploitation process. Experiments on toy and chemistry datasets suggest that even just a few intermittent, asynchronous expert feedback can be useful for improving or constraining BO. This can especially be useful for its implication in improving self-driving labs, e.g. making them more data-efficient and less costly.
ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
May 23, 2023



This paper provides a simulated laboratory for making use of Reinforcement Learning (RL) for chemical discovery. Since RL is fairly data intensive, training agents `on-the-fly' by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, based on the standard Open AI Gym template. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Learning from Multiple Independent Advisors in Multi-agent Reinforcement Learning
Jan 26, 2023



Multi-agent reinforcement learning typically suffers from the problem of sample inefficiency, where learning suitable policies involves the use of many data samples. Learning from external demonstrators is a possible solution that mitigates this problem. However, most prior approaches in this area assume the presence of a single demonstrator. Leveraging multiple knowledge sources (i.e., advisors) with expertise in distinct aspects of the environment could substantially speed up learning in complex environments. This paper considers the problem of simultaneously learning from multiple independent advisors in multi-agent reinforcement learning. The approach leverages a two-level Q-learning architecture, and extends this framework from single-agent to multi-agent settings. We provide principled algorithms that incorporate a set of advisors by both evaluating the advisors at each state and subsequently using the advisors to guide action selection. We also provide theoretical convergence and sample complexity guarantees. Experimentally, we validate our approach in three different test-beds and show that our algorithms give better performances than baselines, can effectively integrate the combined expertise of different advisors, and learn to ignore bad advice.
Multi-Agent Advisor Q-Learning
Nov 08, 2021
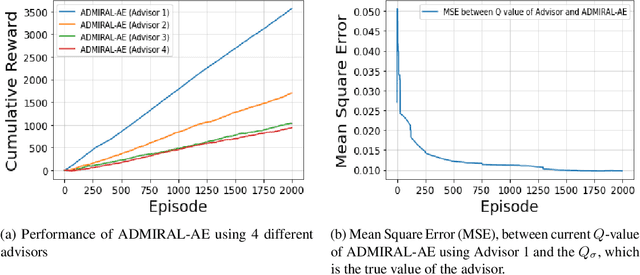
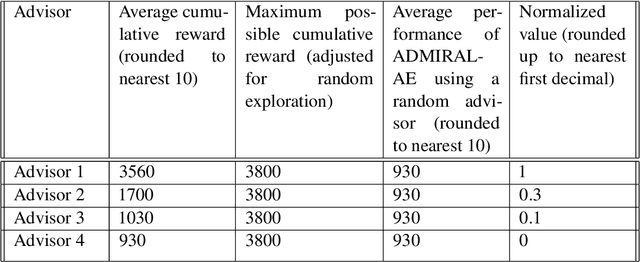
In the last decade, there have been significant advances in multi-agent reinforcement learning (MARL) but there are still numerous challenges, such as high sample complexity and slow convergence to stable policies, that need to be overcome before wide-spread deployment is possible. However, many real-world environments already, in practice, deploy sub-optimal or heuristic approaches for generating policies. An interesting question which arises is how to best use such approaches as advisors to help improve reinforcement learning in multi-agent domains. In this paper, we provide a principled framework for incorporating action recommendations from online sub-optimal advisors in multi-agent settings. We describe the problem of ADvising Multiple Intelligent Reinforcement Agents (ADMIRAL) in nonrestrictive general-sum stochastic game environments and present two novel Q-learning based algorithms: ADMIRAL - Decision Making (ADMIRAL-DM) and ADMIRAL - Advisor Evaluation (ADMIRAL-AE), which allow us to improve learning by appropriately incorporating advice from an advisor (ADMIRAL-DM), and evaluate the effectiveness of an advisor (ADMIRAL-AE). We analyze the algorithms theoretically and provide fixed-point guarantees regarding their learning in general-sum stochastic games. Furthermore, extensive experiments illustrate that these algorithms: can be used in a variety of environments, have performances that compare favourably to other related baselines, can scale to large state-action spaces, and are robust to poor advice from advisors.
Investigation of Independent Reinforcement Learning Algorithms in Multi-Agent Environments
Nov 01, 2021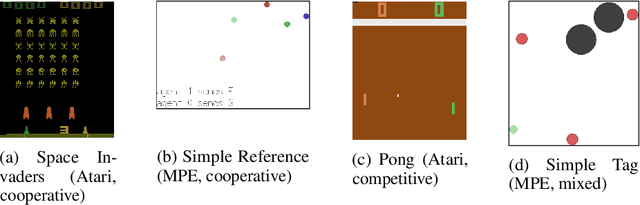

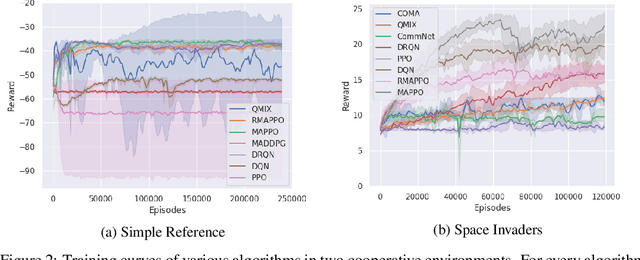
Independent reinforcement learning algorithms have no theoretical guarantees for finding the best policy in multi-agent settings. However, in practice, prior works have reported good performance with independent algorithms in some domains and bad performance in others. Moreover, a comprehensive study of the strengths and weaknesses of independent algorithms is lacking in the literature. In this paper, we carry out an empirical comparison of the performance of independent algorithms on four PettingZoo environments that span the three main categories of multi-agent environments, i.e., cooperative, competitive, and mixed. We show that in fully-observable environments, independent algorithms can perform on par with multi-agent algorithms in cooperative and competitive settings. For the mixed environments, we show that agents trained via independent algorithms learn to perform well individually, but fail to learn to cooperate with allies and compete with enemies. We also show that adding recurrence improves the learning of independent algorithms in cooperative partially observable environments.