 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom sunblock to softblock: Analyzing the correlates of neology in published writing and on social media
Feb 13, 2026Living languages are shaped by a host of conflicting internal and external evolutionary pressures. While some of these pressures are universal across languages and cultures, others differ depending on the social and conversational context: language use in newspapers is subject to very different constraints than language use on social media. Prior distributional semantic work on English word emergence (neology) identified two factors correlated with creation of new words by analyzing a corpus consisting primarily of historical published texts (Ryskina et al., 2020, arXiv:2001.07740). Extending this methodology to contextual embeddings in addition to static ones and applying it to a new corpus of Twitter posts, we show that the same findings hold for both domains, though the topic popularity growth factor may contribute less to neology on Twitter than in published writing. We hypothesize that this difference can be explained by the two domains favouring different neologism formation mechanisms.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024



The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022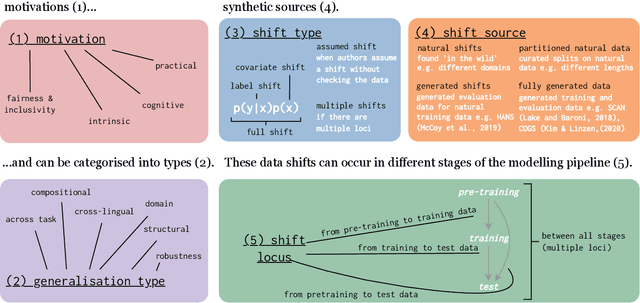
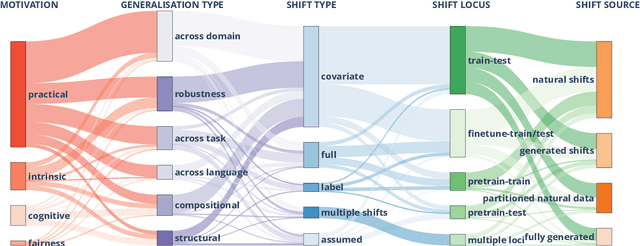
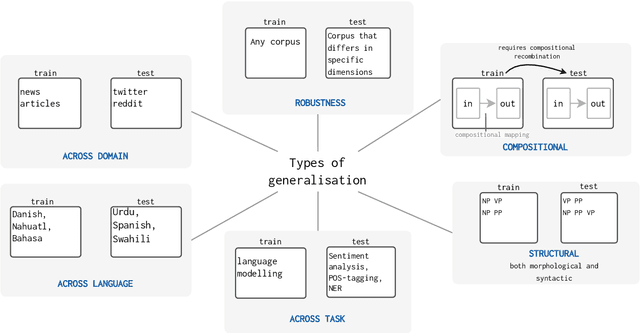

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Two Approaches to Building Collaborative, Task-Oriented Dialog Agents through Self-Play
Sep 20, 2021
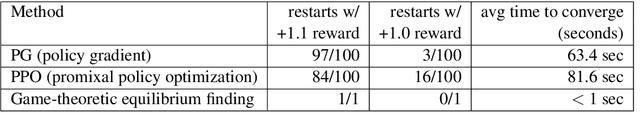
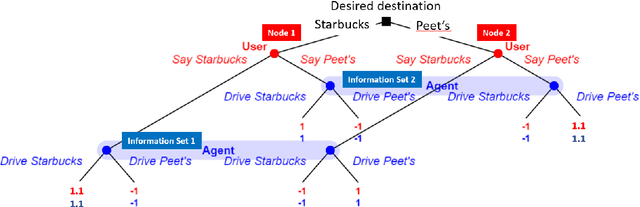
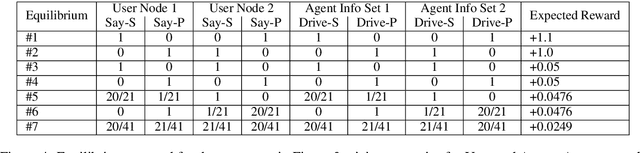
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
Learning Mathematical Properties of Integers
Sep 15, 2021
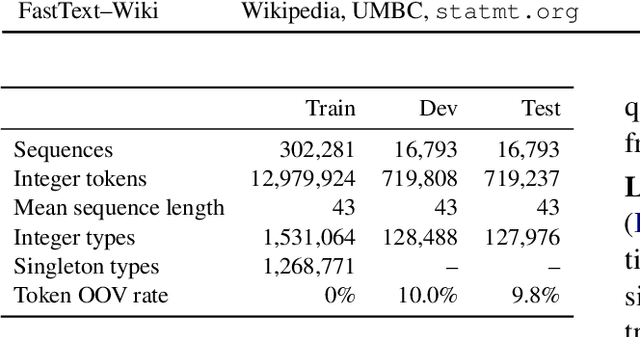
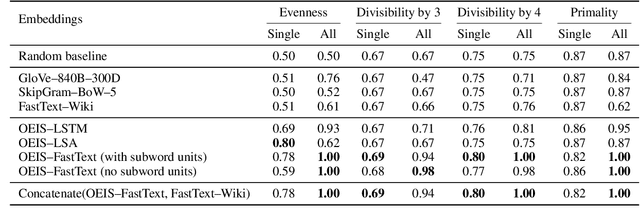
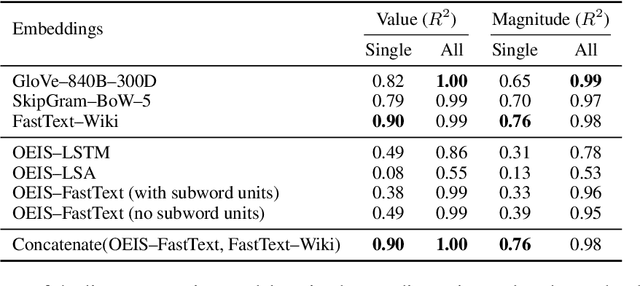
Embedding words in high-dimensional vector spaces has proven valuable in many natural language applications. In this work, we investigate whether similarly-trained embeddings of integers can capture concepts that are useful for mathematical applications. We probe the integer embeddings for mathematical knowledge, apply them to a set of numerical reasoning tasks, and show that by learning the representations from mathematical sequence data, we can substantially improve over number embeddings learned from English text corpora.
Comparative Error Analysis in Neural and Finite-state Models for Unsupervised Character-level Transduction
Jun 24, 2021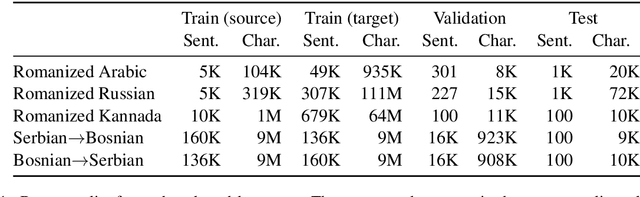

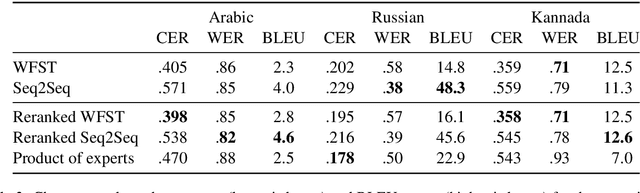

Traditionally, character-level transduction problems have been solved with finite-state models designed to encode structural and linguistic knowledge of the underlying process, whereas recent approaches rely on the power and flexibility of sequence-to-sequence models with attention. Focusing on the less explored unsupervised learning scenario, we compare the two model classes side by side and find that they tend to make different types of errors even when achieving comparable performance. We analyze the distributions of different error classes using two unsupervised tasks as testbeds: converting informally romanized text into the native script of its language (for Russian, Arabic, and Kannada) and translating between a pair of closely related languages (Serbian and Bosnian). Finally, we investigate how combining finite-state and sequence-to-sequence models at decoding time affects the output quantitatively and qualitatively.
NoiseQA: Challenge Set Evaluation for User-Centric Question Answering
Feb 16, 2021
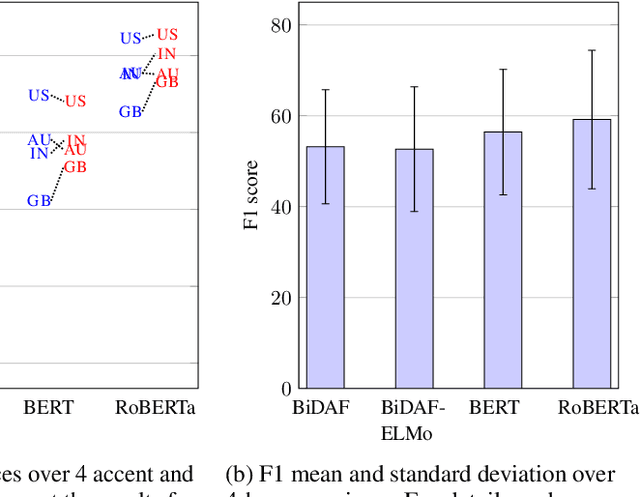

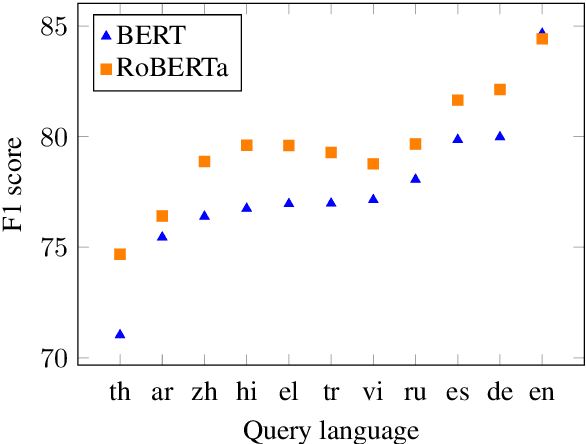
When Question-Answering (QA) systems are deployed in the real world, users query them through a variety of interfaces, such as speaking to voice assistants, typing questions into a search engine, or even translating questions to languages supported by the QA system. While there has been significant community attention devoted to identifying correct answers in passages assuming a perfectly formed question, we show that components in the pipeline that precede an answering engine can introduce varied and considerable sources of error, and performance can degrade substantially based on these upstream noise sources even for powerful pre-trained QA models. We conclude that there is substantial room for progress before QA systems can be effectively deployed, highlight the need for QA evaluation to expand to consider real-world use, and hope that our findings will spur greater community interest in the issues that arise when our systems actually need to be of utility to humans.
Phonetic and Visual Priors for Decipherment of Informal Romanization
May 05, 2020

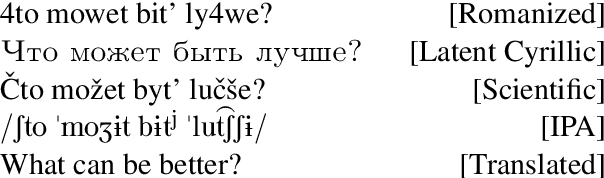
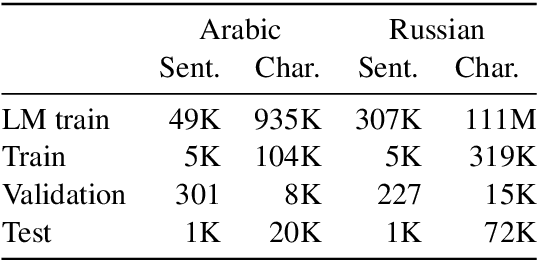
Informal romanization is an idiosyncratic process used by humans in informal digital communication to encode non-Latin script languages into Latin character sets found on common keyboards. Character substitution choices differ between users but have been shown to be governed by the same main principles observed across a variety of languages---namely, character pairs are often associated through phonetic or visual similarity. We propose a noisy-channel WFST cascade model for deciphering the original non-Latin script from observed romanized text in an unsupervised fashion. We train our model directly on romanized data from two languages: Egyptian Arabic and Russian. We demonstrate that adding inductive bias through phonetic and visual priors on character mappings substantially improves the model's performance on both languages, yielding results much closer to the supervised skyline. Finally, we introduce a new dataset of romanized Russian, collected from a Russian social network website and partially annotated for our experiments.