 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Multiplicity and Predictive Arbitrariness in Recidivism Risk Assessment
Jun 01, 2026Prediction tasks over individual futures, which are inherently noisy, often admit multiple similarly accurate models. When these models produce different predictions for the same individual, they raise concerns of arbitrariness in decision-making. How severe can this arbitrariness be, in theory and in practice? How can it be resolved to support high-stakes risk assessment? We address these questions through a study of a machine learning-based decision support system for recidivism risk assessment that has been in use for over 15 years. By translating complex legal rules into an algorithm for labeling post release outcomes (recidivist or non-recidivist), we first construct a dataset of thousands of inmate releases. Using this dataset, we learn interpretable models that improve predictive performance, reduce error-rate disparities between groups, and ensure that rehabilitative progress lowers risk scores. Next, we study predictive multiplicity, by first deriving a tight lower bound on the expected predictive agreement of any finite set of models over a dataset, and then by evaluating the extent to which structural diversity (e.g., different model coefficients) within this set translates to predictive multiplicity (i.e., different predictions for the same individual). Our experiments indicate that the existence of many similarly accurate models with comparable error-rate disparities does not necessarily translate into severe predictive multiplicity. Empirically, similarly performant models can exhibit substantially higher predictive agreement than worst-case theoretical guarantees suggest. We find that a simple policy that assigns each inmate the lowest risk among these models is effective for addressing predictive arbitrariness.
Bound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
Jul 25, 2023

Bias evaluation benchmarks and dataset and model documentation have emerged as central processes for assessing the biases and harms of artificial intelligence (AI) systems. However, these auditing processes have been criticized for their failure to integrate the knowledge of marginalized communities and consider the power dynamics between auditors and the communities. Consequently, modes of bias evaluation have been proposed that engage impacted communities in identifying and assessing the harms of AI systems (e.g., bias bounties). Even so, asking what marginalized communities want from such auditing processes has been neglected. In this paper, we ask queer communities for their positions on, and desires from, auditing processes. To this end, we organized a participatory workshop to critique and redesign bias bounties from queer perspectives. We found that when given space, the scope of feedback from workshop participants goes far beyond what bias bounties afford, with participants questioning the ownership, incentives, and efficacy of bounties. We conclude by advocating for community ownership of bounties and complementing bounties with participatory processes (e.g., co-creation).
* To appear at AIES 2023
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Diagnosing Web Data of ICTs to Provide Focused Assistance in Agricultural Adoptions
Oct 29, 2021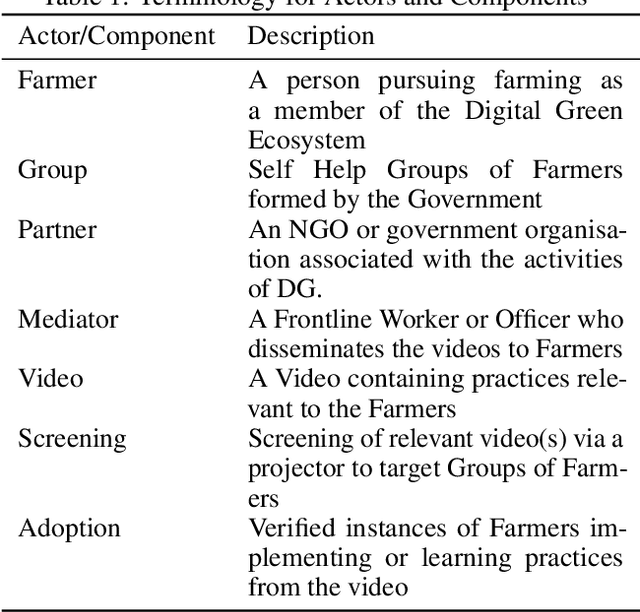


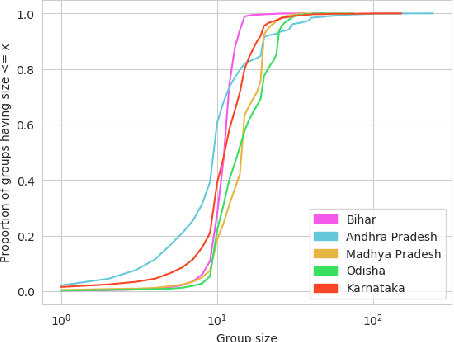
The past decade has witnessed a rapid increase in technology ownership across rural areas of India, signifying the potential for ICT initiatives to empower rural households. In our work, we focus on the web infrastructure of one such ICT - Digital Green that started in 2008. Following a participatory approach for content production, Digital Green disseminates instructional agricultural videos to smallholder farmers via human mediators to improve the adoption of farming practices. Their web-based data tracker, CoCo, captures data related to these processes, storing the attendance and adoption logs of over 2.3 million farmers across three continents and twelve countries. Using this data, we model the components of the Digital Green ecosystem involving the past attendance-adoption behaviours of farmers, the content of the videos screened to them and their demographic features across five states in India. We use statistical tests to identify different factors which distinguish farmers with higher adoption rates to understand why they adopt more than others. Our research finds that farmers with higher adoption rates adopt videos of shorter duration and belong to smaller villages. The co-attendance and co-adoption networks of farmers indicate that they greatly benefit from past adopters of a video from their village and group when it comes to adopting practices from the same video. Following our analysis, we model the adoption of practices from a video as a prediction problem to identify and assist farmers who might face challenges in adoption in each of the five states. We experiment with different model architectures and achieve macro-f1 scores ranging from 79% to 89% using a Random Forest classifier. Finally, we measure the importance of different features using SHAP values and provide implications for improving the adoption rates of nearly a million farmers across five states in India.